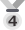100% Seguro | Sin anuncios |
100% Seguro | Sin anuncios |La tecnología PDF ha avanzado mucho en el ámbito de la digitalización de archivos en las últimas décadas. Lo que antes era un reto para la conservación de los datos y la capacidad de almacenar documentos para su fácil recuperación se ha convertido en algo habitual. Uno de los factores principales que ha impulsado este cambio es el OCR o reconocimiento óptico de caracteres. Veamos por qué OCR juega un papel tan importante en la digitalización de archivos, cómo se aplica como proceso y cómo se puede mejorar la precisión del OCR a través de varios métodos.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Parte 1. Aplicación de OCR en la Digitalización de Archivos
OCR es esencialmente el proceso de reconocer, extraer e incorporar el contenido de texto de un documento digital o físico basado en imágenes en la capa de imagen existente. Esta tecnología de doble capa es compatible con PDF, lo que lo convierte en un medio ideal para la digitalización de archivos. Hay otras consideraciones que hacen del PDF el vehículo perfecto para digitalizar archivos de documentos.
1. Innovación en las Metodologías Tradicionales de Catalogación e Indexación
La catalogación y la indexación suelen ir de la mano, pero son dos procesos totalmente diferentes. Mientras que la catalogación es la organización de los activos o elementos de contenido, la indexación está relacionada con la recuperación de la información. Ambos son necesarios cuando se archivan documentos, medios audiovisuales, periódicos, revistas, revistas académicas y otros tipos de contenido. La catalogación indica lo que está disponible, mientras que la indexación ofrece una forma de encontrar la información correcta que se está buscando.
La conversión de documentos físicos o archivos escaneados a PDF permite catalogar e indexar al mismo tiempo mediante la tecnología OCR. El contenido digitalizado se puede convertir en editable o con capacidad de búsqueda, lo que permite una fácil catalogación de los archivos, así como su indexación. Por lo tanto, el OCR es en realidad una nueva forma de catalogar e indexar los archivos de documentos, haciendo que el proceso sea accesible a través de las computadoras.
2. Realización de una Verdadera Recuperación de Texto Completo
La indexación manual suele ser propensa a los errores humanos, que pueden oscilar entre el 3% y el 30%, dependiendo de la tarea en cuestión. Esto significa que los documentos basados en texto pueden no estar correctamente indexados si el proceso se realiza manualmente. Lo mismo ocurre con la catalogación, pero en menor medida. Sin embargo, con la ayuda del OCR, la conversión es posible hasta una tasa de precisión del 98% al 99%. A su vez, esto permite la búsqueda y recuperación de texto completo. Cuando esta capacidad se combina con los metadatos y los elementos de indexación, da lugar a un sistema de catalogación e indexación mejorado.
3. Tecnología PDF de Doble Capa
Aunque la idea general es que el OCR incorpora una capa de texto sobre la imagen existente, en realidad, se presenta como texto invisible dentro del PDF. Sin embargo, este texto se puede seleccionar y, por tanto, se puede buscar. En el proceso de digitalización del archivo, el archivero verificará primero si la capa de texto digitalizada es coherente con el texto de la imagen original. Este paso de control de calidad es fundamental para la exactitud del texto renderizado. Estas modificaciones se almacenarán en la copia del archivo con el reconocimiento óptico de caracteres, lo que facilitará la búsqueda con palabras clave. Cualquier error tipográfico que se omita durante este control de calidad hará que el documento no pueda buscarse por esa palabra clave concreta. Ahí es donde entra en juego la estratificación. Permite al archivador comprobar visualmente si los caracteres reconocidos por el motor de OCR son coherentes con los del archivo original basado en imágenes.
4. Ampliar el Uso de los Archivos Archivados
Al realizar el OCR en un documento PDF se obtiene una capa que permite realizar búsquedas, pero también puede hacer que el texto sea editable. Sin embargo, a efectos de archivo y recuperación, se prefiere un documento con capacidad de búsqueda porque la información de indexación puede ayudar a devolver resultados de búsqueda de texto completo. A su vez, esto permite que los documentos con OCR se utilicen en una variedad de escenarios en función de si es editable o se puede buscar. Por ejemplo, es mucho más fácil corregir un texto en un archivo basado en imágenes utilizando el OCR que corregir ese mismo texto en una herramienta de edición de imágenes. El OCR abre un abanico de posibilidades de uso que las técnicas de archivo tradicionales no pueden igualar.
Parte 2. ¿Cómo Mejorar la Tasa de Reconocimiento de OCR?
La precisión de una ejecución de OCR depende de varias consideraciones, tanto manuales como de programa, que se enumeran a continuación. Cada uno de estos parámetros permite que el OCR sea más preciso, y pueden controlarse en la fase previa al OCR o en la fase posterior al OCR, durante el control de calidad.
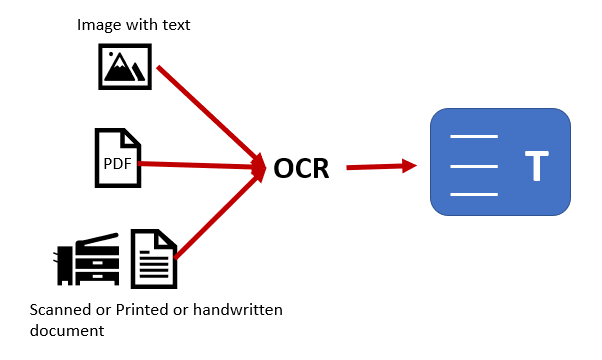
1. Utilizar el Programa Adecuado: PDFelement
El complemento OCR en PDFelementes muy preciso y funciona con varios idiomas, incluso simultáneamente. Además, PDFelement ofrece la conversión a versiones tanto editables como con capacidad de búsqueda del archivo PDF original. También puede crear directamente un PDF utilizando la entrada de un escáner, así como convertir formatos de archivo que no sean de texto en PDF editables/con capacidad de búsqueda.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
2. Los Parámetros de Escaneo Adecuados
Al escanear documentos, es importante establecer los parámetros correctos en la configuración del escáner. Algunos de ellos son: El más importante es la orientación. Asegúrate de que el documento se introduce en el escáner en el ángulo correcto, ya que un escaneo sesgado puede afectar seriamente a la precisión del OCR.
3. Configurar la Resolución
La mejor resolución para un OCR preciso es de 300 ppp o puntos por pulgada. Esta mayor densidad permite un escaneo más "ajustado", permitiendo que el motor de OCR trabaje con el doble de puntos de referencia en comparación con los 150 ppp.
4. Selección del Modo de Color
En el caso de documentos descoloridos o antiguos, el modo de color recomendado es el RGB para que el escáner pueda capturar completamente el contenido del documento físico. En general, sin embargo, el escaneo en modo de escala de grises es la mejor opción para la precisión del OCR. Aunque el modo de blanco y negro ayuda a que la imagen se escanee a mayor velocidad, esto podría afectar a la calidad del reconocimiento de texto.
5. Ajustes de Brillo y Contraste
Para el brillo, ambos extremos (demasiado alto o demasiado bajo) pueden afectar negativamente a la calidad y precisión del OCR. Por ello, el ajuste de brillo recomendado es del 50%. Sin embargo, esto también depende del propio escáner, por lo que cabe esperar una fase inicial de prueba y error.
En cuanto al contraste, se suele preferir el ajuste más alto porque el OCR funciona esencialmente analizando las zonas oscuras y claras para identificar los caracteres individuales. A continuación, se aplican reglas para hacer coincidir estos resultados con caracteres, textos y números conocidos. Si el contraste entre la parte oscura del texto es alto en relación con las partes no textuales circundantes, el OCR es más preciso.
6. Corrección y Descontaminación de la Imagen
Estos dos componentes tienen un gran impacto en la calidad del escaneo OCR. La corrección de la imagen abarca aspectos como el aumento de la resolución, la aplicación de correcciones de color y la prueba de diferentes ajustes de contraste, mientras que la descontaminación implica la eliminación de caracteres no textuales, como iconos, imágenes no textuales, caracteres inusuales, etc. Ambas cosas son importantes porque permiten al motor de OCR "leer" el documento con mayor precisión.
7. Corrección Manual Cuidadosa
Dependiendo del grado de precisión que desees obtener en el resultado final, la corrección manual puede ser necesaria o no. Si la precisión es primordial, es un paso indispensable en el proceso de digitalización de archivos. Básicamente, consiste en la verificación humana para garantizar que los caracteres escaneados se reconocen correctamente en el contexto de la imagen escaneada. Es un proceso tedioso y minucioso pero esencial en muchos casos.
PDFelement: el Mejor Programa de OCR para la Digitalización de Archivos
PDFelement ofrece un motor de OCR muy preciso, pero también aporta otras ventajas cuando se trata de la digitalización de archivos. Estas son algunas de las características que lo convierten en el programa perfecto para el OCR de documentos PDF y escaneos.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
- Capacidades de Edición Completas: Una vez convertido en un PDF editable, un documento puede modificarse fácilmente utilizando las herramientas de edición para imágenes, texto, tablas, gráficos, pies de página/cabeceras, marcas de agua, hipervínculos y otros contenidos.
- OCR Multilingüe: Si tienes un documento con más de un idioma, puedes utilizar PDFelement con confianza para el proceso de OCR. Es compatible con más de 20 idiomas, lo que ayuda a aumentar la precisión general del reconocimiento de texto.
- Proceso Por Lotes: El OCR puede realizarse en un lote de documentos, ahorrando así tiempo en el proceso de archivo digital.
- Anotaciones: Los archivos convertidos pueden ser anotados con notas, resaltados y otros contenidos, lo que ayuda al proceso de indexación. La lista de anotaciones y el diseño con pestañas de PDFelement facilitan las referencias cruzadas de los textos cuando se investiga un tema concreto utilizando archivos con OCR.
- Firma Electrónica y Seguridad: Los archivos pueden ser firmados digital o electrónicamente, así como protegidos contra la visualización o edición no autorizada mediante el cifrado basado en una contraseña. Esto ayuda a validar la autenticidad de un documento y evita que se realicen cambios. La censura es otra función útil que los usuarios pueden utilizar para evitar que la información sensible se pueda buscar.
- Organización de Archivos y Páginas: Formas sencillas de dividir y fusionar archivos, crear carteras de PDF, comparar documentos después de OCR, añadir/eliminar/reordenar páginas, extraer páginas, etc.
- Reducción del Tamaño de los Archivos: La función de optimización de PDF en PDFelement ayuda a los archiveros a almacenar grandes cantidades de información de manera muy eficiente.
Por estas y otras razones, PDFelement está considerado como uno de los mejores editores de PDF para OCR y tareas relacionadas. El programa es también una de las utilidades PDF premium más asequibles para las pequeñas empresas, así como para las organizaciones de nivel empresarial, por lo que es una solución viable para las empresas, instituciones educativas y todo tipo de entidades de los sectores gubernamental, público y privado.