 100% Seguro | Sin anuncios |
100% Seguro | Sin anuncios |
El OCR o Reconocimiento Óptico de Caracteres es el proceso de identificar el texto y otros caracteres dentro de un archivo de imagen y convertirlo en un formato que se pueda editar de forma mecánica o buscar electrónicamente. También conocido como reconocimiento de texto, el OCR es una herramienta comercial muy valiosa. Las empresas lo utilizan para digitalizar y archivar documentos importantes; las escuelas lo utilizan para convertir contenido físico en contenido digital; incluso los particulares pueden utilizar el OCR para convertir los recibos, las facturas y otros documentos en formatos electrónicos para diversos fines, como la presentación de impuestos en línea, etc.
- Parte 1. Visión General del OCR
- Parte 2. ¿Cómo Convertir una Imagen PDF en un PDF con Capacidad de Búsqueda?
- Parte 3. ¿Cómo Saber si un PDF no es Accesible (Editable o Buscable)?
- Parte 4. ¿Cuáles son los Beneficios de Tener PDF Accesibles?
- Parte 5. ¿Por qué Usar PDFelement Pro para Hacer OCR a los PDF?
Parte 1. Visión General del OCR
La Versatilidad del OCR
- El OCR está disponible en varios idiomas. Por ejemplo, Wondershare PDFelement Pro es ahora compatible con más de 20 idiomas diferentes e incluso puede convertir texto bilingüe o multilingüe en archivos PDF editables y con capacidad de búsqueda.
- También puedes elegir el rango de páginas que quieres convertir en caso de que no necesites que todo el documento se convierta en OCR.
- Además, tienes la opción de establecer el idioma tú mismo o permitir que el programa lo identifique (en caso de que exista más de un idioma presente en el texto).
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
¿Cómo Mejorar los Resultados del OCR?
Dado que el OCR no siempre es 100% preciso en todas las condiciones, es mejor seguir algunas prácticas generales antes de aplicar el OCR a un archivo PDF que haya sido escaneado o a un archivo de imagen que contenga texto:
Debe ser legible para el ojo humano - Si puedes leer el documento con claridad, obtendrás mejores resultados en el OCR. Los documentos que han sido escaneados a partir de papel arrugado o las imágenes que están borrosas dan malos resultados.
Debe tener una resolución media o alta - Un texto de baja resolución produce resultados de OCR deficientes, así que asegúrate de que las imágenes que utilizas tienen la resolución adecuada. Puedes utilizar una herramienta de extrapolación de imágenes para aumentar la resolución o los PPP y así tener más posibilidades de obtener resultados de OCR precisos.
Desencriptar el documento - Si el texto va acompañado de otros caracteres sin sentido, al buscador de OCR te resulta más difícil separar los caracteres reales de las formas aleatorias. Utiliza una herramienta de eliminación de ruido para reducir el ruido de la imagen y aumentar el contraste del texto y obtendrás conversiones más precisas.
El texto horizontal es mejor que el texto inclinado - Los motores de OCR trabajan analizando el documento de forma horizontal de arriba a abajo. Si el texto está sesgado o inclinado, es más difícil de convertir. Por lo tanto, asegúrate de que el texto esté desviado antes de ejecutar el OCR en él.
El OCR Avanzado Trabaja con Más que Caracteres
Los programas de OCR simples están diseñados para trabajar con contenido de texto simple. Sin embargo, los más avanzados, como el complemento de OCR utilizado en PDFelement Pro, pueden identificar caracteres especiales, operaciones matemáticas, fórmulas químicas y otros caracteres. La función de idiomas es un gran ejemplo de lo flexible y potente que es. Si tienes un documento con una mezcla de texto, caracteres especiales, fórmulas y otros fragmentos extraños de información que se pueden convertir en archivos PDF editables o con capacidad de búsqueda, PDFelement Pro es la mejor opción para hacer un OCR a un PDF.
Parte 2. ¿Cómo Convertir una Imagen PDF en un PDF con Capacidad de Búsqueda?
Realizar el OCR en un documento en PDFelement es un proceso muy sencillo gracias al código inteligente que subyace en la intuitiva interfaz de usuario del programa. Cuando se abre un archivo PDF que ha sido escaneado desde un documento físico o una imagen con texto que ha sido convertida a PDF, el programa lo reconoce automáticamente y te pregunta si primero quieres descargar e instalar el complemento de OCR. A continuación, te pedirá que instales el complemento y realices la acción de OCR. Veamos cómo hacerlo paso a paso:
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
1. Para instalar manualmente el complemento, ve a Herramientas → Reconocimiento de Texto OCR o ve a PDFelement → Preferencias → Complemento → Instalar.
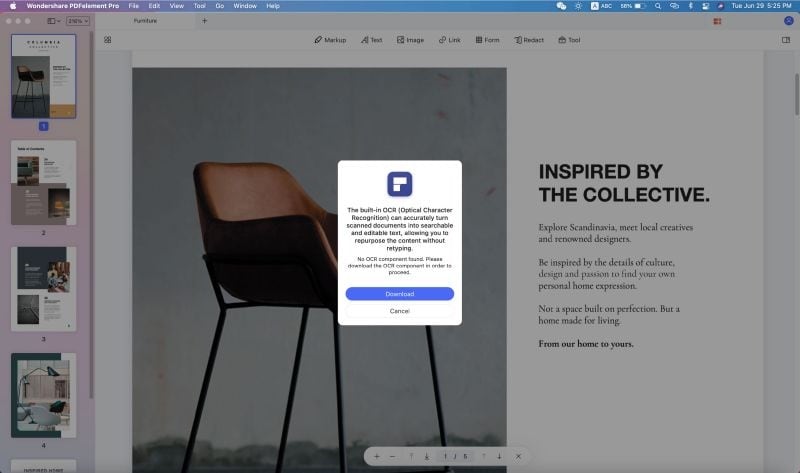
2. Cuando abras un archivo PDF que no sea editable, verás una barra de notificación y un aviso que dice 'Realizar OCR' encima de la vista del documento. Haz clic en ella.
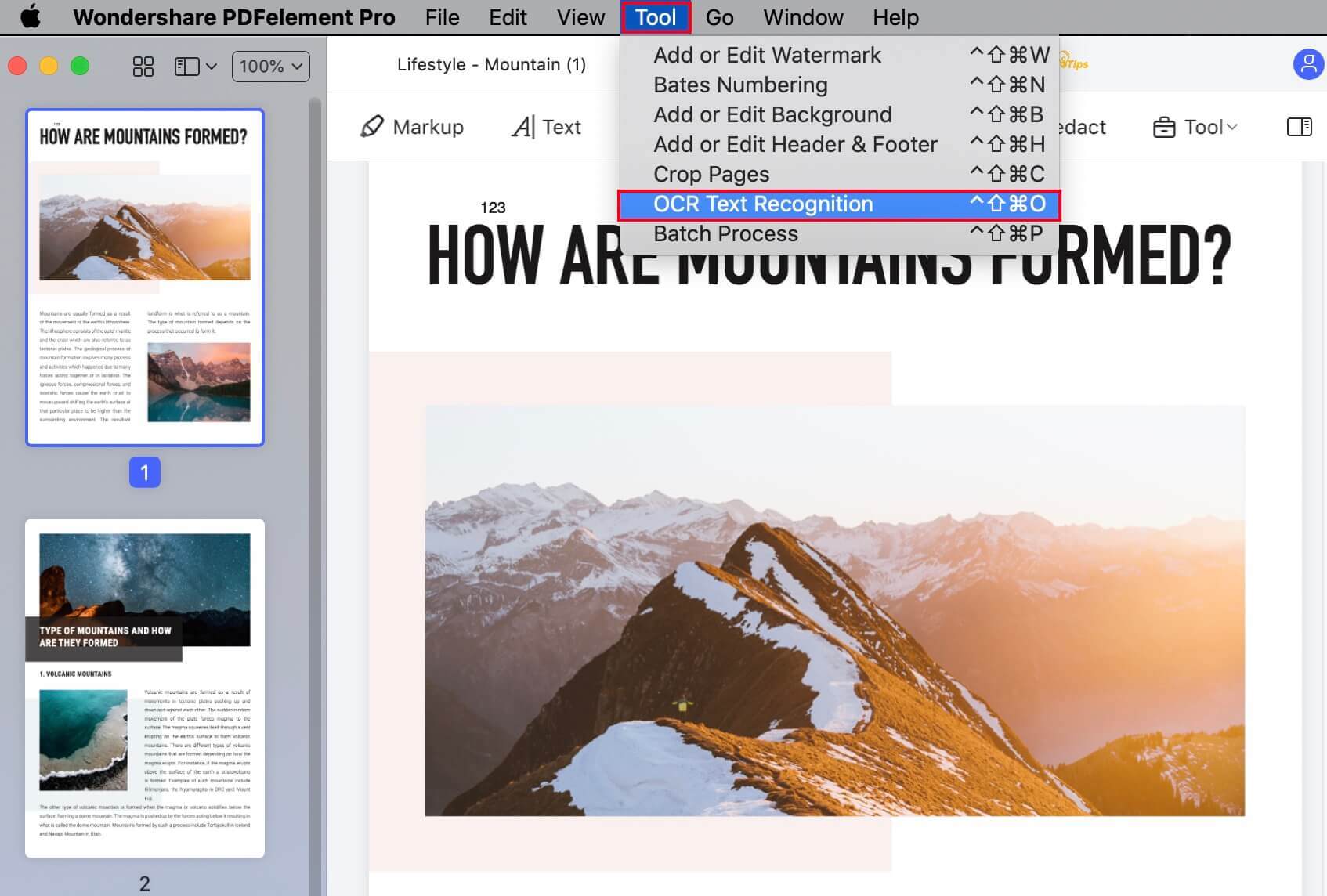
3. En la pequeña ventana emergente, elige el rango de páginas a convertir. Las opciones son Todas, Páginas Impares, Páginas Pares y Personalizada, lo que te da la flexibilidad de elegir la que quieras exactamente. Haz clic en Aceptar para continuar.
4. En la ventana de configuración del OCR, elige el idioma, la resolución de muestreo y si quieres que el texto convertido se pueda editar o sólo buscar.
5. Haz clic en Realizar OCR y el archivo se convertirá y se mostrará en el programa. Ahora puedes editar el archivo o buscarlo dependiendo de la opción que hayas elegido en el paso anterior.
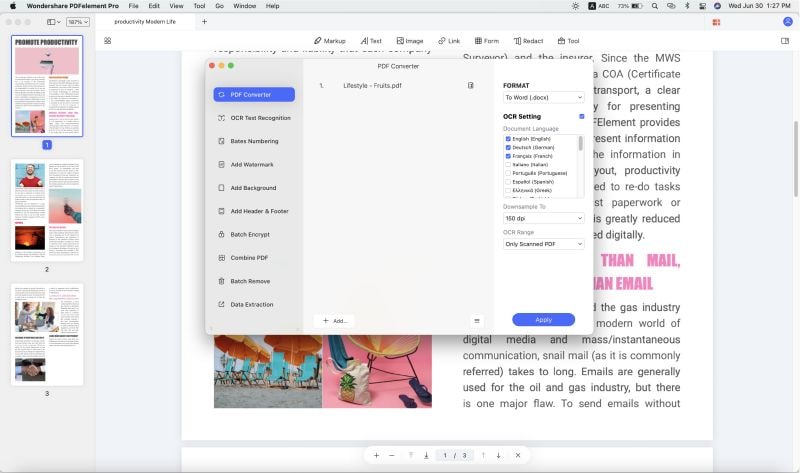
Si tienes más de un documento para realizar el OCR, puedes utilizar el Proceso de Lote de OCR para ello.
1. Ve a Herramienta → Proceso por Lotes.
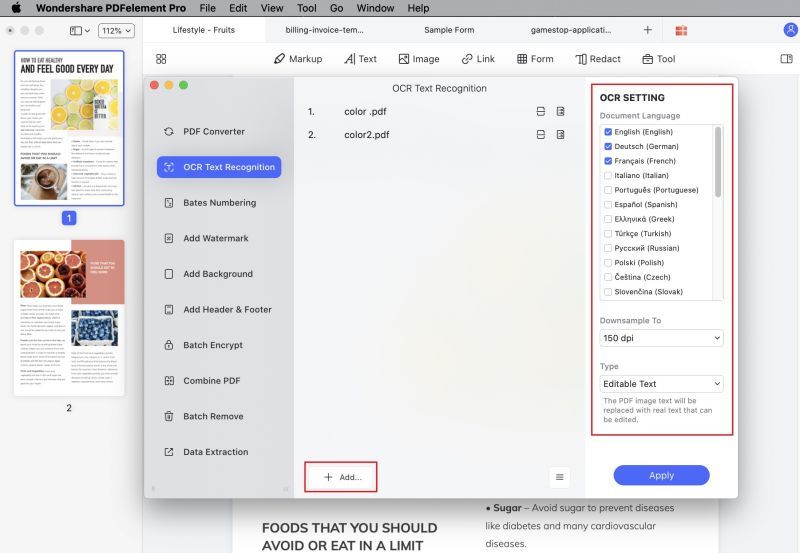
2. En la ventana Proceso por Lotes, elige la pestaña OCR en el panel de la barra lateral izquierda.
3. Ahora arrastra y suelta tus archivos o utiliza el botón Añadir Archivos en la parte inferior para importar varios documentos escaneados.
4. En el panel de la barra lateral derecha, elige la configuración de OCR como se describió anteriormente.
5. Haz clic en Aplicar para realizar el OCR en todos estos documentos.
Una vez que el documento o los documentos hayan sido convertidos, puedes guardarlos con un nombre de archivo diferente para indicar si son editables o se pueden buscar. Los archivos originales permanecerán tal cual.
Parte 3. ¿Cómo Saber si un PDF no es Accesible (Editable o Buscable)?
Cuando abras un archivo PDF en PDFelement, éste escaneará automáticamente el documento y lo preparará para su edición y otras tareas. Cuando esto sucede, suele reconocer el texto escaneado y te avisará con la mencionada notificación. En caso de que se pierda eso, podrás saber fácilmente si el documento es accesible o no.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
1. Intenta editar un texto haciendo clic en Texto en el panel de la barra lateral izquierda y seleccionando cualquier texto del documento. Si no puedes seleccionarlo, significa que el texto no es editable.
2. Después, intentar buscar el texto que puedas ver dentro del documento utilizando el comando Cmd+F.
3. A continuación, intenta utilizar la función de edición de imágenes haciendo clic en Imagen a la izquierda y seleccionando una imagen.
Si no puede realizar ninguna de las acciones anteriores, significa que el archivo PDF no se puede leer, editar o buscar.
Parte 4. ¿Cuáles son los Beneficios de Tener PDF Accesibles?
Todos sabemos que el OCR es importante. Pero, ¿por qué es así? ¿Por qué no podemos dejar los PDF basados en imágenes y los PDF escaneados como están? Las razones son muchas:
- Estos archivos no son fáciles de buscar por contenido específico, lo que se convierte en un problema con archivos muy grandes.
- No se pueden convertir a otros formatos editables como Word, Excel, etc.
- Obviamente, no pueden editarse de ninguna manera, por lo que si la información que contienen se vuelve obsoleta e irrelevante, el propio archivo se vuelve inútil a menos que haya una forma de actualizar la información.
- Las imágenes no pueden extraerse individualmente de un archivo de este tipo, a no ser que se utilice una solución como la realización de capturas de pantalla. Si eres diseñador, sabrás que esta no es la forma ideal de trabajar.
Asimismo, hay otras razones por las que el OCR es una parte fundamental de los flujos de trabajo de los documentos. Los PDF accesibles son más fáciles de archivar, buscar, editar, convertir y realizar otras tareas en PDF que no se pueden hacer en un archivo no legible.
Parte 5. ¿Por qué Usar PDFelement Pro para Hacer OCR a los PDF?
PDFelement Pro utiliza el potente y preciso ABBYY® FineReader® Engine 11 para convertir archivos basados en imágenes en PDF editables. Este motor de OCR es una de las aplicaciones mejor valoradas en esta categoría y es bien conocido por su precisión, velocidad y capacidad de procesar grandes cantidades de datos (proceso por lotes) en poco tiempo.
Además, el propio PDFelement ofrece una interfaz superior para interactuar con dichos archivos antes y después de la conversión. Antes de convertirlos con OCR, se pueden organizar eliminando o añadiendo páginas, fusionando archivos, eliminando marcas de agua, etc. Una vez convertidos con OCR, PDFelement permite realizar una gran cantidad de otras operaciones como la conversión, la protección, la cumplimentación de formularios, la firma electrónica, la optimización del tamaño de los archivos y varias tareas importantes como éstas.
Sobre todo, PDFelement Pro es una de las soluciones para PDF más asequibles del mercado con una gama tan impresionante de ricas funciones, una interfaz de usuario intuitiva, una navegación cómoda, procesos útiles y una curva de aprendizaje prácticamente nula.
Preguntas Frecuentes (FAQs)
¿Puede el OCR convertir texto escrito a mano?
Sí, siempre que la letra sea legible y clara (no descolorida), y que no existan arrugas en el papel antes de escanearlo, el OCR puede leer bastante bien el texto escrito a mano. Por supuesto, no será tan preciso como realizar el OCR en un texto impreso, pero definitivamente es posible hasta cierto punto.
¿Puedo crear directamente un PDF editable a partir de un escáner?
Sí, PDFelement tiene una opción Archivo → Nuevo → PDF desde el escáner en el menú se puede utilizar para esta función. Todo lo que tiene que hacer es conectar el escáner a la misma computadora que ejecuta PDFelement Pro, utilizar esta opción del menú para activar el proceso y seguir los pasos que se muestran. El documento escaneado se puede editar o buscar.
¿El OCR tiene un costo adicional con PDFelement Pro?
No, el complemento de OCR está incluido en PDFelement Pro. Sin embargo, es necesario descargarlo e instalarlo por separado como se muestra arriba. Esto se debe a que el tamaño es muy grande, lo que afectará el tiempo de descarga e instalación del propio PDFelement si se incluyera en el archivo de instalación.



Andrés Felipe
Experto en PDF