La extracción de datos con IA permite que el software lea, identifique y estructure automáticamente la información de facturas, contratos y documentos escaneados, sin necesidad de introducción manual campo a campo.
Esta guía explica qué es, cómo se diferencia del OCR tradicional, qué tipos de herramientas existen en el mercado y qué criterios usar para elegir la solución adecuada para tu organización.
En este artículo
- Qué es la extracción de datos con IA
- Por qué las herramientas tradicionales de extracción de datos llegan a sus límites
- Cómo la IA mejora los flujos de trabajo de extracción de datos
- Qué no puede automatizar completamente la IA (todavía)
- Tipos de herramientas de extracción de datos con IA
- Características clave de un software de extracción de datos con IA
- Cómo usar PDFelement para la extracción de datos asistida por IA [Recomendado]
- Las 5 mejores herramientas con IA para extraer datos de archivos PDF
- Herramientas gratuitas vs. software profesional de extracción de datos con IA
- La extracción de datos con IA en los flujos de trabajo empresariales
- Conceptos erróneos frecuentes sobre la extracción de datos con IA
- Conclusión: cómo elegir el enfoque de extracción de datos con IA adecuado para tu organización
Qué es la extracción de datos con IA
La extracción de datos con IA es la capacidad que tiene un software de leer documentos —en cualquier formato— e identificar, capturar y estructurar la información útil de forma automática. A diferencia de la automatización básica por reglas, estos sistemas reconocen patrones, estructuras y relaciones dentro del contenido antes de extraer los campos clave con precisión.
Este enfoque se enmarca dentro de lo que el sector denomina Procesamiento Inteligente de Documentos (IDP): una categoría de tecnología que combina inteligencia artificial, OCR y procesamiento del lenguaje natural (NLP) para transformar documentos no estructurados en datos utilizables.
Extracción tradicional frente a extracción basada en IA
Los sistemas tradicionales operan sobre plantillas rígidas, coordenadas exactas y coincidencias de palabras clave: si el diseño cambia, el sistema falla. La extracción con IA trabaja de forma distinta: en lugar de buscar un campo en una posición fija, entiende el contexto. Sabe que un número situado junto a "Total" probablemente corresponde al importe a pagar, no a un código de referencia. Esta comprensión contextual, potenciada por modelos de lenguaje (LLM) y aprendizaje automático, permite procesar archivos semiestructurados y no estructurados con una fiabilidad que los sistemas basados en reglas no pueden igualar.
Aunque los avances son notables, la extracción con IA sigue requiriendo supervisión humana para excepciones, entradas inusuales y decisiones de negocio complejas. El apartado 4 detalla los límites concretos de la automatización actual.
Por qué las herramientas tradicionales de extracción de datos llegan a sus límites
A medida que las empresas procesan mayores volúmenes de documentos y trabajan con fuentes más diversas, las limitaciones de los sistemas clásicos se hacen evidentes:
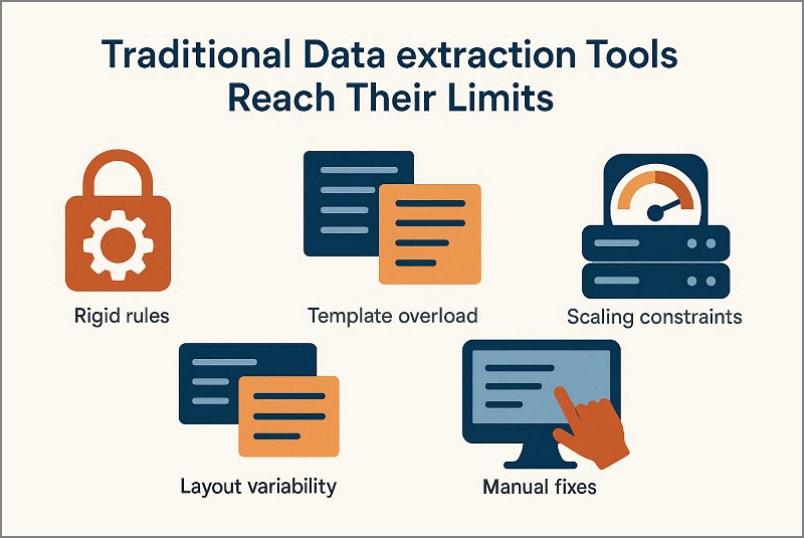
- Reglas rígidas: Los sistemas basados en reglas dependen de palabras clave fijas y posiciones exactas de los campos. Cualquier cambio menor en el formato reduce de inmediato la precisión y la fiabilidad.
- Sobrecarga de plantillas: Cada diseño de documento requiere su propia configuración. Mantener decenas de plantillas distintas aumenta la carga de trabajo técnico y los costes de mantenimiento continuo.
- Variabilidad de diseño: Los proveedores diseñan sus documentos con estructuras y estilos muy diferentes entre sí. El simple desplazamiento de un campo interrumpe el rendimiento de los sistemas tradicionales.
- Correcciones manuales constantes: Los empleados dedican tiempo a revisar y corregir resultados incorrectos. Estos ajustes repetidos reducen la eficiencia operativa y retrasan los flujos de trabajo.
- Escasa escalabilidad: Un incremento en el volumen de documentos presiona los sistemas heredados hasta el punto de colapso cuando crece también la variación estructural.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Cómo la IA mejora los flujos de trabajo de extracción de datos
La extracción de datos con IA —apoyada en NLP y modelos de lenguaje de última generación— transforma los flujos de trabajo documentales en cuatro dimensiones concretas:
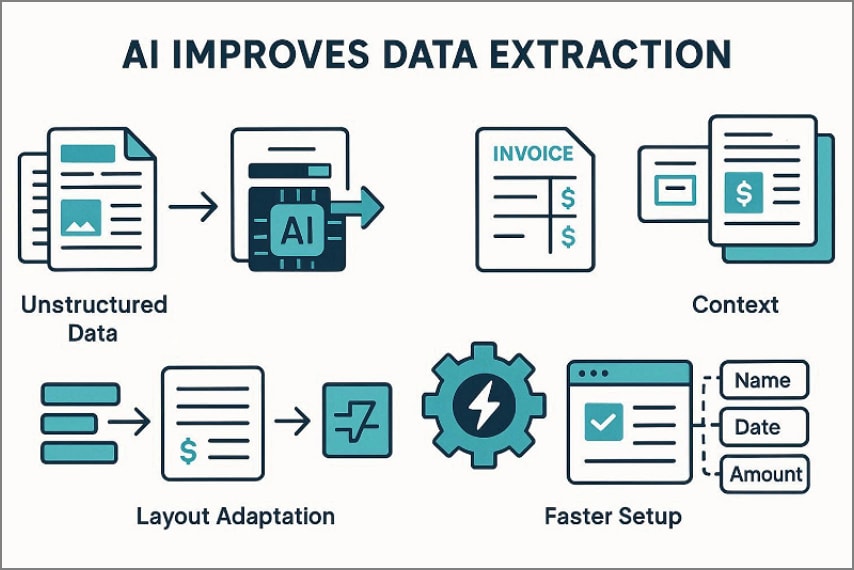
Capacidad para manejar datos no estructurados y semiestructurados
A diferencia de las herramientas basadas en plantillas, la IA aprende patrones a partir de ejemplos y los aplica a documentos que nunca ha procesado antes. Puede capturar campos de correos electrónicos, escaneos y PDFs con diseños inconsistentes, manteniendo la extracción estable incluso cuando el texto está parcialmente ilegible o incompleto.
Interpretación del contexto del documento
La IA no solo lee texto visible: interpreta el contexto. Distingue un número de factura de una referencia de pedido porque entiende las relaciones semánticas entre las etiquetas y los valores del documento. Este nivel de comprensión contextual produce resultados más limpios y reduce las correcciones posteriores.
Adaptación a cambios de diseño sin intervención manual
Cuando un proveedor rediseña su plantilla o un nuevo formato entra en circulación, las herramientas basadas en reglas suelen fallar de inmediato. La extracción con IA reconoce las relaciones entre etiquetas y valores —no sus posiciones fijas— y sigue funcionando con mínimas interrupciones. Esta resiliencia reduce el tiempo de mantenimiento y evita la acumulación de errores silenciosos.
Reducción del tiempo de configuración
En lugar de construir reglas manualmente para cada formato nuevo, los equipos proporcionan ejemplos representativos y el modelo aprende de ellos. El resultado es una implementación más ágil, con menores exigencias técnicas y actualizaciones más sencillas a medida que los formatos evolucionan.
Qué no puede automatizar completamente la IA (todavía)
La extracción de datos con IA mejora considerablemente la velocidad y la consistencia, pero existen escenarios donde la intervención humana sigue siendo imprescindible:
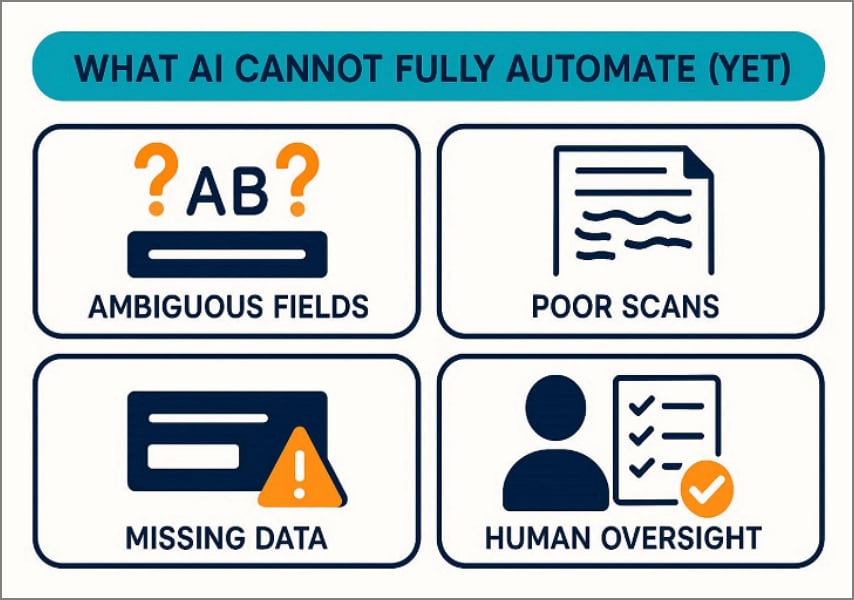
- Campos ambiguos: Cuando etiquetas similares tienen significados distintos según el contexto del negocio, el juicio humano es necesario para resolver la ambigüedad con precisión.
- Escaneos de baja calidad: Las imágenes borrosas o distorsionadas reducen significativamente la precisión del OCR. En estos casos, un revisor experimentado debe interpretar el documento con criterio propio.
- Datos incompletos o ausentes: Los registros con campos vacíos no pueden extraerse de forma fiable. Es necesario verificar la información faltante mediante validaciones externas o consulta directa.
- Decisiones que requieren contexto de negocio: La automatización agiliza los flujos de trabajo, pero no garantiza siempre decisiones correctas en situaciones complejas. Revisores cualificados aseguran el cumplimiento normativo y la aprobación final responsable.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Tipos de herramientas de extracción de datos con IA
Antes de elegir una solución, conviene conocer las categorías disponibles, ya que varían significativamente en su nivel de control, facilidad de configuración y flexibilidad:
Software para el usuario final (sin código)
Diseñado para equipos de negocio que necesitan flujos de trabajo guiados y accesibles. Ofrecen configuración visual, vistas previas en tiempo real y colas de revisión para correcciones. Permiten implementar procesos de extracción sin depender del departamento de TI, con paneles de control que facilitan el seguimiento y la exportación de resultados.
APIs de extracción con IA para desarrolladores
Orientadas a equipos de ingeniería que requieren mayor control sobre la integración. Exponen endpoints para extracción, clasificación, validación y puntuación de confianza, y permiten conectar las salidas directamente a bases de datos, ERPs y servicios internos. Son la opción idónea cuando los formatos son muy específicos o los flujos de trabajo empresariales son complejos.
Plataformas híbridas que combinan OCR, reglas e IA
Estas soluciones integran la precisión del OCR, la estabilidad de las reglas predefinidas y la capacidad interpretativa de la IA. Son especialmente útiles para organizaciones que trabajan tanto con plantillas predecibles como con documentos de diseño variable, ya que equilibran velocidad, precisión y control sobre sus flujos documentales.
Características clave de un software de extracción de datos con IA
A la hora de evaluar plataformas, estas son las características que realmente marcan la diferencia entre una solución fiable y una que genera más problemas de los que resuelve:
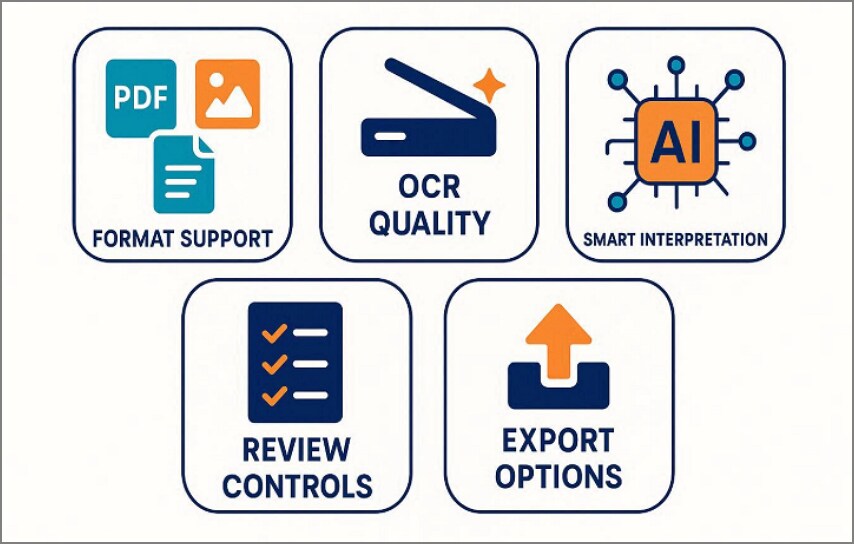
- Compatibilidad de formatos: El software debe procesar PDFs nativos, escaneos, imágenes y adjuntos de formato mixto sin interrupciones frecuentes. Una compatibilidad amplia garantiza consistencia entre departamentos y fuentes de documentos distintas.
- Calidad del OCR: Un motor OCR robusto mejora el reconocimiento de caracteres en documentos difíciles. El preprocesamiento —corrección de inclinación, reducción de ruido, mejora de contraste— es tan importante como el reconocimiento en sí.
- Interpretación inteligente del contexto: La IA debe entender el significado de los valores, no solo leerlos de forma aislada. Esta capacidad reduce el esfuerzo de corrección y eleva la precisión en documentos complejos.
- Herramientas de revisión y validación: Los flujos de revisión y los registros de auditoría permiten a los equipos confirmar los resultados antes de enviar los datos. Son fundamentales para el cumplimiento normativo, incluida la conformidad con el RGPD en el ámbito europeo.
- Opciones de integración: Las exportaciones deben conectarse con hojas de cálculo, bases de datos, sistemas CRM y ERP. Las integraciones mediante API permiten automatizar el flujo completo de datos sin intervención manual entre sistemas.
Cómo usar PDFelement para la extracción de datos asistida por IA
Las empresas procesan a diario contratos, facturas, informes y documentos escaneados. Extraer información útil de estos archivos de forma manual es lento, costoso y propenso a errores. PDFelement ofrece capacidades de extracción asistida por IA que agilizan el procesamiento documental sin renunciar al control del usuario en ninguna fase del flujo de trabajo.



A diferencia de las soluciones que requieren plantillas rígidas, PDFelement se adapta a la variabilidad real de los documentos. Extrae información de PDFs nativos, documentos escaneados e imágenes desde una interfaz unificada, con OCR integrado y funciones avanzadas de IA que permiten revisar, refinar y exportar los resultados de forma eficiente.
Extracción de datos desde PDFs, documentos escaneados e imágenes
PDFelement permite extraer datos de PDFs nativos, contratos escaneados e imágenes sin necesidad de herramientas adicionales. Incluye soporte para el procesamiento de recibos y facturas electrónicas, lo que lo hace especialmente útil en entornos donde la digitalización de documentos fiscales es una exigencia operativa. Los equipos pueden cargar documentos de tipos distintos y procesarlos de manera consistente desde una sola interfaz.
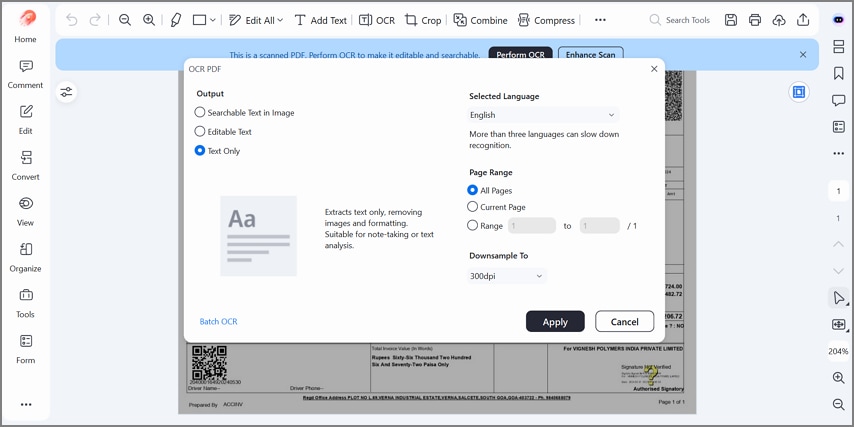
OCR para archivos basados en imágenes
Para documentos escaneados o fotografiados, el OCR integrado convierte las imágenes en texto editable y procesable. El sistema aplica mejoras previas al reconocimiento —corrección de orientación, reducción de ruido— para maximizar la precisión incluso en escaneos de baja calidad.
Funciones impulsadas por IA
PDFelement va más allá de la extracción básica al incorporar herramientas de IA que permiten una comprensión más profunda del contenido documental:
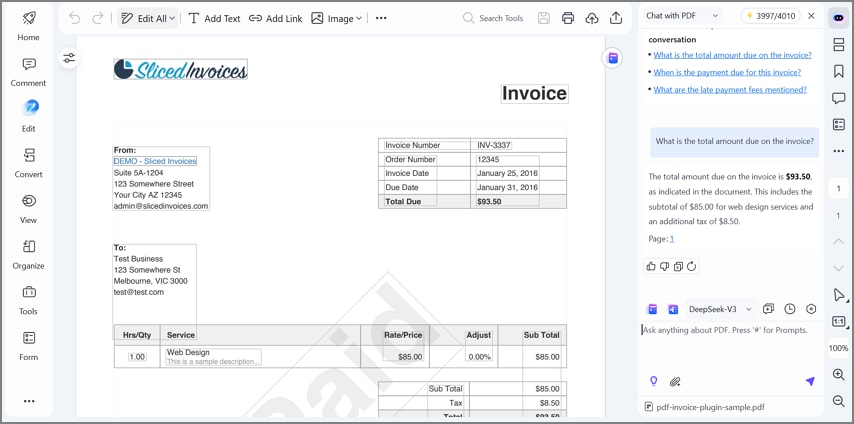
Chat con PDF para preguntas contextuales
La función Chat con PDF permite formular preguntas directas sobre el contenido del documento y recibir respuestas contextuales al instante. Es especialmente útil para confirmar valores extraídos en archivos extensos o con terminología técnica, sin necesidad de navegar manualmente entre páginas.
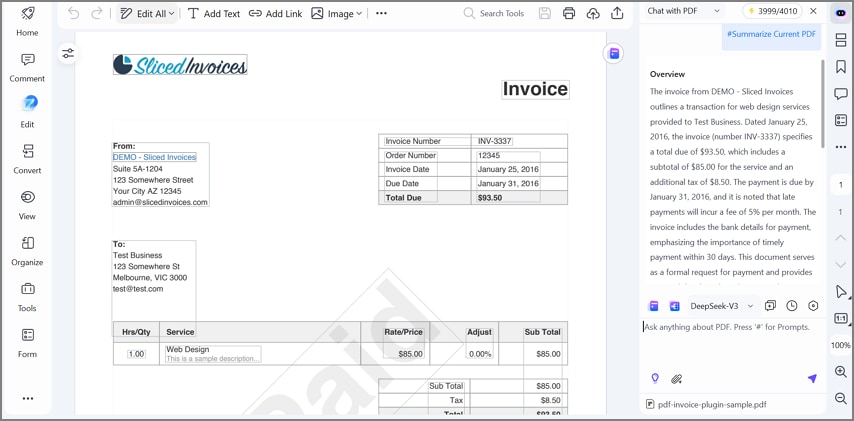
Resumen e interpretación con IA
La función de resumen con IA condensa la información extraída en ideas claras y jerarquizadas, destacando los puntos clave, totales y referencias más relevantes. Esto acorta los tiempos de revisión y mejora la claridad en los informes internos, donde la rapidez de interpretación es crítica.
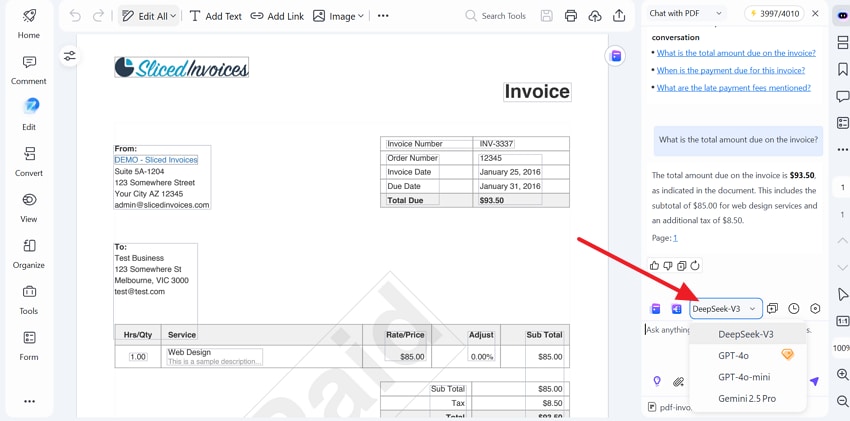
Compatibilidad con múltiples modelos de IA
PDFelement es compatible con modelos de IA de última generación como GPT-4o, Gemini y DeepSeek. Esta flexibilidad permite a las organizaciones elegir el modelo que mejor se alinee con sus políticas internas de IA o sus requisitos de cumplimiento, y adaptarse a medida que el ecosistema tecnológico evoluciona.
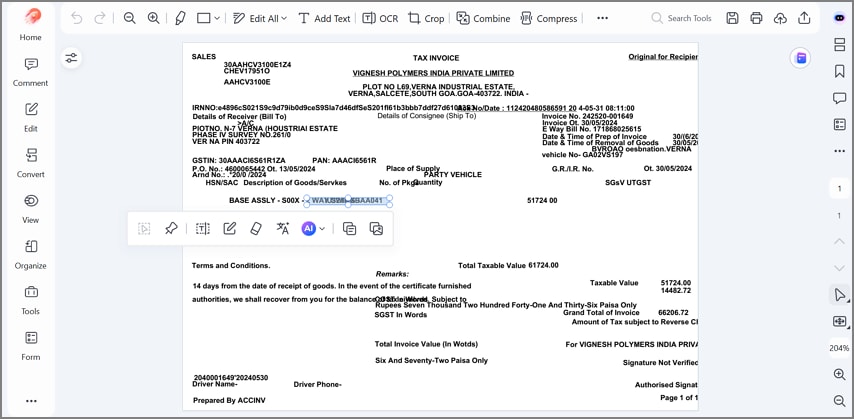
Revisión y corrección manual antes de exportar
Antes de exportar los resultados, los usuarios pueden revisar y editar los campos extraídos con herramientas de validación integradas. Este paso garantiza la conformidad con los estándares de calidad y las normativas aplicables, sin sacrificar la eficiencia que aporta la automatización.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Las 5 mejores herramientas con IA para extraer datos de archivos PDF
Consulta las 5 herramientas para extraer datos de PDF con la máxima eficacia
1. Extractor IA de datos Wondershare PDFelement

Wondershare PDFelement tiene funciones de ROC y extracción de datos. Su integración con la IA ha facilitado el uso de estas funciones. Consulta a Lumi, el asistente de IA de Wondershare PDFelement, cómo extraer datos de un PDF.
Lumi escribirá un tutorial e incluso te mostrará las funciones que puedas necesitar. Para activar la función, puedes hacer clic en el botón correspondiente de la barra lateral IA.
Reseña en G2: 4.5 / 5 estrellas - 584 opiniones
Precio:
- Plan anual - $79.99 dólares
- Plan de 2 años - $109.99 dólares
- Plan permanente - $129.99 dólares
Opinión del usuario:
Mohammad Adeeb S. en G2: Lo mejor de PDFelement es la facilidad con la que puedo extraer los datos, rediseñar los elementos y volver a unirlos. Con una interfaz sencilla, podemos crear rápidamente archivos PDF desde cero, editarlos/escanearlos y anotar/añadir comentarios en ellos. Es una herramienta rentable que resulta increíblemente asombrosa a la hora de convertir documentos a formatos de oficina.

2. Extractor de datos Parseur
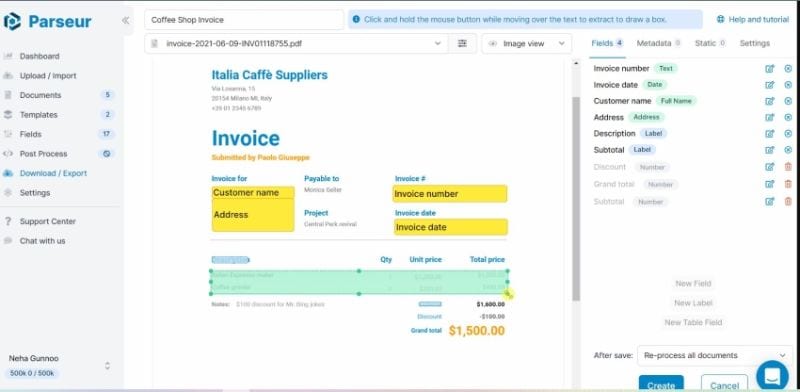
Parseur es un analizador sintáctico de documentos que aprovecha el poder de la IA. Utilizando tecnología de IA, esta herramienta puede automatizar la extracción de datos PDF. Dispone de ROC IA, ROC por zonas y ROC dinámico. Permiten extraer datos con gran precisión. Parseur también proporciona plantillas y campos ya configurados, que facilitan el proceso en la extracción de datos.
Además, a diferencia de otros motores de análisis gramatical, no intervienen reglas de codificación ni de análisis sintáctico. Parseur funciona con un sistema "apuntar y hacer clic".
Reseña en G2: 4.9 / 5 estrellas - 15 opiniones
Precio:
- 100 créditos/mes - $39 dólares
- 300 créditos/mes - $69 dólares
- 1,000 créditos/mes - $99 dólares
- 3,000 créditos/mes - $199 dólares
- 10,000 créditos/mes - $299 dólares
- 100,000 créditos/mes - $1,999 dólares
- 1,000,000 créditos/mes - $9.999 dólares
Opinión del usuario:
Usuario verificado de un consultorio médico en G2: "He estado utilizando el software de la competencia durante bastante tiempo y me pareció muy complicado. Después de pasar horas configurando tareas sencillas, me encantó encontrar Parseur. Se pueden configurar tareas complicadas en cuestión de minutos y su equipo de asistencia técnica está a mano para resolver cualquier duda más complicada. Recomiendo encarecidamente este programa y desearía haberlo encontrado antes".
3. AlgoDocs - Herramienta para extraer datos
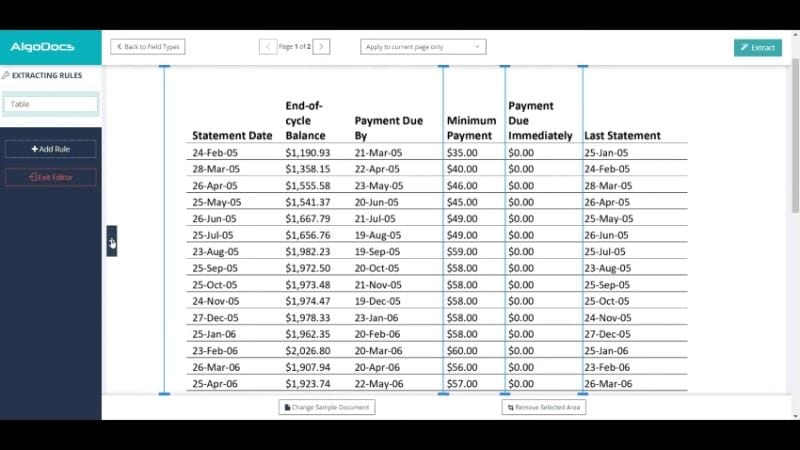
AlgoDocs es una gran herramienta de IA para contadores y gente de negocios. Se pueden extraer datos de recibos, nóminas, facturas en PDF y mucho más. El extractor de IA puede extraer campos o tablas específicos de dichos documentos. Luego, puedes elegir guardar los datos extraídos como un archivo Excel. Otra posibilidad es enviarlo al programa de contabilidad que utilice tu empresa. Dispone de muchas integraciones, así que es muy probable que eso sea posible.
Reseña en G2: 4.8 / 5 estrellas - 3 opiniones
Precio:
- Básico - $23 dólares/mes
- Empresas - $84 dólares/mes
- Ultimate - $175 dólares/mes
Opinión del usuario:
Shawna F. sobre G2: "Me gusta la fluidez y la transición al uso del programa. Es muy fácil de entender, así como aplicar mi trabajo. Lo mejor es que se puede comparar con otros que existen, aunque los supera y satisface plenamente mis necesidades."
4. Iris.ai Extract Tool

Iris.ai Extract es un extractor de datos avanzado que utiliza una potente IA. ¡Es capaz de extraer texto de tablas y campos de un PDF o de cientos de ellos por lotes! La herramienta Extraer rellena los datos extraídos con un fichero legible por máquina. Esto podría ser un archivo Excel, una herramienta de laboratorio integrada o una base de datos. Debido a su gran potencia, pero también a su elevado coste, Iris.ai se recomienda sobre todo a investigadores y empresas.
Precio:
- Mensual - $79.36 dólares
- Trimestral - $214.28 dólares
- Anual - $761.89 dólares
5. Parsio GPT-Powered Parser
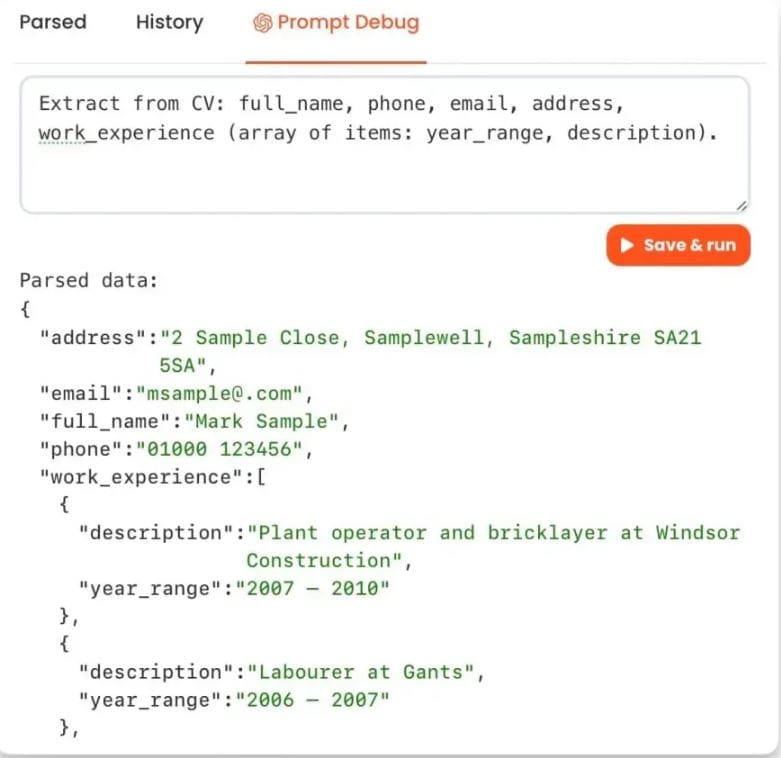
Parsio GPT-Powered Parser, como su nombre indica, utiliza la API de ChatGPT. Por tanto, extraer datos de esta herramienta es como hablar con una persona. Basta con que describas a la herramienta la extracción de datos deseada. No implica complicadas reglas de análisis ni plantillas. La herramienta hará su magia y, cuando termine, podrás exportar a Google Sheets o a webhooks.
Reseña en G2: 4.8/5estrellas - 5 opiniones
Precio:
- Principiante - $41dólares/mes
- Crecimiento - $124 dólares/mes
- Empresas - $249 dólares/mes
Opinión del usuario:
Varvara A. en G2: "Si utilizas Zapier, Integromat, Integrately, Konnectzit, Pabbly Connect, SyncSpider y con frecuencia necesitas analizar correos electrónicos entrantes y archivos PDF adjuntos, Parsio es realmente lo que necesitas. Su interfaz es muy intuitiva, resulta muy fácil y rápido. Una solución increíble para todos los que se dedican a la automatización empresarial. ¡Estoy ansioso por ver cómo evoluciona!"
Herramientas gratuitas vs. software profesional de extracción de datos con IA
Antes de elegir una solución, es importante conocer las diferencias prácticas entre las opciones disponibles. La siguiente tabla resume en qué contextos rinden bien las herramientas gratuitas y cuándo el software profesional ofrece mayor valor a largo plazo:
| Criterio | Herramientas gratuitas | Software profesional |
| Casos de uso | Pruebas puntuales, tareas ocasionales, documentos simples | Flujos de trabajo diarios, grandes volúmenes, documentos variados |
| Precisión | Variable en diseños complejos y escaneos difíciles | Más estable, con validación y modelos más avanzados |
| Límites de archivos | Restricciones de tamaño, páginas o uso diario | Archivos grandes, procesamiento por lotes y mayor capacidad |
| Privacidad y cumplimiento | Gestión de datos poco transparente, sin opciones de control avanzado | Controles de seguridad más estrictos, conformidad con RGPD y normativas empresariales |
| Integraciones | Formatos de exportación limitados, sin conexión a sistemas externos | API, exportaciones avanzadas e integración con ERP, CRM y contabilidad |
| Cuándo actualizar | Cuando los errores, los límites o los riesgos de privacidad ralentizan el trabajo | Cuando la precisión, la escalabilidad y el cumplimiento son requisitos de negocio |
Cuándo se vuelve necesario el software profesional
Las herramientas gratuitas son una buena opción para exploraciones iniciales o tareas de bajo volumen. Sin embargo, cuando la precisión constante, la trazabilidad de los datos y el cumplimiento normativo pasan a ser requisitos operativos, el software profesional deja de ser una opción y se convierte en una necesidad. Especialmente en sectores como finanzas, legal o sanidad, donde los errores en la extracción de datos tienen consecuencias directas sobre el negocio.
La extracción de datos con IA en los flujos de trabajo empresariales
La extracción de datos con IA no es el destino final del procesamiento documental: es el punto de partida que alimenta de información precisa a todos los sistemas posteriores. Cuando los datos se estructuran correctamente desde el origen, los equipos evitan retrasos, eliminan la introducción manual repetida y reducen los errores que se propagan aguas abajo.
Informes y análisis de negocio
Los datos extraídos alimentan paneles de control, informes de rendimiento y análisis de tendencias. Los equipos financieros pueden rastrear gastos, impuestos y totales por proveedor con mayor precisión; los de operaciones monitorean volúmenes, tiempos de ciclo y tasas de excepción con mayor facilidad. El resultado es que los responsables de tomar decisiones trabajan con cifras fiables, no con estimaciones.
Importación a hojas de cálculo y bases de datos
La extracción con IA convierte documentos en filas y columnas de forma automática. Los equipos pueden importar líneas de facturas a hojas de cálculo o almacenar registros estructurados en bases de datos para su uso a largo plazo, sin teclear campo a campo. Esto mejora la consistencia, reduce los errores humanos y facilita una gestión de datos más ordenada y auditable.
Automatización con plataformas RPA y sistemas integrados
Los datos extraídos pueden activar flujos de trabajo en aplicaciones empresariales conectadas mediante RPA (Automatización Robótica de Procesos). Una factura aprobada puede registrarse automáticamente en el sistema contable; un formulario de cliente puede actualizar el CRM; una reclamación puede entrar directamente en la cola de procesamiento del ERP. La automatización funciona mejor cuando los sistemas reciben entradas de datos estandarizadas y de alta calidad.
Por qué una extracción limpia es la base de todo
La calidad de cada paso posterior —informes, automatizaciones, integraciones— depende directamente de la fiabilidad de la extracción inicial. Si los datos capturados son incorrectos o incompletos, los errores se multiplican a lo largo de toda la cadena. Una extracción limpia genera confianza en los procesos, reduce el retrabajo y hace que los flujos de trabajo sean predecibles y sostenibles.
Conceptos erróneos frecuentes sobre la extracción de datos con IA
Antes de adoptar una solución de extracción de datos con IA, conviene desmontar algunas ideas preconcebidas que generan expectativas poco realistas y llevan a decisiones de compra equivocadas:
- «La IA elimina toda revisión manual»: En la práctica, los documentos complejos o sensibles siempre requieren supervisión humana. La IA reduce la carga, pero no la elimina.
- «Los datos extraídos serán perfectos»: Diseños confusos, campos ambiguos o escaneos deficientes pueden seguir reduciendo la precisión. La validación sigue siendo necesaria.
- «La implementación es inmediata»: La mayoría de las herramientas requieren ejemplos de entrenamiento, configuración inicial y alineación con los flujos de trabajo existentes antes de rendir al máximo.
- «La IA entiende todas las reglas del negocio por defecto»: La interpretación mejora progresivamente cuando los modelos reciben señales contextuales claras y retroalimentación continua del equipo.
- «Una sola solución sirve para cualquier tipo de documento»: Cada sector tiene sus particularidades. Las industrias reguladas —como la sanidad, la banca o el sector legal— necesitan configuraciones adaptadas, reglas de validación específicas y gestión especializada de excepciones.
Conclusión: cómo elegir el enfoque de extracción de datos con IA adecuado para tu organización
La extracción de datos con IA es hoy una solución operativa consolidada. La pregunta ya no es si adoptarla, sino qué combinación de OCR, interpretación contextual y flujos de validación se adapta mejor al volumen, la variabilidad documental y los requisitos normativos de tu organización.
Para equipos que buscan ese equilibrio sin renunciar al control del usuario, PDFelement integra OCR, extracción asistida por IA, chat contextual con documentos y exportaciones directas a los sistemas de trabajo habituales.