¿Alguna vez has querido digitalizar el texto de un documento en papel o de una imagen sin tener que reescribirlo manualmente? La buena noticia es que Google ofrece herramientas gratuitas de OCR que te permiten extraer texto de imágenes en segundos, sin instalar ningún software adicional.
En esta guía completa te explicamos cómo usar el OCR de Google Drive y de Google Keep, los trucos para mejorar la precisión del reconocimiento, y por qué Wondershare PDFelement es la mejor alternativa cuando necesitas procesar PDFs escaneados de forma profesional o por lotes.
¿Qué es el OCR de Google y para qué sirve?
El OCR (Optical Character Recognition o Reconocimiento Óptico de Caracteres) es la tecnología que permite convertir el texto contenido en una imagen o documento escaneado en texto digital editable y buscable. Google ofrece esta función de forma totalmente gratuita a través de varios de sus servicios en la nube.
Las dos herramientas principales de Google con OCR integrado son:
- Google Drive: extrae texto de archivos PDF e imágenes (JPEG, JPG, PNG, GIF, TIFF) abriéndolos con Google Docs.
- Google Keep: aplicación de notas que permite extraer texto de fotos directamente desde el móvil o el navegador.
Ambas funcionan con tu cuenta de Google habitual, son 100 % gratuitas y no requieren instalar ningún programa adicional. Soportan más de 200 idiomas, incluyendo español, inglés, francés, alemán, árabe y muchos más.
Cómo usar Google Drive para extraer texto de imágenes y PDF
Google Drive es mucho más que un almacenamiento en la nube: incluye un motor de OCR muy útil para convertir imágenes escaneadas y PDFs en texto editable. Sigue estos pasos:
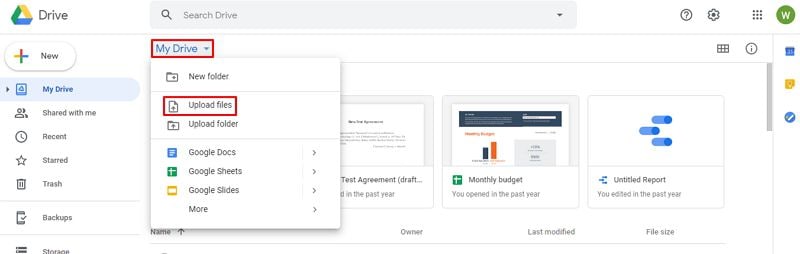
Paso 1.Sube tu imagen o PDF a Google Drive
Accede a drive.google.com con tu cuenta de Google. Haz clic en el botón "Nuevo" o simplemente arrastra y suelta el archivo en la ventana del navegador. Se admiten formatos JPEG, PNG, GIF, TIFF y PDF.
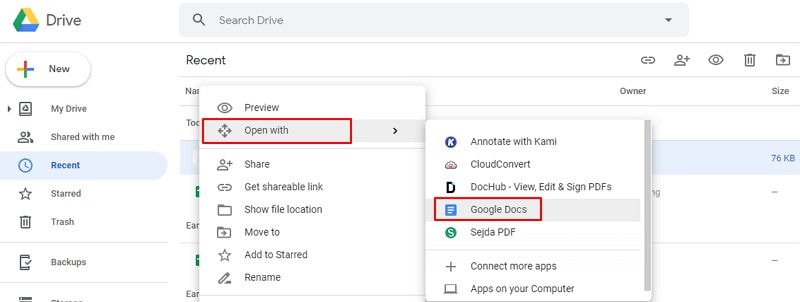
Paso 2.Abre el archivo con Google Docs
Localiza el archivo subido, haz clic derecho y elige "Abrir con" → "Documentos de Google". Google ejecutará automáticamente el OCR y abrirá un nuevo documento con la imagen original arriba y el texto extraído debajo, listo para editar.
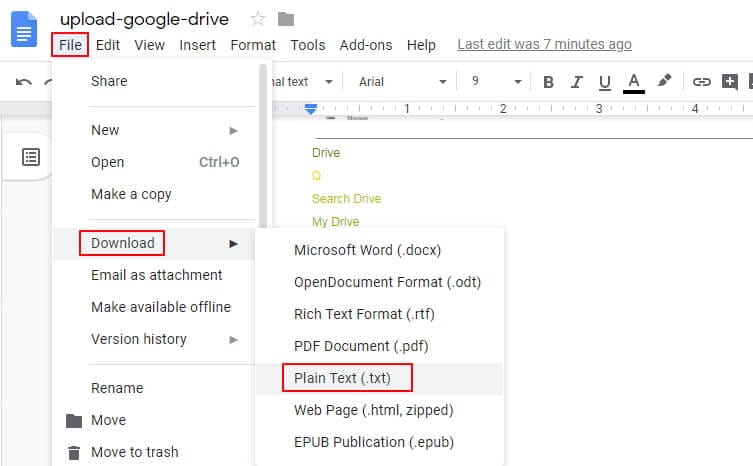
Paso 3.Guarda o exporta el archivo
Haz clic en "Archivo" → "Descargar" y elige el formato que prefieras: Word (.docx), PDF, texto plano (.txt), entre otros. También puedes copiar el texto directamente y pegarlo donde lo necesites.
Consejos para conservar el formato y los caracteres en español
- Si el texto incluye tildes, ñ o caracteres especiales, verifica que la codificación del documento esté configurada en UTF-8.
- Si el texto aparece con caracteres incorrectos, ve a "Herramientas" → "Idioma" y selecciona Español.
- Cuando el formato original se descuadre, copia solo el texto plano y pégalo en un documento nuevo para reorganizarlo.
- Cuanto mayor sea la resolución de la imagen, mejores resultados obtendrás.
Cómo hacer OCR con Google Keep desde el móvil
Google Keep es la aplicación de notas de Google e incluye una función específica para extraer texto de imágenes. Es especialmente útil cuando estás fuera de casa y necesitas digitalizar rápidamente una tarjeta de visita, un cartel o cualquier documento físico desde el móvil.
Paso 1.Sube una imagen a Google Keep
Accede a keep.google.com desde el navegador o abre la app en iOS o Android. Crea una nota nueva y pulsa el icono "Añadir imagen". Puedes seleccionar una foto de tu galería o hacer una nueva con la cámara.
Paso 2.Usa la función "Extraer texto de la imagen"
Abre la nota que contiene la imagen, tócala para ampliarla y, en el menú de tres puntos, elige "Extraer texto de la imagen". El texto reconocido aparecerá automáticamente añadido a la nota, listo para editar, copiar o compartir.
Paso 3.Sincroniza entre dispositivos
Una de las grandes ventajas de Google Keep es la sincronización en la nube: el texto que extraes desde el móvil se muestra al instante en la versión web y en otros dispositivos vinculados a tu cuenta de Google.
Ideal para: digitalizar tarjetas de visita, recibos, notas escritas en pizarras, fragmentos de libros o cualquier documento físico sobre la marcha.
Cómo mejorar la precisión del OCR de Google
Aunque el OCR de Google es bastante preciso, hay varias buenas prácticas que pueden mejorar significativamente el resultado:
1. Usa imágenes nítidas y con buena resolución
- Cuanto más nítida sea la imagen, mejor será el reconocimiento.
- Al fotografiar con el móvil, usa la máxima calidad disponible.
- Asegúrate de que haya buena iluminación, sin sombras ni reflejos.
- Mantén la cámara estable para evitar imágenes borrosas.
2. Mejora la iluminación y el contraste del texto
- Las fuentes sans-serif (Arial, Helvetica, Roboto) se reconocen con más precisión que las decorativas o cursivas.
- El contraste ideal es texto negro sobre fondo blanco.
- Las imágenes en blanco y negro suelen dar mejores resultados que las de color saturado.
3. Evita texto manuscrito borroso, inclinado o poco legible
- El reconocimiento de texto manuscrito es siempre más complicado que el impreso.
- Usa letra de imprenta clara, evitando trazos solapados.
- Deja márgenes adecuados alrededor de cada palabra.
- No mezcles colores ni resaltadores sobre el texto que quieras reconocer.
PDFelement: una alternativa para aplicar OCR a PDF escaneados
Las herramientas de Google son perfectas para tareas puntuales, pero cuando necesitas procesar PDFs escaneados, mantener el formato original, trabajar por lotes o reconocer documentos complejos en español, lo más recomendable es usar un software profesional como Wondershare PDFelement.




Cuándo conviene usar PDFelement en lugar del OCR de Google
- OCR multilingüe de alta precisión: reconoce español, inglés, francés, alemán, portugués, italiano y más de 20 idiomas adicionales.
- OCR por lotes: procesa decenas o cientos de PDFs en una sola operación, ideal para empresas y despachos.
- Conserva el diseño original: mantiene tablas, columnas, imágenes y maquetación tal cual aparecen en el documento escaneado.
- Edición completa post-OCR: modifica textos, añade comentarios, anotaciones, marcas de agua y firma electrónica.
- Exportación versátil: convierte a Word, Excel, PowerPoint, EPUB, HTML, imagen y más.
Cómo aplicar OCR a un PDF escaneado con PDFelement
Paso 1.Abre tu archivo PDF en PDFelement
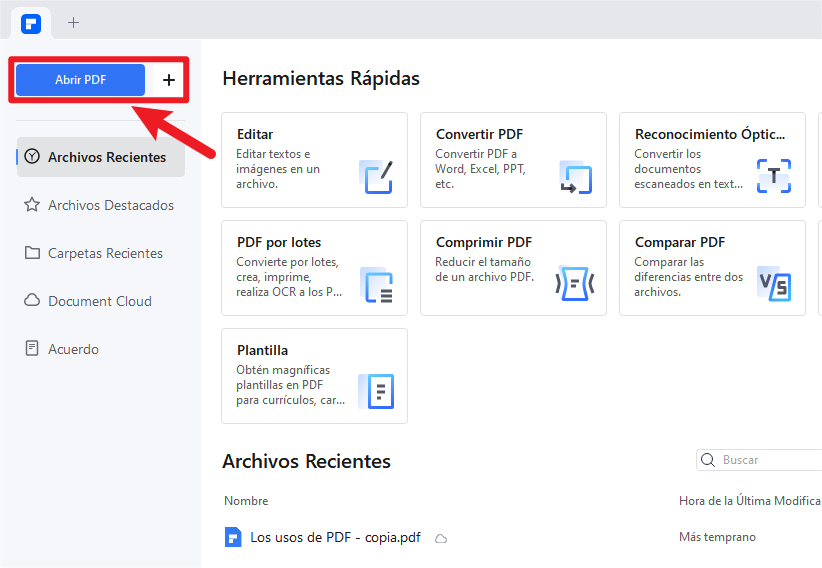
Inicia Wondershare PDFelement en tu Mac o PC con Windows y pulsa "Abrir archivos". También puedes arrastrar varios PDFs a la vez para aplicar OCR por lotes.
Paso 2.Aplica el OCR al documento
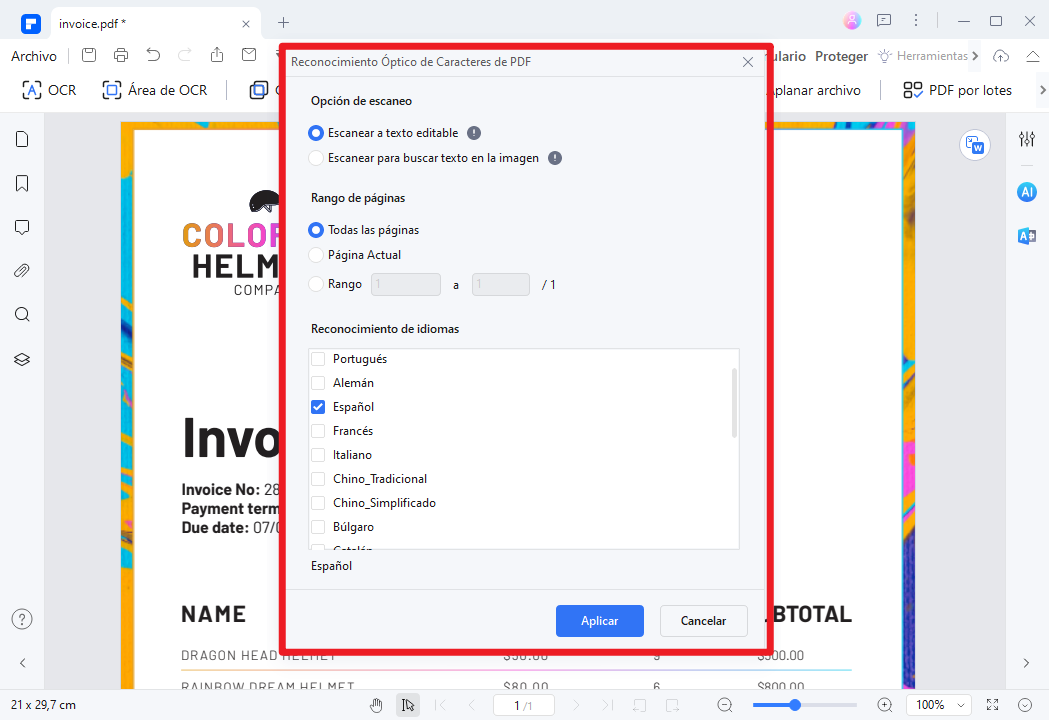
Ve a "Herramientas" → "OCR". Si solo quieres reconocer una parte del documento, usa "OCR Area" para seleccionar la zona específica. Elige "Español" (o el idioma correspondiente) y pulsa "Aplicar". PDFelement procesará el documento y lo convertirá en texto editable y buscable.
Paso 3.Edita y exporta el resultado
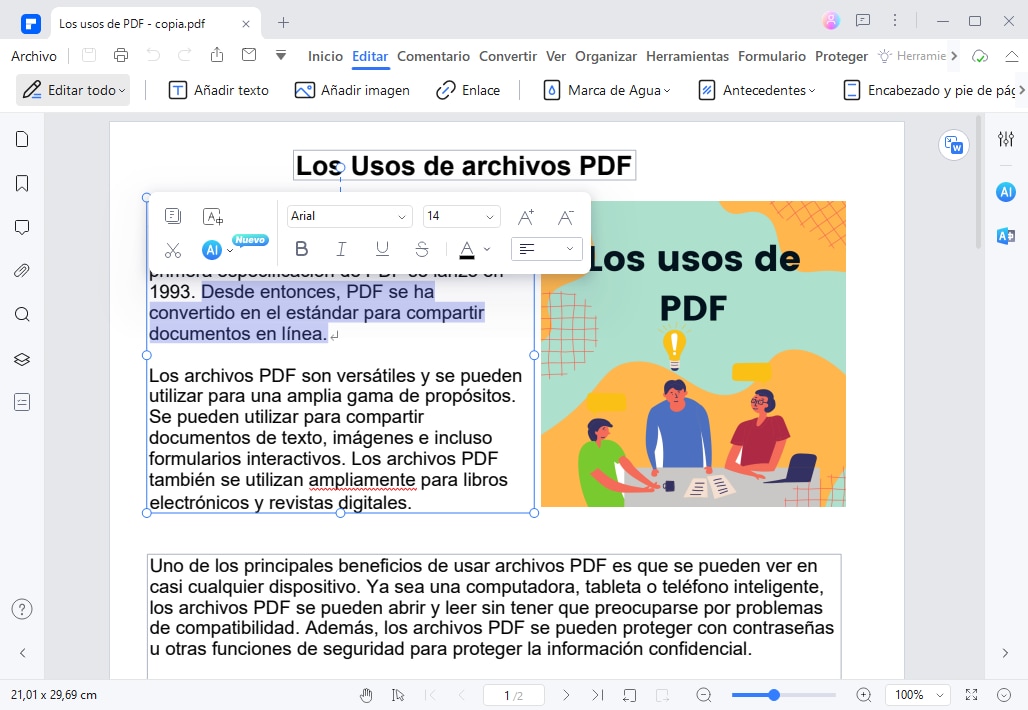
Pulsa "Editar" para modificar textos, añadir imágenes, comentarios o marcas de agua. Cuando termines, haz clic en "Convertir" y selecciona el formato de salida (Word, Excel, PowerPoint, etc.). PDFelement también permite guardar directamente en Google Drive, OneDrive y Dropbox, o imprimir el documento.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Conclusión
Con las herramientas gratuitas de Google —Google Drive y Google Keep— puedes convertir imágenes y PDFs en texto editable en cuestión de segundos, sin instalar software ni pagar suscripciones. Son perfectas para tareas cotidianas como digitalizar tarjetas, recibos o notas manuscritas.
Sin embargo, cuando necesitas procesar PDFs escaneados, mantener el diseño original, aplicar OCR por lotes o trabajar con documentos profesionales en español, Wondershare PDFelement es la alternativa más completa y fiable. Combina OCR de alta precisión, edición avanzada y exportación a múltiples formatos en una sola aplicación.