Los PDF forman parte del día a día de la mayoría de los equipos: facturas, contratos, informes mensuales. Leer un PDF es sencillo, pero extraer datos de un PDF y convertirlos en información utilizable para hojas de cálculo o bases de datos es otra historia. Las personas terminan copiando totales y fechas manualmente, y ahí empiezan los retrasos y los errores. A medida que crece el volumen de documentos, la necesidad de automatizar la extracción de datos de PDF se vuelve más urgente para la eficiencia operativa y la precisión en los informes.
Por eso, las organizaciones exploran métodos manuales, automatizados e impulsados por IA para mejorar sus resultados. Cada enfoque ofrece distintos niveles de velocidad, flexibilidad y control. Elegir el método adecuado depende de la complejidad del documento y las exigencias del flujo de trabajo.
En este artículo
- Qué significa extraer datos de un PDF
- Por qué extraer datos de PDF suele ser difícil
- Cómo extraer datos de formularios PDF rellenables
- Cómo extraer datos de PDFs sin formularios y convertirlos a Excel
- Cómo extraer datos de PDFs escaneados con OCR
- Extracción automática de datos de PDF: qué se puede y qué no automatizar
- Extracción de datos de PDF con IA: cómo cambia el proceso
- Cómo usar PDFelement para extraer datos de PDF [Recomendado]
- Exportar datos de PDF a Excel, Google Sheets y otras herramientas
- IA vs. herramientas de automatización: Power Automate y similares
- Errores comunes al extraer datos de un PDF
Qué significa realmente extraer datos de un PDF
Abrir un PDF y leerlo puede parecer suficiente. Sin embargo, ver un documento es muy diferente a extraer datos de archivos PDF. Extraer datos significa capturar valores, campos o registros específicos y convertirlos en formatos estructurados y utilizables, como hojas de cálculo o bases de datos. El objetivo no es solo leer el contenido, sino transformarlo en información accionable.
Visualización frente a extracción de datos
Cuando visualizas un PDF, navegas por las páginas manualmente: copias y pegas números o los vuelves a escribir en otro lugar. En cambio, cuando extraes datos de documentos PDF, el sistema identifica automáticamente la información objetivo: números de factura, totales, fechas, nombres o filas de tablas, y los organiza en salidas estructuradas. La extracción se centra en la precisión, la repetibilidad y la utilidad, no solo en la legibilidad.
Datos estructurados frente a datos no estructurados en PDF
Algunos PDF tienen diseños predecibles con campos etiquetados y tablas claras. Estos documentos estructurados permiten reconocer patrones de datos de forma rápida y fiable. Otros PDF contienen texto libre, formato irregular o contenido de imagen escaneada. Los archivos no estructurados requieren interpretación contextual de las relaciones entre sus elementos. Una extracción eficaz se adapta a ambos formatos sin perder fiabilidad.
Casos de uso comunes en empresas e investigación
Los siguientes casos muestran dónde la extracción de datos de PDF ahorra tiempo y reduce errores:
- Procesamiento de facturas: los equipos de contabilidad extraen totales, fechas y nombres de proveedores de facturas de forma rápida, lo que reduce la introducción manual de datos y los retrasos en los pagos en periodos de alta carga.
- Documentación de RRHH: el personal de recursos humanos captura datos de empleados desde formularios y documentos firmados, manteniendo los registros coherentes y facilitando auditorías o revisiones de políticas.
- Revisión de contratos: los equipos legales extraen fechas de renovación, cláusulas clave y obligaciones de los acuerdos, acelerando las revisiones y evitando plazos perdidos o malentendidos costosos.
- Actualización de datos de ventas: los equipos comerciales obtienen datos de clientes y precios de propuestas y cotizaciones, lo que mantiene el CRM limpio y mejora las previsiones de negocio.
- Datos de investigación: los investigadores extraen tablas, referencias y resultados de artículos académicos en PDF, agilizando el análisis y la elaboración de informes y publicaciones.
Por qué extraer datos de PDF suele ser difícil
Los archivos PDF parecen ordenados y estructurados a simple vista. Sin embargo, fueron diseñados originalmente para preservar el diseño visual, no para almacenar datos en un formato flexible y reutilizable. Un PDF prioriza mantener las fuentes, los espaciados y el diseño uniforme en cualquier dispositivo. Esa estabilidad visual facilita la lectura, pero complica notablemente la extracción de datos de archivos PDF.
Los PDF están diseñados para el diseño visual, no para los datos
A diferencia de las hojas de cálculo o las bases de datos, los PDF no organizan la información en campos de datos bien definidos. Lo que parece una tabla ordenada puede ser, en realidad, cuadros de texto separados posicionados visualmente sobre la página. Por eso, los sistemas de extracción deben interpretar la posición visual antes de identificar valores significativos.
Tipos de PDF y sus desafíos específicos de extracción
| Tipo de PDF | Descripción | Desafío principal para la extracción |
| PDF digital (nativo) | El texto es seleccionable; suele generarse al exportar desde software como Word o Excel. | Las tablas pueden ser "visuales", con columnas formadas por espacios en lugar de una estructura real de datos. |
| Formulario PDF rellenable | Contiene campos de formulario para introducir nombres, fechas y valores. | Los campos mal diseñados, los nombres inconsistentes y las capas ocultas pueden generar resultados erróneos. |
| PDF escaneado | Una foto o escaneo guardado como imagen dentro del PDF. | Requiere OCR previo, y la baja calidad del escaneo reduce la precisión del reconocimiento. |
Por qué un único método no funciona para todos los PDF
Dado que los formatos varían considerablemente, un solo método de extracción rara vez se adapta a todos los casos. Una herramienta que funciona perfectamente con informes digitales puede fallar con recibos escaneados. Por eso, los flujos de trabajo exitosos suelen combinar varias técnicas según el tipo y la calidad del documento.
Método 1: Cómo extraer datos de formularios PDF rellenables
Los formularios PDF rellenables almacenan las respuestas en campos con nombre, no en bloques de texto simples. Cada campo tiene una etiqueta y un valor, lo que facilita la recopilación coherente de información. Esta estructura permite a las herramientas extraer datos de formularios PDF con menos errores de formato.
Exportar datos de formularios directamente
Cuando un PDF incluye campos de formulario reales, puedes exportar esos valores en minutos. La mayoría de las herramientas PDF ofrecen una opción de exportación que genera un archivo CSV, FDF o XML. Tras exportarlo, ábrelo en una hoja de cálculo y verifica que las columnas coincidan con los nombres de los campos.
Cuándo funciona mejor este método
Este método funciona mejor cuando los documentos utilizan la misma plantilla de formulario en todos los casos. Es ideal para encuestas, solicitudes y listas de verificación donde cada campo se rellena de forma consistente. No resulta eficaz en PDF escaneados, imágenes o diseños sin campos interactivos.
Método 2: Extraer datos de PDFs sin formularios y convertirlos a Excel
Los PDF sin formularios suelen contener datos en tablas visibles o columnas alineadas. Estos documentos muestran estructura visualmente, pero el archivo puede no contener campos de datos reales. Es posible capturar los valores si las filas y columnas son consistentes a lo largo de las páginas. Este escenario es uno de los más buscados por los usuarios: convertir PDF a Excel o extraer tablas para su análisis.
Copiar y pegar frente a extracción estructurada
Copiar y pegar funciona para tablas pequeñas, pero el formato se rompe con facilidad. Las herramientas de extracción estructurada intentan mantener filas, columnas y encabezados correctamente alineados. Cuando la precisión es importante, la extracción estructurada ahorra tiempo de limpieza posterior en la hoja de cálculo.
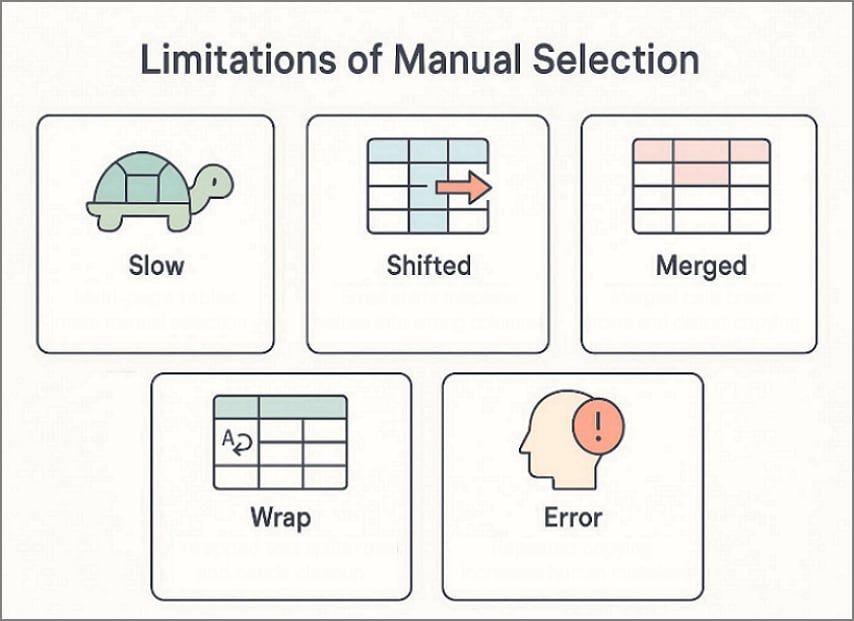
Limitaciones de la selección manual
- La selección manual es lenta cuando las tablas se extienden a lo largo de varias páginas.
- Pequeñas desalineaciones pueden desplazar valores a columnas incorrectas.
- Las celdas combinadas suelen romper la estructura de filas y distorsionar los resultados copiados.
- El texto ajustado crea filas divididas que requieren limpieza adicional.
- El error humano aumenta al copiar muchas tablas de forma repetida.
Herramientas para convertir PDF a Excel o Google Sheets
Si tu objetivo principal es exportar datos de PDF a Excel o Google Sheets, dispones de varias opciones según la complejidad del documento:
- Herramientas en línea gratuitas (como iLovePDF, Smallpdf o PDF24): ideales para conversiones ocasionales de PDF digital a Excel sin instalar nada.
- Microsoft Excel con Power Query: permite importar tablas directamente desde un PDF usando la pestaña "Datos" → "Obtener datos" → "Desde archivo PDF". Funciona bien con PDF nativos.
- Software de escritorio especializado (como PDFelement): ofrece mayor control sobre la selección de tablas, el procesamiento por lotes y la integración de OCR para PDF escaneados.
Método 3: Extraer datos de PDFs escaneados con OCR
Los PDF escaneados son imágenes de página, no texto seleccionable. Por eso, el software debe leer la imagen y convertirla en texto. El OCR (reconocimiento óptico de caracteres) permite extraer datos de PDF escaneados reconociendo caracteres impresos y patrones de diseño.
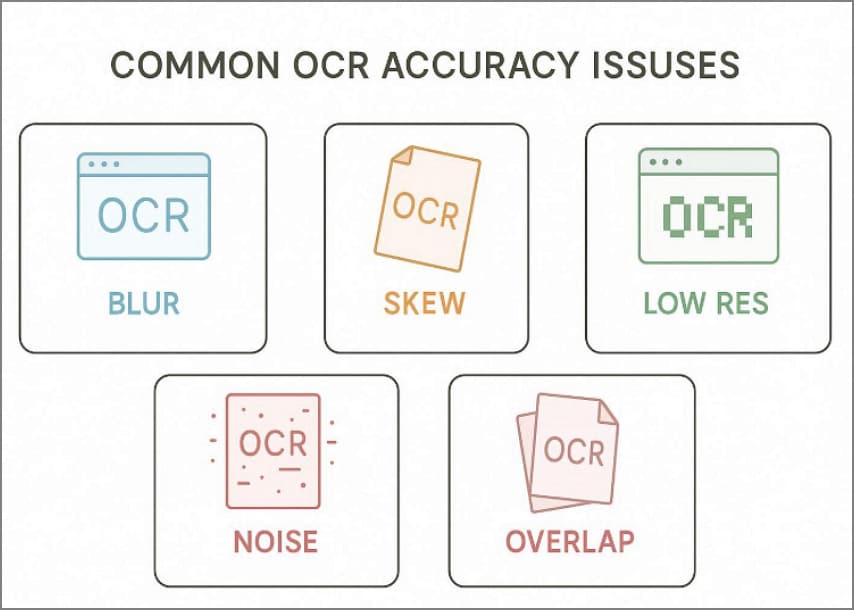
Problemas comunes de precisión en el OCR
- Los escaneos borrosos reducen la confianza del OCR y dificultan la extracción precisa de datos.
- Las páginas torcidas desalinean las líneas de texto, lo que genera palabras incorrectas y filas de tablas rotas.
- Las imágenes de baja resolución producen caracteres irregulares, haciendo que los números se lean mal o se combinen.
- Las sombras y el ruido de fondo añaden artefactos visuales que confunden la puntuación, los decimales y los bordes de los campos.
- La escritura a mano, los sellos y las firmas superpuestas reducen la precisión e incrementan las correcciones manuales necesarias.
Cuándo el preprocesamiento mejora los resultados del OCR
El preprocesamiento mejora el OCR cuando la calidad del escaneo es irregular o difícil de leer. Pasos como la corrección de inclinación, la eliminación de ruido, el aumento del contraste y el recorte de márgenes reducen los errores. Si las páginas están rotadas o presentan curvatura, la corrección previa ayuda al OCR a detectar mejor las líneas y columnas.
Extracción automática de datos de PDF: qué se puede y qué no se puede automatizar
A medida que las organizaciones amplían el procesamiento de documentos, la extracción automática de datos de PDF se convierte en una necesidad operativa. Reduce la introducción manual, acorta el tiempo de procesamiento y mejora la coherencia en los flujos de trabajo recurrentes. Sin embargo, funciona mejor dentro de límites bien definidos. Entender qué se puede y qué no se puede automatizar ayuda a establecer expectativas realistas.
Qué sí se puede automatizar
Extracción basada en reglas
La extracción basada en reglas funciona bien con diseños de documentos predecibles. Captura valores mediante palabras clave, coordenadas o etiquetas de campo consistentes. Las facturas estandarizadas, las plantillas internas y los informes recurrentes son candidatos ideales. Cuando la estructura se mantiene estable, la automatización ofrece resultados rápidos y fiables.
Procesamiento por lotes
El procesamiento por lotes permite manejar grandes volúmenes de PDF similares en una sola operación. Los equipos pueden cargar múltiples archivos y extraer datos de forma automatizada. Esta opción es eficaz para facturas mensuales, reclamaciones o estados de cuenta de proveedores. Los entornos de alto volumen se benefician de la rapidez y la reducción de tareas repetitivas.
Dónde falla la automatización
La automatización falla cuando los diseños varían mucho entre diferentes tipos de documento. El texto no estructurado, el formato inconsistente y la escritura a mano reducen considerablemente la precisión de extracción. Los escaneos de baja calidad pueden requerir corrección manual tras el reconocimiento OCR. Los campos ambiguos exigen interpretación contextual que las reglas fijas no pueden ofrecer de forma fiable.
Extracción de datos de PDF con IA: cómo cambia el proceso
Los sistemas tradicionales tratan los PDF como imágenes fijas con diseños bloqueados. En cambio, la extracción de datos de PDF con inteligencia artificial transforma el procesamiento documental de forma práctica. En lugar de leer coordenadas, la IA evalúa la estructura, las relaciones y el significado contextual. Este cambio convierte la extracción de una captura mecánica en una comprensión inteligente del documento.
Cómo la IA interpreta la estructura de un documento
La IA analiza de forma conjunta el espacio, la alineación, la jerarquía tipográfica y la agrupación del contenido. Detecta encabezados, tablas, totales y etiquetas a través de señales estructurales. En lugar de depender de posiciones fijas de píxeles, estudia las relaciones lógicas entre los elementos. De esta forma, la extracción se mantiene estable incluso cuando los diseños cambian de manera inesperada.
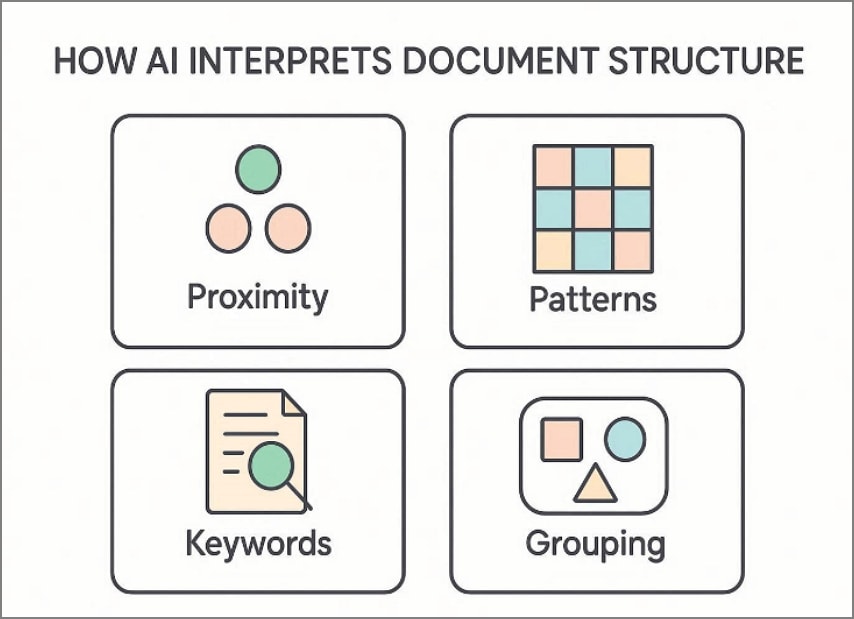
Estos son los principales factores que la IA considera al interpretar un documento:
- Proximidad del texto entre etiquetas y valores en secciones y columnas.
- Patrones repetidos que indican tablas, partidas o listas estructuradas.
- Palabras clave contextuales que especifican totales, impuestos, fechas e identificadores.
- Agrupación visual que conecta campos relacionados dentro del mismo contexto.
Extraer significado, no solo texto
La automatización tradicional capturaba caracteres sin entender su propósito. Las herramientas de IA que extraen datos de PDF interpretan la intención a partir del contexto. Por ejemplo, la palabra "Total" suele indicar el importe a pagar junto a esa etiqueta. El contexto reduce la confusión entre números de factura y campos de referencia similares, por lo que los resultados extraídos requieren menos correcciones en la validación y los informes.
IA para gestionar diseños inconsistentes
En los flujos de trabajo reales, los proveedores rara vez mantienen un formato idéntico de manera consistente. Las tablas cambian de posición, los encabezados se desplazan y las tipografías varían entre versiones de documentos. Los sistemas basados en reglas suelen fallar cuando las plantillas cambian sin previo aviso. La IA, en cambio, se adapta utilizando las relaciones entre etiquetas y valores, no coordenadas.
| Extracción basada en reglas | Extracción basada en IA |
| Depende de posiciones fijas y plantillas rígidas para extraer campos. | Usa la estructura y el contexto para identificar campos con mayor fiabilidad. |
| Falla cuando los diseños cambian ligeramente entre proveedores o versiones. | Se mantiene funcional incluso cuando las columnas cambian o los encabezados se desplazan. |
| Captura cadenas de texto sin interpretar su significado dentro del documento. | Extrae valores significativos comprendiendo las etiquetas y sus relaciones. |
Cómo usar PDFelement para extraer datos de PDF
Los PDF se ven ordenados, pero extraer datos limpios puede resultar frustrante. Los formularios pueden exportar campos, las tablas pueden perder su estructura y los documentos escaneados necesitan un OCR preciso. En lugar de cambiar de herramienta constantemente, muchos equipos prefieren un único flujo de trabajo para todos los casos. Ahí es donde PDFelement resulta útil, permitiendo extraer datos de formularios PDF y de otros tipos de diseño desde un mismo lugar.
Puedes extraer datos de forma fiable desde formularios rellenables, tablas o páginas escaneadas, revisar los resultados, exportar archivos estructurados y repetir el proceso con mayor rapidez.
Extraer datos de formularios y tablas PDF
Los formularios PDF rellenables almacenan respuestas en campos con nombre, no en bloques de texto. Los PDF de tablas parecen estructurados, pero a menudo carecen de etiquetas preparadas para exportar. PDFelement captura ambos tipos exportando campos o extrayendo tablas seleccionadas. Úsalo para facturas, solicitudes e informes donde las columnas y etiquetas se repiten de forma consistente. Sigue los pasos a continuación para exportar datos limpios y verificar los resultados:
Paso 1Abre el PDF en PDFelement
Inicia PDFelement y selecciona Abrir PDF desde el panel principal.
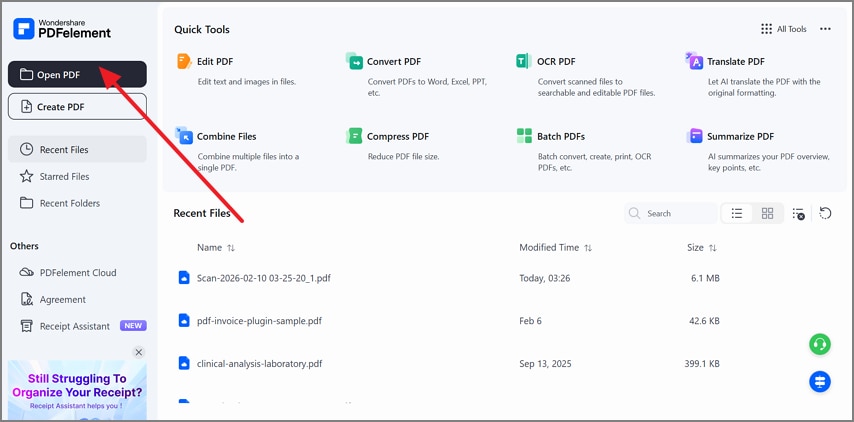
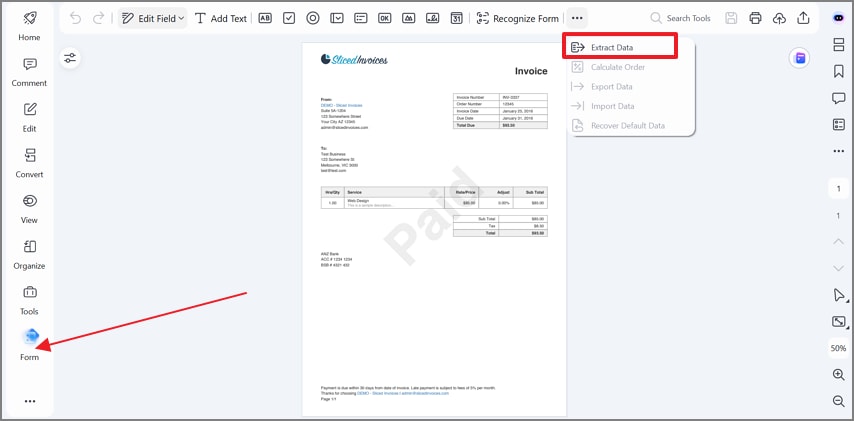
Paso 2Accede a la herramienta de formulario
Ve a Formulario en la barra lateral izquierda y haz clic en el icono de tres puntos. En el menú desplegable, selecciona Extraer datos para iniciar el proceso de captura de datos estructurados.
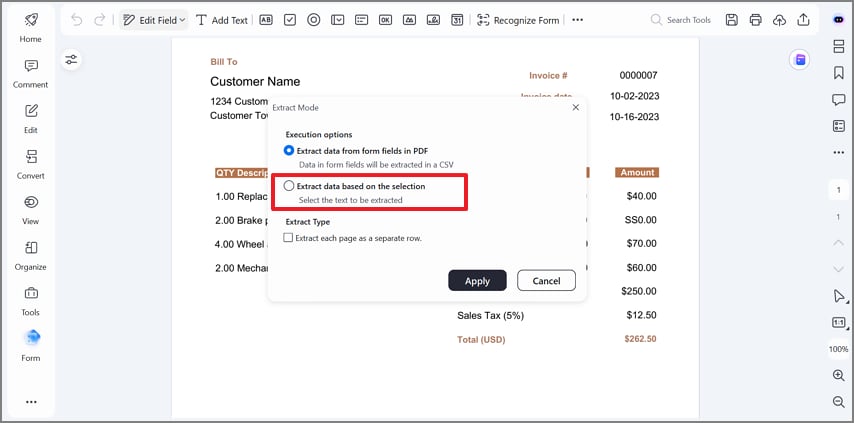
Paso 3Elige el modo de extracción
Selecciona Extraer datos según la selección en el cuadro de diálogo y pulsa Aplicar. Este modo permite un control preciso, extrayendo solo los campos que selecciones manualmente.
Paso 4Marca los campos y aplica la extracción
Dibuja cuadros de selección alrededor de los campos que necesitas —artículos, totales, valores de impuestos— y haz clic en Aplicar.
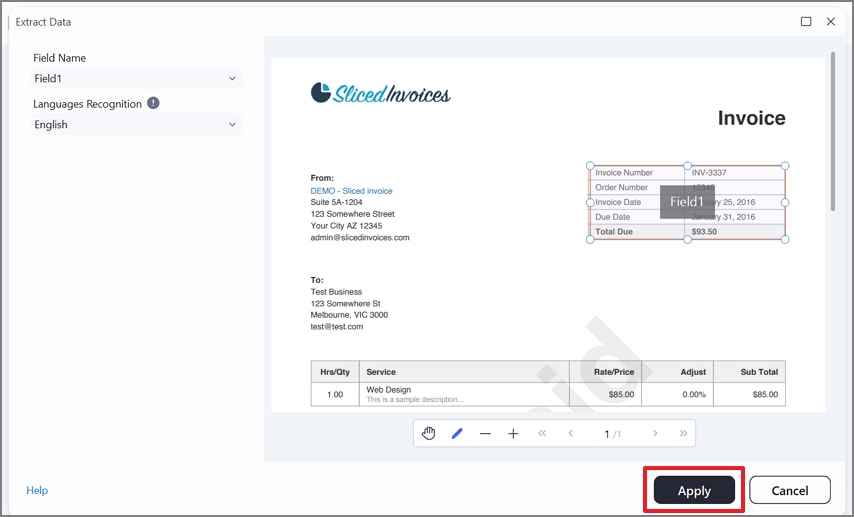
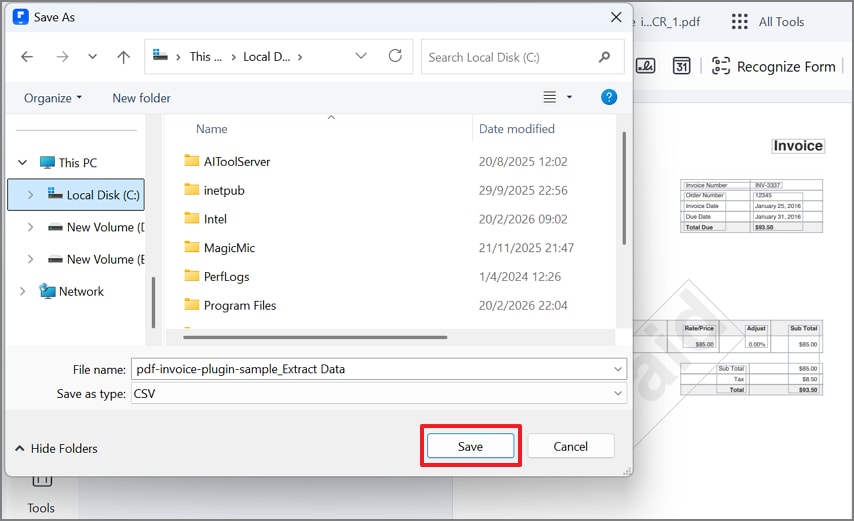
Paso 5Exporta los datos como CSV y guarda el archivo
PDFelement abre automáticamente el cuadro de diálogo Guardar como. Elige el formato de exportación deseado —por ejemplo, CSV— y pulsa Guardar para exportar los datos extraídos a tu dispositivo.
Extracción con OCR para PDFs escaneados
Los PDF escaneados son imágenes, por lo que no es posible copiar texto directamente. El OCR convierte la imagen en texto seleccionable, mejorando tanto la búsqueda como la precisión de extracción. Unos escaneos de mayor calidad producen mejores resultados, especialmente en tablas y valores numéricos. El preprocesamiento corrige inclinaciones, desenfoque y ruido, lo que reduce los errores durante el reconocimiento. Sigue estos pasos para aplicar OCR con PDFelement:
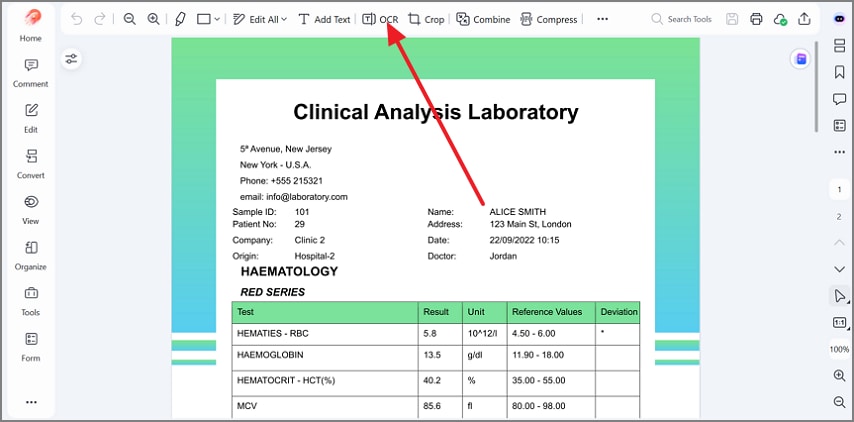
Paso 1Accede a la herramienta OCR
Abre el PDF escaneado en PDFelement y haz clic en OCR en la barra de herramientas superior.
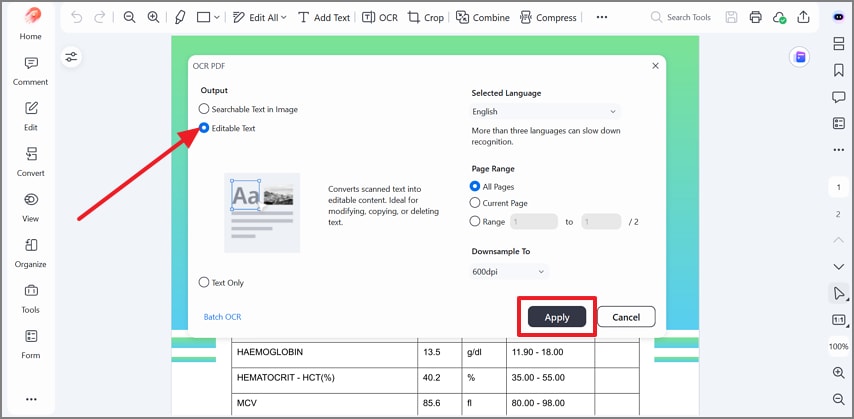
Paso 2Selecciona texto editable y aplica el OCR
Elige Texto editable en la ventana de OCR, confirma el idioma y el rango de páginas y pulsa Aplicar para convertir el escaneo en texto editable y seleccionable.
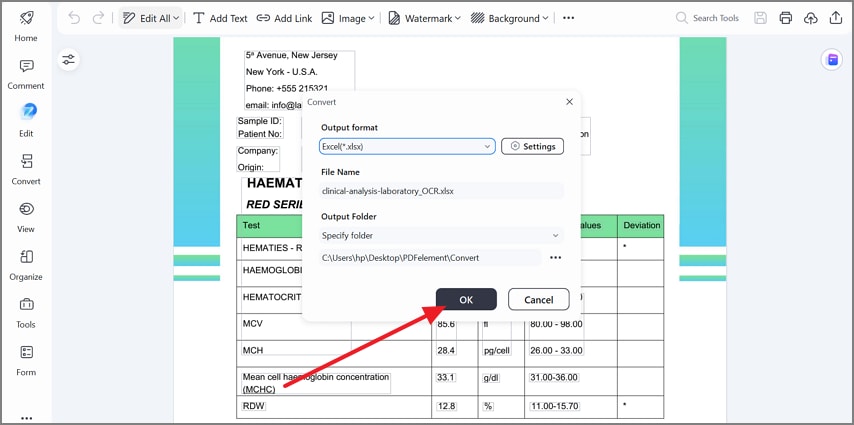
Paso 3Convierte el archivo OCR a formato Excel
Ve a Convertir y elige A Excel en el menú desplegable para preparar los datos de la tabla para su extracción y edición en una hoja de cálculo.
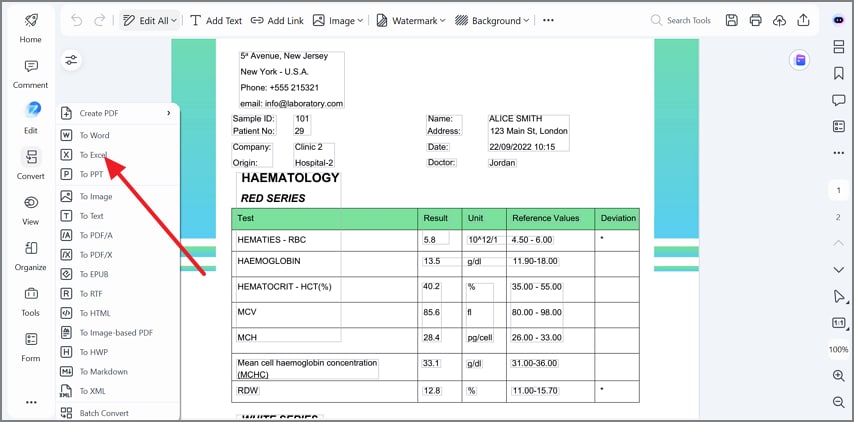
Paso 4Guarda como XLSX y verifica la hoja de cálculo
Mantén Excel (*.xlsx) como formato de salida, selecciona una carpeta de destino y haz clic en OK. Abre la hoja exportada y verifica que las columnas, los totales y las unidades sean correctos.
Extracción por lotes para diseños repetidos
La extracción por lotes procesa múltiples PDF a la vez aplicando el mismo patrón de selección. Funciona mejor cuando los documentos comparten la misma plantilla y estructura de página. Defines las regiones de extracción una sola vez y las aplicas a toda la carpeta. Este enfoque agiliza informes mensuales, facturación y auditorías, manteniendo columnas coherentes para el análisis. Sigue estos pasos para usarlo en PDFelement:
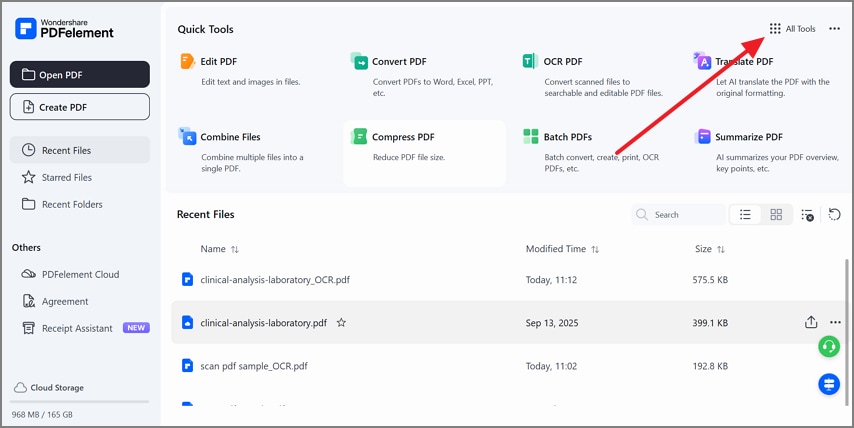
Paso 1Abre Todas las herramientas para acceder al proceso por lotes
Inicia PDFelement y selecciona Todas las herramientas.
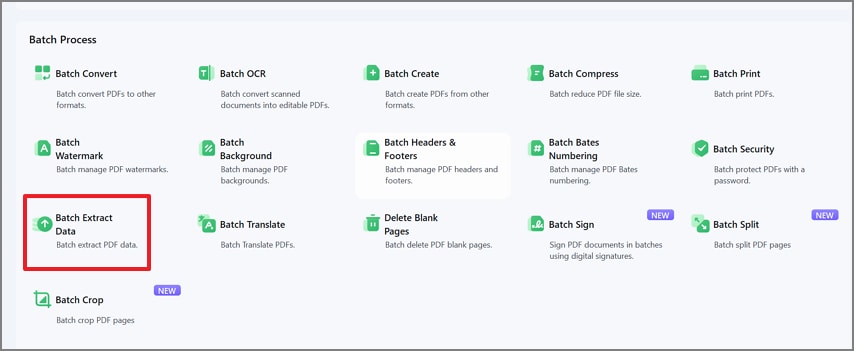
Paso 2Selecciona Extraer datos por lotes
En la ventana de Proceso por lotes, elige Extraer datos por lotes para iniciar la herramienta de extracción masiva.
Paso 3Agrega los PDF y configura las opciones de salida
Pulsa Agregar archivos y carga todos los PDF de una vez. En el panel derecho, selecciona Extraer datos de campos de formulario PDF o Extraer datos de PDF marcado, elige el estilo de exportación y confirma la carpeta de destino.
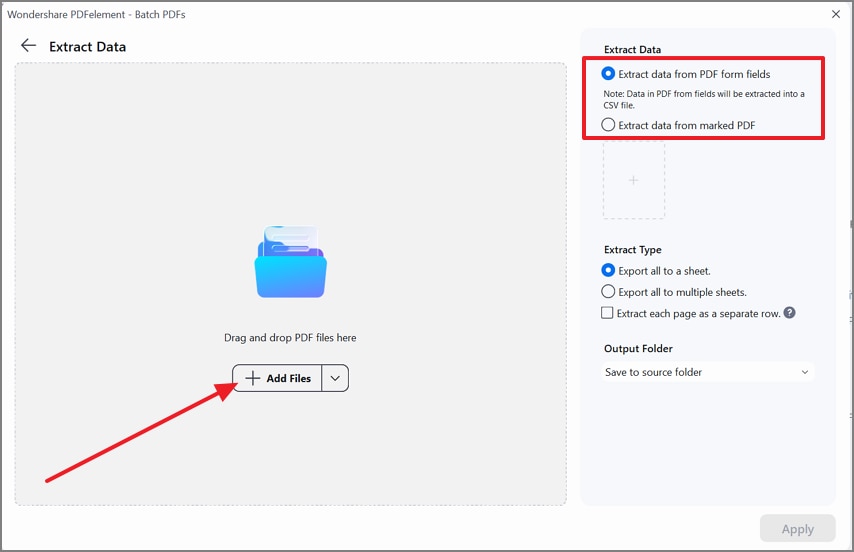
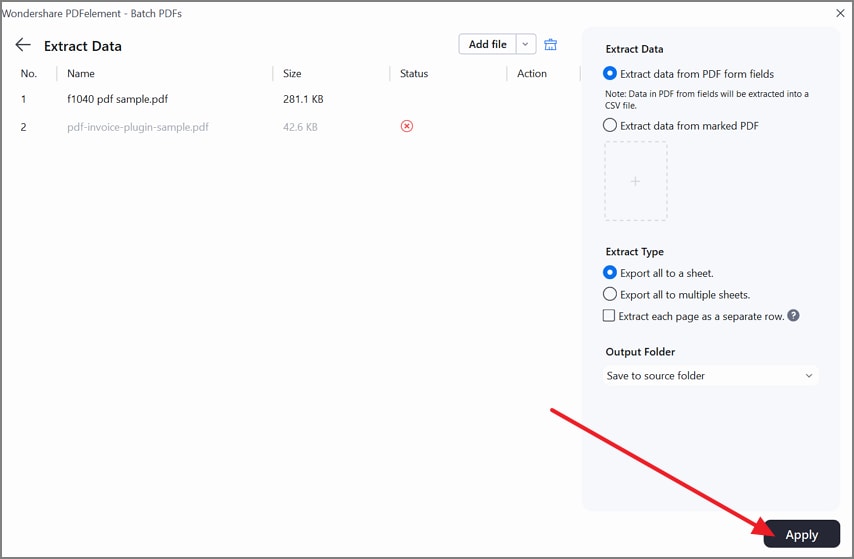
Paso 4Aplica la extracción y valida las columnas de salida
Haz clic en Aplicar para generar la hoja de resultados. Accede al archivo exportado y verifica que las columnas clave coincidan entre los distintos documentos.
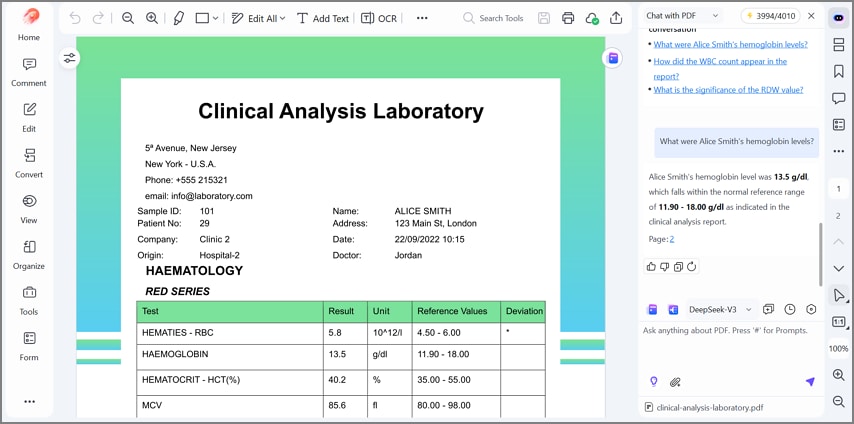
Funciones de IA de PDFelement para verificar y reutilizar datos
Tras extraer datos de un PDF, las siguientes funciones de IA de PDFelement ayudan a verificar y reutilizar los resultados con mayor rapidez:
Chat con el PDF: formula preguntas instantáneas sobre totales, fechas, proveedores o campos faltantes directamente sobre el documento. Esto permite verificar números antes de compartir los resultados.
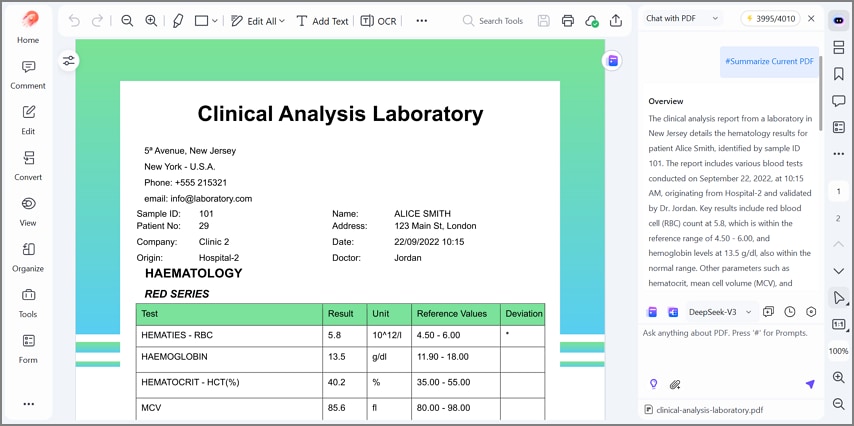
Resumen con IA: resume automáticamente PDF extensos en puntos clave, decisiones y cifras importantes. Señala tendencias, anomalías y elementos que requieren revisión humana.
Exportación de resultados estructurados: exporta los datos como CSV o Excel con encabezados estables para reutilizarlos en cualquier sistema. Una estructura coherente reduce la limpieza posterior y facilita informes, automatizaciones e importaciones futuras.
Exportar datos de PDF a Excel, Google Sheets y otras herramientas
Las opciones de exportación convierten las tablas extraídas en hojas de cálculo que los equipos pueden validar y usar de inmediato. Puedes extraer datos de un PDF a Google Sheets exportando primero a CSV e importándolo. Las exportaciones a Excel funcionan bien para limpiezas sin conexión, fórmulas y reportes basados en tablas dinámicas.
- Elige CSV o XLSX cuando necesites conservar columnas y encabezados fiables.
- Importa el archivo a Sheets y congela los encabezados para facilitar la revisión.
- Aplica los tipos de datos correctos para fechas y monedas, y evita así errores de ordenación.
Preparar los datos extraídos para automatización adicional
La automatización requiere columnas coherentes, encabezados estables y estructuras de filas predecibles. Comienza renombrando los campos con claridad y elimina los duplicados generados por encabezados repetidos.
- Estandariza el formato de fechas y decimales para evitar fallos en los scripts de automatización.
- Agrega una columna de ID único para permitir fusiones seguras entre múltiples archivos.
- Valida los totales contra el PDF original y marca los valores atípicos para revisión.
Por qué es importante una extracción limpia en los procesos posteriores
Una extracción desordenada genera errores silenciosos que se propagan a informes, paneles de control y registros de pagos. Los resultados limpios reducen las correcciones adicionales, agilizan las aprobaciones y mejoran las auditorías interdepartamentales.
- Las tablas limpias mejoran la coincidencia de datos en CRM, ERP y flujos de conciliación financiera.
- Las columnas precisas reducen las correcciones manuales al conectar con flujos de Power Automate.
- Los datos coherentes permiten decisiones más rápidas porque los KPI siguen siendo comparables a lo largo del tiempo.
IA vs. herramientas de automatización: Power Automate y soluciones similares
Las herramientas de IA se centran en comprender y limpiar documentos, mientras que las herramientas de automatización se ocupan del enrutamiento y la orquestación de flujos. Cuando los usuarios preguntan cómo Power Automate extrae datos de PDF, la respuesta clave es esta: Power Automate puede mover archivos y activar acciones, pero la calidad de la extracción previa sigue siendo determinante para el éxito del flujo.
Qué puede hacer bien Power Automate
- Enruta PDF desde correos electrónicos, OneDrive y SharePoint hacia flujos de trabajo estandarizados de forma automática.
- Activa aprobaciones, alertas y registros cuando llegan nuevos documentos PDF.
- Traslada los valores extraídos a tablas de Excel, bases de datos o campos de CRM sin necesidad de reescritura manual.
- Programa flujos recurrentes, asegurando un procesamiento coherente entre equipos y zonas horarias.
Por qué sigue siendo crucial la calidad de la extracción
- La automatización amplifica los errores: un solo dígito incorrecto puede distorsionar informes en cadena mucho más rápido.
- Las columnas desplazadas y las celdas combinadas rompen el mapeo de campos, causando desajustes que pasan desapercibidos.
- Un OCR deficiente lee mal los totales, incrementando las excepciones, las correcciones manuales y los retrasos en la conciliación.
- Una extracción limpia mejora las auditorías, los controles de cumplimiento y la confianza en las decisiones de negocio.
Cuándo preparar los datos PDF antes de automatizar
- Plantilla lista: antes de conectar Power Automate, extrae los datos del PDF y estandariza plantillas y nombres de campos.
- Corrección de escaneos: los PDF escaneados requieren corrección de inclinación y mejora del contraste antes de ejecutar el OCR.
- Normalización de tablas: las tablas desordenadas requieren encabezados normalizados y delimitadores de fila consistentes para garantizar una estructura uniforme.
- Control del diseño: los diseños variables suelen requerir una pre-extracción en una herramienta PDF antes de pasar a la automatización.
Errores comunes al extraer datos de un PDF
Antes de comenzar a extraer datos de archivos PDF, conviene evitar los supuestos incorrectos que generan errores costosos. Los siguientes errores explican por qué la precisión baja y las correcciones adicionales aumentan:

- Tratar todos los PDF igual: muchos equipos aplican el mismo método a todos los formatos PDF, lo que provoca fallos en la extracción. Diferentes tipos de PDF necesitan métodos distintos para obtener resultados consistentes y precisos.
- Dependencia excesiva del OCR: confiar únicamente en el OCR, incluso cuando la calidad del texto es baja, propaga errores de reconocimiento rápidamente a informes y registros financieros.
- Esperar automatización total: asumir que la IA resolverá todas las excepciones sin supervisión es irreal. Los diseños inusuales y los campos faltantes siguen requiriendo criterio humano.
- Omitir la validación: no aplicar controles de verificación permite que totales y fechas incorrectos pasen desapercibidos. Reglas básicas y comprobaciones cruzadas mejoran la precisión antes de exportar los resultados.
- Elegir mal la herramienta: seleccionar una herramienta sin evaluar la complejidad y variabilidad de los documentos genera resultados inconsistentes y correcciones manuales frecuentes.
Conclusión: cómo elegir el método adecuado para extraer datos de PDF
Elegir el mejor método de extracción comienza por identificar el tipo de PDF. Los formularios rellenables exportan campos con precisión; las tablas requieren selección estructurada; los documentos escaneados necesitan OCR previo para obtener resultados fiables. La automatización y la inteligencia artificial reducen el esfuerzo, pero la validación humana evita errores en los procesos posteriores. Para exportar datos de PDF a Google Sheets o Excel, limpia los encabezados antes de importar.
Si buscas un flujo de trabajo completo —extracción, OCR y exportación estructurada en un único lugar—, PDFelement es una opción sólida para equipos de cualquier tamaño.