Reconocer texto en un PDF significa aplicar OCR para convertir un documento escaneado o basado en imagen en un archivo donde el contenido se pueda buscar, copiar o editar. Esto resulta especialmente útil cuando trabajas con facturas, contratos, formularios, libros escaneados o PDF que no permiten seleccionar texto.
En la práctica, no todos los PDF necesitan OCR. Si ya puedes seleccionar y copiar el contenido, el archivo probablemente ya contiene texto digital. Si no puedes buscar palabras, resaltar frases ni copiar contenido, entonces sí conviene aplicar OCR.
En esta guía te explicamos qué significa reconocer texto en un PDF, qué diferencia hay entre un PDF con búsqueda y un PDF editable, qué métodos puedes usar y cómo mejorar la precisión del resultado.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
¿Qué significa reconocer texto en un PDF?
Cuando un PDF proviene de un escaneo, el contenido suele estar guardado como una imagen. A simple vista puedes leerlo sin problema, pero para el sistema sigue siendo una página visual, no texto real. Por eso no puedes buscar una palabra, copiar un párrafo ni corregir errores directamente.
Aquí es donde entra en juego el OCR o reconocimiento óptico de caracteres. Esta tecnología analiza el contenido visual del documento, identifica letras y números y los convierte en texto legible por máquina.
Gracias al OCR, un PDF escaneado deja de ser un archivo “cerrado” y pasa a ser mucho más útil para trabajar con él: puedes buscar palabras clave, copiar fragmentos, reutilizar información y, en muchos casos, editar el contenido.
PDF con búsqueda vs. PDF editable
Al aplicar OCR a un PDF, el resultado no siempre es el mismo. En general, las herramientas OCR suelen ofrecer dos tipos de salida.
1. PDF con búsqueda
En este caso, el documento mantiene su aspecto original, pero se añade una capa de texto invisible sobre la imagen escaneada. Esto permite buscar palabras, seleccionar texto y copiar contenido sin alterar demasiado el diseño visual del archivo.
2. Texto editable
Aquí el objetivo no es solo buscar, sino también modificar el contenido. Dependiendo de la herramienta, el texto reconocido puede exportarse a Word, TXT u otro formato editable. Esta opción es más útil si quieres corregir, reescribir o reutilizar el contenido de forma más activa.
Si solo necesitas consultar o localizar información dentro del PDF, normalmente basta con un PDF con búsqueda. Si quieres cambiar el contenido, conviene elegir una salida editable.
Cómo hacer OCR a un PDF con Wondershare PDFelement
Si buscas una opción de escritorio para reconocer texto en PDF con más control sobre el resultado, Wondershare PDFelement puede servirte para aplicar OCR a documentos escaneados y convertirlos en archivos buscables o editables.
Este método resulta útil cuando trabajas con contratos, facturas, expedientes, libros escaneados o archivos con varias páginas.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Método 1. Aplicar OCR a todo el documento
Paso 1Abrir el PDF
Inicia el programa y carga el archivo PDF que quieres procesar. Puedes abrirlo desde el explorador de archivos o arrastrarlo directamente a la ventana del programa.
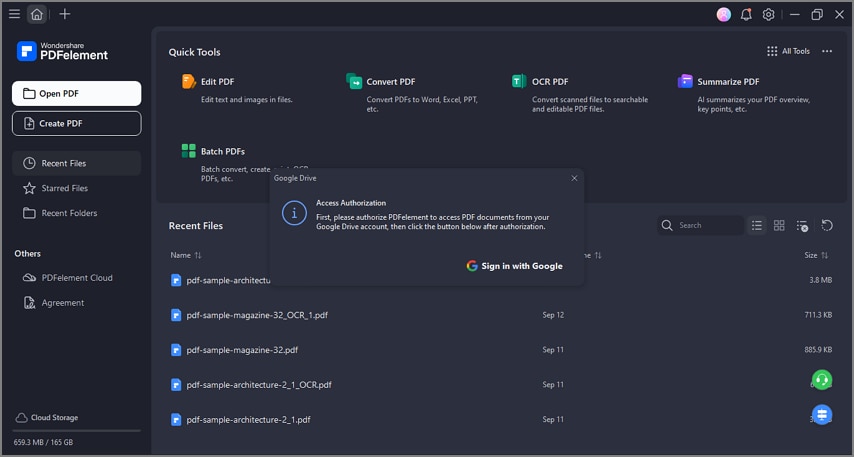
Paso 2Activar OCR
Si el documento está basado en imágenes, el programa puede detectar automáticamente que necesita OCR. También puedes activar esta función manualmente desde las opciones de conversión o reconocimiento.
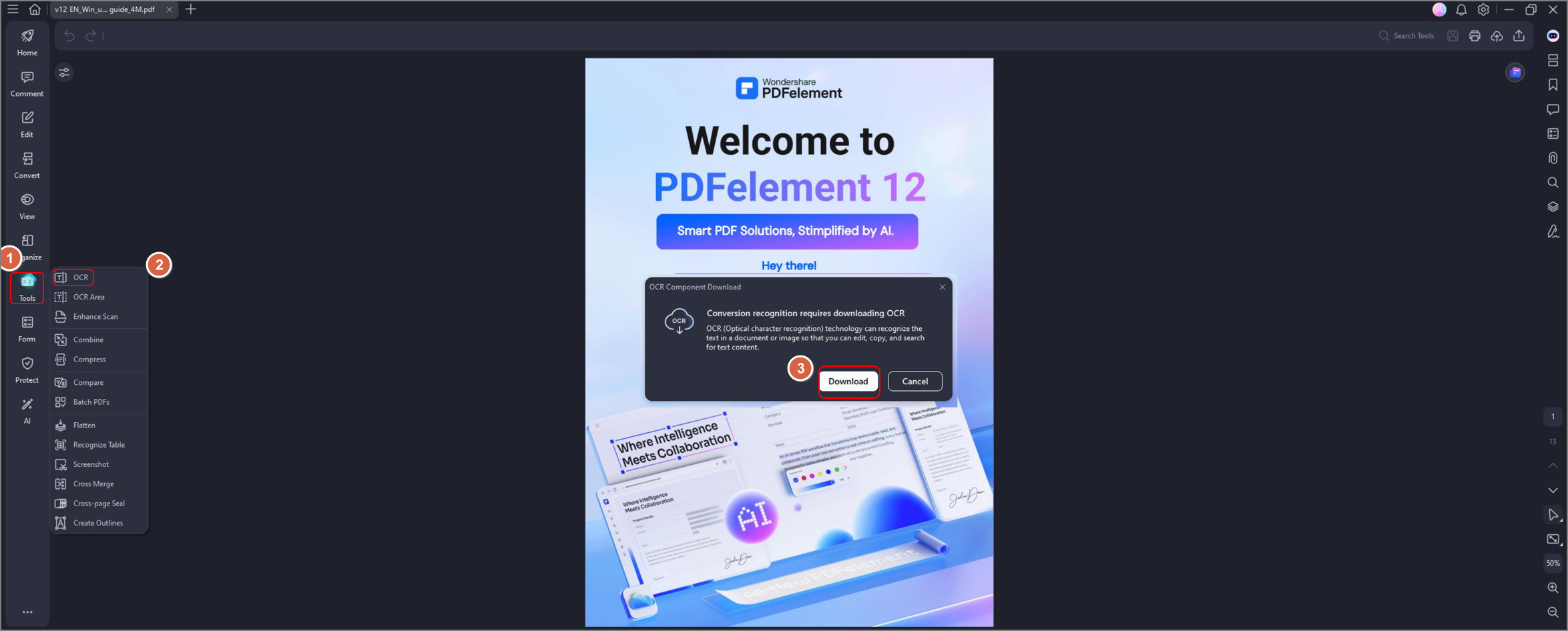
Paso 3Elegir idioma y tipo de salida
Selecciona el idioma correcto del documento y decide si quieres obtener texto editable o un resultado más orientado a búsqueda. Después, inicia el proceso y espera a que el programa reconozca el contenido.
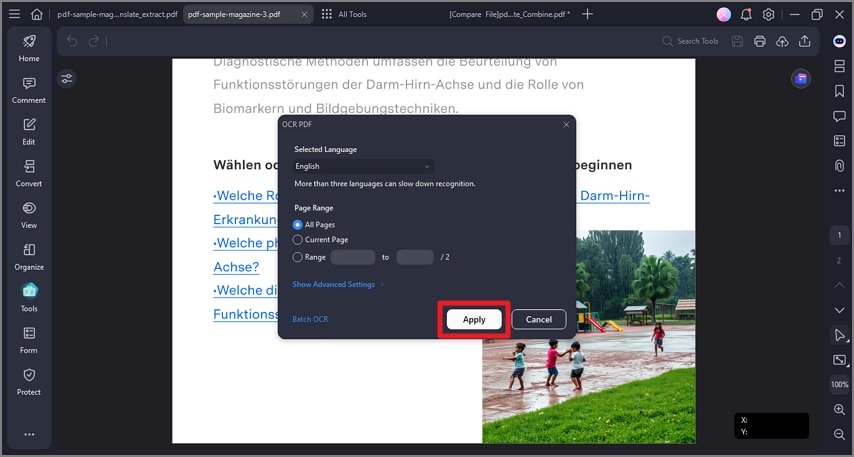
Método 2. Aplicar OCR solo a un área concreta
Si no necesitas reconocer todo el documento, también puedes aplicar OCR solo a una zona determinada, por ejemplo un párrafo, una tabla o un total de factura.
Paso 1Abrir el PDF
Carga el archivo en el programa y accede a la herramienta de OCR.
Paso 2Seleccionar el área
Usa la opción de OCR por área para marcar la región exacta donde quieres reconocer el texto.
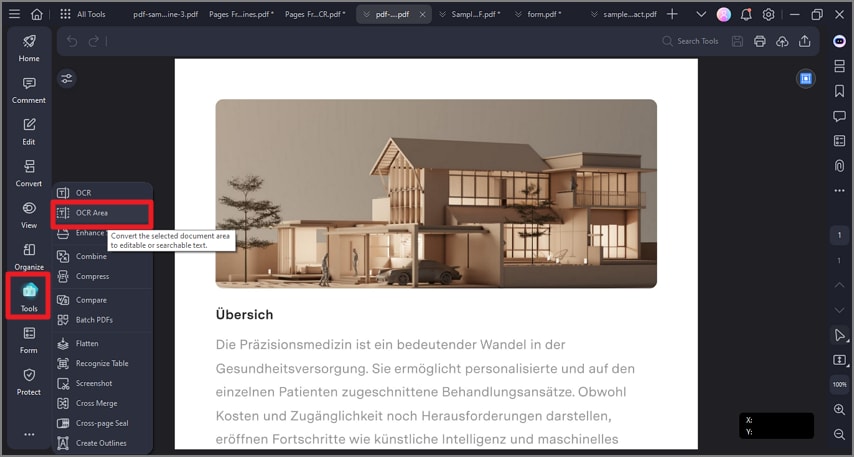
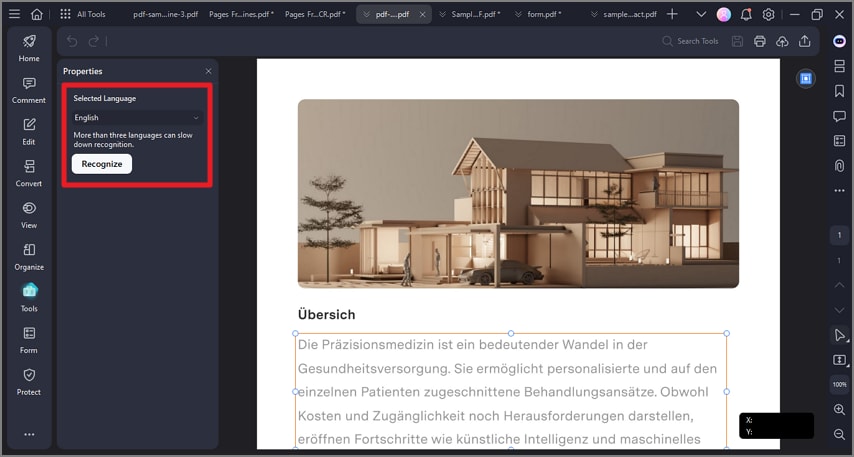
Paso 3Aplicar OCR a la selección
Indica el idioma y el tipo de salida. El programa reconocerá solo el texto de la zona marcada, manteniendo intacto el resto de la página.
Cómo reconocer texto en un PDF escaneado con Adobe Acrobat Pro
Otra opción conocida para hacer OCR en PDF es Adobe Acrobat Pro. Es una alternativa útil si ya trabajas con Acrobat y necesitas convertir un PDF escaneado en un archivo con búsqueda o editable.
Paso 1Abrir el PDF escaneado
Abre el archivo en Adobe Acrobat Pro.
Paso 2Entrar en la herramienta OCR
Busca la opción Escanear y OCR dentro del panel de herramientas.
Paso 3Seleccionar “Reconocer texto”
Elige la opción para reconocer el texto en el archivo actual.
Paso 4Ajustar idioma y salida
Si lo necesitas, cambia el idioma del documento y revisa la configuración del OCR antes de empezar.
Paso 5Ejecutar el reconocimiento
Inicia el proceso y deja que Acrobat convierta el contenido escaneado en texto reconocible.
Cómo hacer OCR en un PDF online gratis
Si no quieres instalar programas o necesitas resolver la tarea desde otro equipo, también puedes hacer OCR en un PDF online. Esta opción resulta útil para conversiones rápidas y puntuales.
Opción 1: Herramientas OCR online
Servicios como HiPDF, Adobe Acrobat Online, PDF24 o Sejda ofrecen OCR desde el navegador.
- Abre una herramienta OCR online de confianza.
- Sube el PDF escaneado.
- Selecciona el idioma del documento.
- Elige el formato de salida si la herramienta lo permite.
- Inicia el proceso y descarga el archivo resultante.
Este tipo de herramientas puede ser suficiente si solo necesitas convertir uno o varios archivos de forma ocasional. Si trabajas con documentos sensibles o con archivos grandes, suele ser más recomendable usar una solución de escritorio.
Cómo usar Google Drive para extraer texto de un PDF
Si buscas una opción gratuita, Google Drive también puede ayudarte a extraer texto de un PDF escaneado a través de Google Docs.
- Sube tu PDF escaneado a Google Drive.
- Haz clic derecho sobre el archivo.
- Selecciona Abrir con > Google Docs.
- Google intentará reconocer el texto y mostrará el contenido extraído debajo del archivo original.
Este método es útil si solo te interesa obtener texto sin formato. Si el PDF contiene tablas, columnas, maquetación compleja o elementos visuales, es normal que parte del formato se pierda.
Consejos para mejorar la precisión del OCR en PDF
La precisión del OCR depende mucho de la calidad del archivo original. Si el documento está borroso, torcido o tiene poco contraste, el resultado será menos fiable.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
- Usa buena resolución: para OCR en PDF, suele ser recomendable trabajar con escaneos de 300 DPI siempre que sea posible.
- Cuida el contraste: el texto oscuro sobre fondo claro da mejores resultados que documentos con sombras o fondos sucios.
- Elige bien el idioma: seleccionar el idioma correcto ayuda a reconocer mejor tildes, signos y caracteres especiales.
- Endereza las páginas: si el PDF proviene de una foto torcida o un escaneo inclinado, conviene corregir la orientación antes de aplicar OCR.
- Evita archivos demasiado deteriorados: manchas, ruido visual, texto muy pequeño o imágenes comprimidas reducen la precisión.
Conclusión
Reconocer texto en un PDF es la clave para convertir un archivo escaneado en un documento mucho más útil. Gracias al OCR, puedes buscar palabras, copiar contenido y, en muchos casos, editar el texto sin tener que reescribirlo manualmente.
Si necesitas más control sobre el formato y el resultado, una herramienta de escritorio suele ser la opción más práctica. Si solo buscas una solución rápida, también puedes recurrir a OCR online o a Google Drive para extraer texto de forma puntual.
La clave está en elegir el método adecuado según el tipo de documento y la calidad del archivo original.