Si has buscado un software OCR gratis para reconocer texto en imágenes o documentos escaneados, es muy probable que te hayas encontrado con Tesseract OCR. Se trata de una de las herramientas más conocidas dentro del OCR de código abierto y suele recomendarse a quienes buscan una solución flexible, gratuita y compatible con muchos idiomas.
Ahora bien, que sea popular no significa que sea la mejor opción para todo el mundo. Tesseract OCR encaja especialmente bien en flujos técnicos, automatización y proyectos de desarrollo, pero puede resultar menos cómodo si lo que buscas es una experiencia visual, rápida y con poca configuración. En esta guía verás qué es Tesseract OCR, para qué sirve, cómo instalarlo, cómo usarlo paso a paso, qué idiomas admite, cuáles son sus ventajas y desventajas, y cuándo puede convenirte una alternativa más fácil de usar.
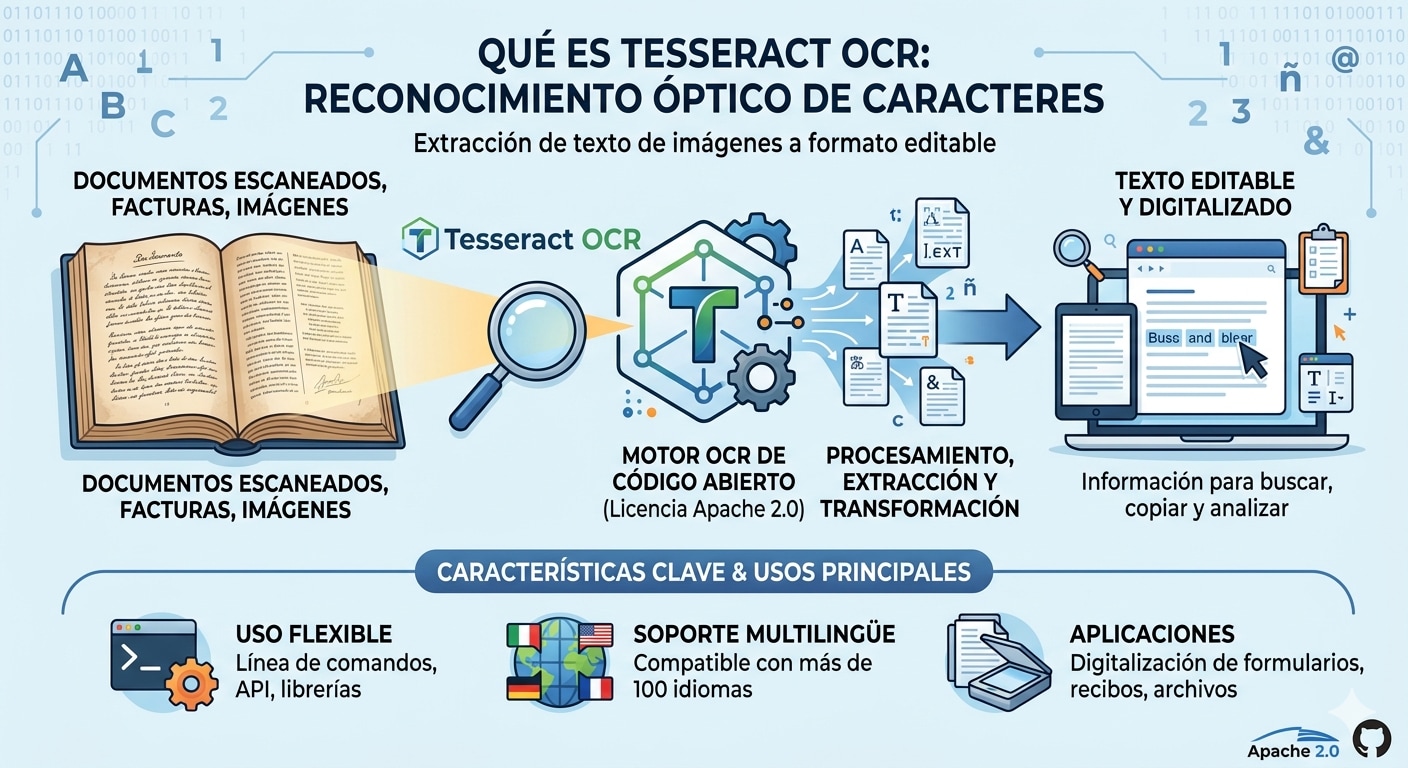
Tesseract OCR es un motor de reconocimiento óptico de caracteres, es decir, un sistema capaz de convertir texto impreso presente en una imagen en texto editable y legible por máquina. Se distribuye como software de código abierto bajo licencia Apache 2.0 y puede utilizarse desde la línea de comandos o integrarse en proyectos mediante API, librerías y wrappers.
En términos sencillos, sirve para extraer texto de una imagen, digitalizar contenido escaneado y transformar documentos visuales en información que se puede buscar, copiar, analizar o reutilizar. Se utiliza en escenarios como facturas, capturas de pantalla, formularios, recibos, archivos históricos y documentos escaneados.
Además, Tesseract OCR destaca por su soporte multilingüe. El proyecto oficial ofrece compatibilidad con más de 100 idiomas, lo que lo convierte en una opción muy versátil para contextos internacionales.
¿Tesseract OCR es gratis?
Sí. Tesseract OCR es completamente gratis y de código abierto. Está disponible bajo licencia Apache 2.0, lo que permite usarlo, modificarlo e integrarlo tanto en proyectos personales como comerciales, siempre dentro de los términos de esa licencia.
Este es uno de los motivos principales de su popularidad: no hay coste de licencia y existe una comunidad activa alrededor del proyecto. Aun así, conviene recordar que “gratis” no siempre significa “más fácil de usar”. En Tesseract, la potencia y la flexibilidad suelen venir acompañadas de una curva de aprendizaje mayor que la de otras herramientas OCR con interfaz visual.
Para qué sirve Tesseract OCR
Tesseract OCR se utiliza para reconocer texto de imágenes y convertirlo en texto editable. Esto incluye desde tareas simples, como extraer texto de una captura, hasta procesos más amplios de OCR para archivos escaneados, indexación documental o automatización de flujos de trabajo.
- Reconocer texto de imágenes en formatos como PNG, JPEG o TIFF
- Extraer texto de una imagen para editarlo o reutilizarlo
- Procesar documentos escaneados dentro de flujos automáticos
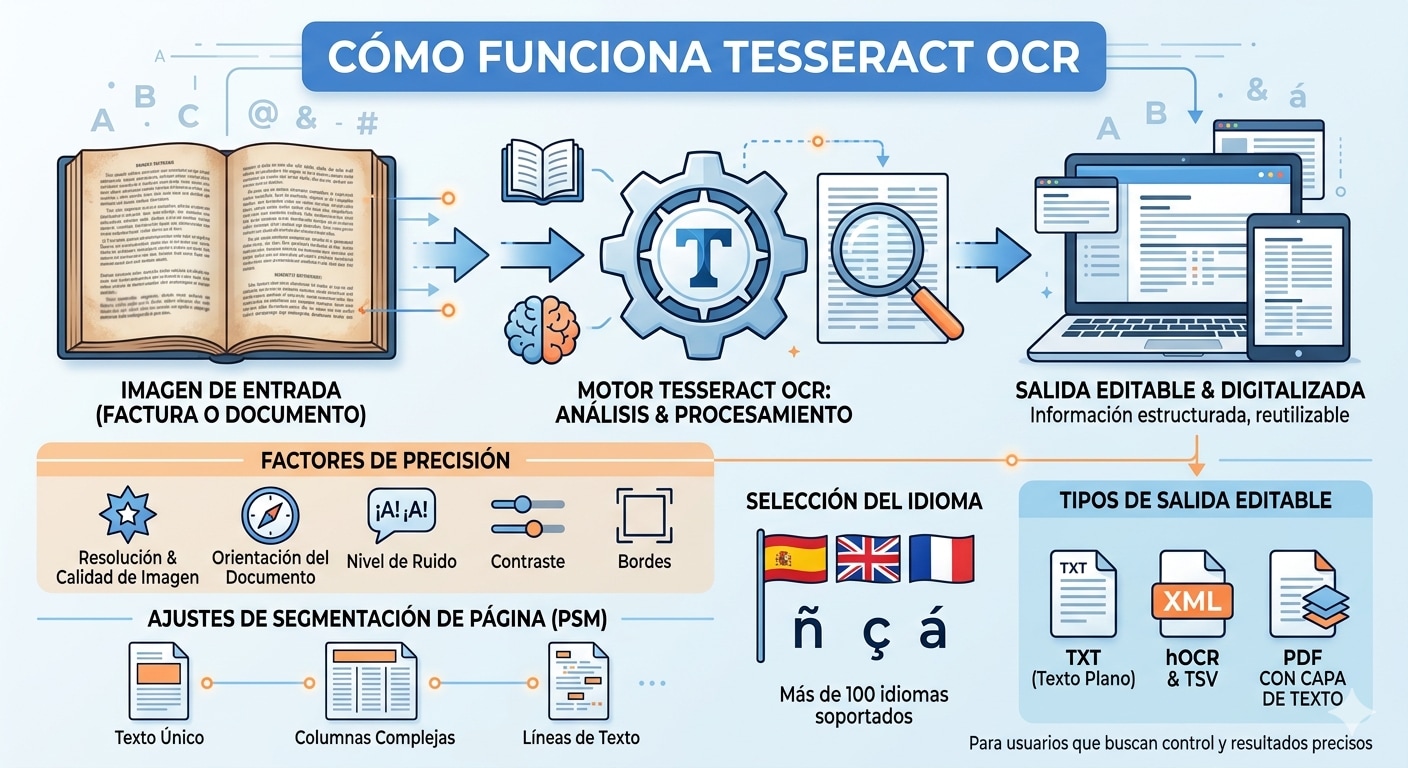
- Generar salidas en texto plano, hOCR, TSV o PDF con capa de texto
- Integrarse con proyectos en C, C++, Python y otros entornos mediante API o wrappers
También es útil cuando necesitas OCR multilingüe o procesamiento por lotes en entornos técnicos. Eso sí, hay una limitación importante que conviene dejar clara: Tesseract no admite PDF como formato de entrada de forma nativa. Si necesitas OCR para un PDF escaneado, lo habitual es convertir primero las páginas a imagen o utilizar una herramienta intermedia. Como salida, sí puede generar PDF con capa de texto reconocible.
Qué debes saber antes de usar Tesseract OCR
Antes de empezar, hay varios puntos que conviene tener claros. El primero es que Tesseract OCR no está pensado como una aplicación de escritorio tradicional. El uso más habitual pasa por la línea de comandos, y eso significa que la experiencia inicial puede resultar menos intuitiva para usuarios no técnicos.
El segundo es que instalar el programa no siempre basta: además del motor OCR, necesitas los archivos de idioma adecuados. Si vas a reconocer texto en español, inglés o varios idiomas a la vez, tendrás que asegurarte de que los paquetes traineddata están instalados y accesibles desde la carpeta tessdata.
El tercero es que la calidad del OCR depende mucho del archivo de entrada. Tesseract funciona mejor con imágenes limpias, rectas, bien contrastadas y cercanas a 300 DPI. Si el documento está torcido, borroso o tiene mucho ruido, la precisión puede caer de forma notable.
- No incluye una interfaz gráfica oficial
- Requiere paquetes de idioma para reconocer cada lengua
- Funciona mejor con imágenes de buena calidad
- Rinde más cuando se usa con algo de configuración y prueba
Cómo funciona Tesseract OCR
El proceso es relativamente directo: Tesseract lee la imagen, analiza la disposición del texto, aplica el modelo lingüístico correspondiente y genera una salida editable. Según cómo lo ejecutes, puedes obtener texto plano, hOCR, TSV o un PDF con capa de texto.
A nivel práctico, lo más importante no es memorizar cada detalle interno, sino entender qué afecta al resultado. La resolución, la orientación del documento, el nivel de ruido, el contraste, los bordes y la selección del idioma influyen directamente en la precisión. Además, Tesseract permite ajustar el modo de segmentación de página para adaptarse mejor a bloques de texto, líneas o diseños concretos.
En documentos con columnas, tablas o estructuras complejas, puede ser necesario hacer pruebas y ajustes. Por eso Tesseract OCR suele rendir mejor en manos de usuarios que no solo quieren “hacer OCR”, sino también controlar cómo se procesa el archivo.
Cómo instalar Tesseract OCR
Instalar Tesseract OCR implica, en general, dos partes: el motor OCR y los archivos de idioma. Muchas veces la búsqueda “descargar Tesseract OCR” lleva a pensar en un único instalador, pero en la práctica también conviene comprobar cómo se gestionan los paquetes lingüísticos y dónde se encuentra la carpeta tessdata.
1. Instalar Tesseract OCR en Windows
En Windows, la documentación oficial enlaza a instaladores mantenidos por UB Mannheim para distintas versiones del proyecto. Tras instalar el programa, es recomendable comprobar que la carpeta de instalación incluye el ejecutable tesseract.exe y que la ruta está bien configurada si quieres usarlo desde CMD o PowerShell.
Si el sistema no reconoce el comando, revisa la variable de entorno Path. Una forma rápida de verificar que todo está correcto es abrir la terminal y ejecutar tesseract --help. Si el comando responde, la instalación básica está lista. Si además vas a trabajar en español u otros idiomas, confirma que los archivos lingüísticos necesarios estén dentro de la carpeta tessdata.
2. Instalar Tesseract OCR en macOS
En macOS, la documentación oficial menciona dos rutas habituales: Homebrew y MacPorts. En ambos casos, el flujo general es parecido: instalar el paquete principal y verificar después si necesitas añadir o revisar los datos de idioma según tu caso de uso.
Si tu objetivo es hacer OCR en español, inglés o varios idiomas combinados, merece la pena confirmar desde el principio dónde se almacenan los archivos lingüísticos para evitar errores posteriores relacionados con tessdata.
3. Instalar Tesseract OCR en Ubuntu o Linux
En Ubuntu y otras distribuciones Linux, Tesseract OCR suele instalarse mediante el gestor de paquetes del sistema. La propia documentación muestra opciones para Ubuntu, Debian, Fedora, openSUSE, Snap, AppImage y otros entornos.
Lo más importante aquí es distinguir entre el motor y los paquetes de idioma. En Linux, los archivos traineddata pueden quedar en rutas distintas según la distribución, así que conviene verificar la carpeta exacta para evitar errores al cargar idiomas.
Cómo usar Tesseract OCR paso a paso
Una vez instalado, el flujo básico de Tesseract OCR es sencillo: preparar el archivo, elegir el idioma, ejecutar el OCR y revisar el resultado. Lo que suele complicar la primera experiencia no es tanto el reconocimiento, sino la configuración inicial y la necesidad de trabajar desde la línea de comandos.
Paso 1.Prepara la imagen o el archivo escaneado.
Usa una imagen clara, recta y con buena resolución. Tesseract funciona mejor con archivos cercanos a 300 DPI. Si trabajas con un PDF escaneado, primero tendrás que convertir sus páginas a imagen o utilizar una herramienta intermedia, ya que Tesseract no acepta PDF como entrada nativa.
Paso 2.Comprueba la configuración inicial.
Antes del primer uso, conviene verificar que el sistema reconoce Tesseract y que la carpeta de idioma está bien ubicada. Un comando como tesseract --help sirve para comprobar si el ejecutable está disponible correctamente.
Paso 3.Selecciona el idioma correcto.
Si quieres reconocer texto en español, tendrás que usar el paquete spa. Si el documento mezcla idiomas, puedes combinar varios códigos lingüísticos en la misma ejecución. Elegir bien el idioma es uno de los factores que más impactan en la precisión del OCR.
Paso 4.Ejecuta el OCR.
La forma más simple de uso consiste en indicar el archivo de entrada y el nombre base del archivo de salida. Por defecto, Tesseract genera texto plano y asume inglés si no se especifica idioma. También puede producir hOCR, TSV o PDF con capa de texto según la configuración utilizada.
- Archivo de entrada
- Idioma o combinación de idiomas
- Formato de salida
- Revisión final del resultado
Paso 5.Revisa y corrige si hace falta.
Después del OCR, compara el texto reconocido con el documento original. Si el resultado contiene errores, texto desordenado o caracteres confusos, lo más efectivo suele ser mejorar la imagen, ajustar la segmentación o revisar la configuración del idioma antes de repetir el proceso.
Idiomas compatibles en Tesseract OCR
Uno de los mayores puntos fuertes es la compatibilidad de Tesseract OCR con más de 100 idiomas y múltiples sistemas de escritura. Entre ellos están español, inglés, francés, alemán, portugués, ruso, árabe, japonés, coreano y chino, entre muchos otros.
Los idiomas no se activan de forma automática: se gestionan mediante archivos traineddata. Eso significa que, además de instalar el motor, debes asegurarte de tener los paquetes lingüísticos correctos en la carpeta tessdata. También es posible combinar varios idiomas en un mismo proceso si el documento lo necesita.
| Idioma | Código habitual |
| Español | spa |
| Inglés | eng |
| Francés | fra |
| Alemán | deu |
| Chino simplificado | chi_sim |
| Chino tradicional | chi_tra |
Si buscas términos como tesseract ocr español, tesseract chinese, tesseract language pack o idiomas de tesseract, la respuesta corta es esta: la compatibilidad es muy amplia, pero el rendimiento depende de instalar los datos correctos y de usar imágenes de calidad razonable.
Ventajas y desventajas de Tesseract OCR
1. Ventajas
- Es gratis y de código abierto
- Admite más de 100 idiomas
- Se integra bien en scripts, automatización y desarrollo
- Permite varias salidas, como texto, hOCR, TSV y PDF
- Es flexible para usuarios técnicos que necesitan control y personalización
Tesseract OCR destaca especialmente cuando se busca un software OCR gratis y extensible. Para equipos técnicos, desarrolladores o proyectos con necesidades concretas, ofrece un nivel de control que otras herramientas más visuales no siempre proporcionan.
2. Desventajas
- Tiene curva de aprendizaje
- No incluye una interfaz gráfica oficial
- No admite PDF como entrada nativa
- La precisión depende mucho de la calidad de la imagen
- En muchos casos requiere preprocesamiento para lograr mejores resultados
- No suele ser la opción más cómoda para usuarios no técnicos
En otras palabras, Tesseract OCR puede ser excelente si sabes lo que haces o si tu flujo justifica esa flexibilidad. Pero si solo quieres una experiencia rápida y visual para OCR de documentos escaneados, es probable que notes sus límites antes de aprovechar sus puntos fuertes.
Problemas comunes de Tesseract OCR y cómo solucionarlos
- Tesseract no reconoce el idioma: Lo más habitual es que falte el archivo traineddata correspondiente o que la ruta de tessdata no esté bien configurada. Revisa si el paquete del idioma está realmente instalado y si Tesseract puede localizarlo.
- Error al cargar tessdata: Este problema suele deberse a una ruta incorrecta o a una variable de entorno mal definida. Como las rutas pueden cambiar según el sistema y la distribución, conviene comprobar la ubicación exacta de la carpeta de datos.
- El texto sale desordenado: Cuando el documento tiene columnas, recortes irregulares o una segmentación compleja, el OCR puede perder estructura. Probar otro modo de segmentación de página suele ayudar, igual que mejorar el recorte o limpiar el diseño antes del reconocimiento.
- La precisión es baja: Normalmente el problema está en la imagen: poca resolución, inclinación, ruido, contraste insuficiente o bordes demasiado grandes. Tesseract funciona mejor con documentos limpios, rectos y cercanos a 300 DPI.
- No detecta bien documentos escaneados: Si el escaneo está torcido, oscuro o con sombras, la segmentación y el reconocimiento se resienten. Enderezar la imagen, reducir ruido y mejorar el contraste puede marcar una gran diferencia.
Alternativas a Tesseract OCR
Aunque Tesseract OCR es una herramienta potente y flexible, no siempre resulta la opción más práctica para todos los usuarios. Su uso suele implicar trabajar con la línea de comandos, instalar paquetes de idioma, revisar rutas como tessdata y ajustar distintos parámetros para obtener buenos resultados. Para desarrolladores y perfiles técnicos esto puede ser una ventaja, pero para muchos usuarios también representa una barrera de entrada innecesaria.
Si lo que buscas es una experiencia más simple, visual y lista para usar, una alternativa como PDFelement puede encajar mejor. En lugar de depender de configuraciones técnicas, te permite realizar OCR y trabajar con documentos PDF desde una interfaz mucho más intuitiva, lo que ahorra tiempo y facilita el proceso, especialmente si tu prioridad es la productividad diaria y no la personalización avanzada.




PDFelement es una opción especialmente interesante para quienes necesitan hacer OCR en documentos escaneados, pero además quieren editar, organizar y reutilizar el contenido sin salir de la misma herramienta. Es decir, no se limita al reconocimiento de texto: también ofrece un entorno más completo para trabajar con archivos PDF de principio a fin.
- OCR con interfaz visual: permite reconocer texto en PDF escaneados e imágenes sin depender de comandos ni configuraciones complejas.
- Edición de PDF: facilita modificar texto, ajustar contenido y trabajar el documento de forma más directa.
- Anotaciones y comentarios: permite resaltar, subrayar, añadir notas y revisar archivos de forma más cómoda.
- Gestión de páginas: ayuda a reorganizar, extraer, eliminar o combinar páginas dentro del mismo PDF.
- Compresión de archivos: resulta útil para reducir el tamaño del documento y compartirlo con más facilidad.
- Conversión de formatos: permite convertir PDF a otros formatos cuando necesitas reutilizar el contenido en distintos contextos.
- Flujo de trabajo más completo: combina OCR, lectura, edición y gestión documental en una sola herramienta.
| Situación | Opción más lógica |
| Quieres OCR gratis y personalizable | Tesseract OCR |
| Necesitas integrar OCR en scripts o automatización | Tesseract OCR |
| Prefieres una herramienta visual y fácil de usar | PDFelement |
| Buscas un flujo completo de OCR + PDF + edición | PDFelement |
En resumen, Tesseract OCR sigue siendo una gran elección para usuarios técnicos que buscan control, flexibilidad y automatización. Pero si prefieres una solución más directa, visual y orientada a la productividad, PDFelement puede ser una alternativa más cómoda para hacer OCR y trabajar con documentos PDF sin complicarte con configuraciones avanzadas.
Conclusión
Tesseract OCR sigue siendo una de las herramientas más relevantes dentro del OCR de código abierto. Es gratis, flexible, compatible con muchos idiomas y muy útil para quienes necesitan automatizar el reconocimiento de texto o integrarlo en proyectos técnicos.
Al mismo tiempo, no es la opción más sencilla para todos los usuarios. Si valoras más una experiencia visual, menos configuración y un flujo más directo para OCR y documentos escaneados, puede tener sentido buscar una alternativa más fácil de usar. Pero si tu prioridad es contar con un motor OCR potente, extensible y sin coste de licencia, Tesseract OCR sigue siendo una apuesta muy sólida.