
¿Alguna vez has intentado copiar texto de un PDF escaneado y descubierto que no puedes hacerlo? DeepSeek OCR soluciona este problema al convertir archivos PDF en texto editable mediante su avanzada tecnología de reconocimiento óptico de caracteres (OCR).
En esta guía aprenderás cómo usar DeepSeek OCR para procesar PDFs largos, conectarte mediante su API OCR o ejecutarlo localmente desde GitHub. Además, descubrirás una alternativa OCR sin código, ideal para limpiar, traducir o extraer texto multilingüe de tus PDFs al instante.
En este artículo
- ¿Qué es DeepSeek OCR?
- DeepSeek OCR API — Cómo utilizarla
- DeepSeek OCR en GitHub — Clonar y ejecutar localmente
- Usando DeepSeek OCR para PDFs
- Ollama + DeepSeek OCR (Idea local-first)
- Un camino más rápido para equipos cotidianos: PDFelement (OCR PDF sin código y limpieza)
- DeepSeek OCR vs PDFelement vs OCR clásico — Cuándo usar cada uno
- Guías paso a paso (listas para copiar)
- Consideraciones conocidas (precisión, seguridad, disponibilidad)
¿Qué es DeepSeek OCR y cómo funciona?
DeepSeek-OCR es un software de código abierto que utiliza "compresión óptica" para procesar enormes documentos con contexto ultralargo. Es ideal para desarrolladores que necesitan extracción a gran escala y está disponible en GitHub con documentación completa de la API en línea. Para la mayoría de los equipos que requieren OCR multilingüe con una interfaz gráfica sencilla, las funciones de OCR y mejora de escaneo de PDFelement son más prácticas. Elige DeepSeek para eficiencia de tokens y PDFelement para extracción y limpieza diaria de texto en PDFs mediante herramientas fáciles de usar.
Este sistema transforma los documentos en tokens visuales compactos y permite un procesamiento de contexto largo ultraeficiente para IA. Conserva la estructura compleja del diseño, reduce el coste de tokens y genera texto listo para análisis. Para ayudar a los modelos de lenguaje a manejar documentos más extensos en una sola pasada, comprime las páginas en una presentación visual. Admite documentos multilingües y de formato mixto en flujos de trabajo de investigación, empresas y desarrolladores. Veamos algunas capacidades y beneficios clave que ofrece esta herramienta.

- Motor de compresión óptica: Convierte páginas en tokens visuales compactos, permitiendo a los modelos de lenguaje procesar contextos mucho más largos.
- Reducción de tokens ×10: Reduce el número de tokens aproximadamente diez veces, manteniendo un reconocimiento sólido en diseños de documentos diversos.
- Procesamiento de alto rendimiento: Proporciona gran rendimiento en cargas de trabajo multipágina usando estrategias optimizadas de mosaico, agrupamiento y caché.
- Modos dinámicos/resolución: Adapta la resolución y vistas para PDFs científicos, facturas, tablas, gráficos y archivos con muchos diagramas.
- Salidas estructuradas: Produce Markdown o JSON estructurado para preservar tablas, listas, gráficos y la jerarquía general del documento.
Puedes explorar el resumen completo de la investigación y ejemplos de código en el repositorio de GitHub y en los artículos técnicos.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Cómo usar la API de DeepSeek OCR paso a paso (con ejemplos)
La API DeepSeek OCR permite a los desarrolladores integrar procesamiento avanzado de documentos en sus flujos de trabajo. Es fácilmente accesible para desarrolladores familiarizados con los SDK de OpenAI, sin requerir comprender un formato API completamente nuevo, gracias a su compatibilidad con OpenAI. Los usuarios pueden enviar páginas escaneadas, imágenes o PDFs y recibir salidas de texto estructurado con esta API. Los resultados están listos para flujos de trabajo de IA, bases de conocimiento o procesos de investigación.
Formato de la API y estructura de las solicitudes
La API utiliza una estructura estándar de solicitudes HTTP compatible con los SDK de estilo OpenAI. Una solicitud típica incluye:
- URL del endpoint: El endpoint de la API al que envías solicitudes para procesar documentos, por ejemplo, https://api.deepseek.com/v1/ocr.
- Cabeceras: Incluye tu token Bearer y cualquier detalle de autenticación requerido para el acceso.
- Archivo de entrada: Proporciona una imagen subida, una página PDF o una URL pública para procesamiento OCR.
- Parámetros opcionales: Especifica idioma, modo de diseño, resolución u otras preferencias para mejores resultados.
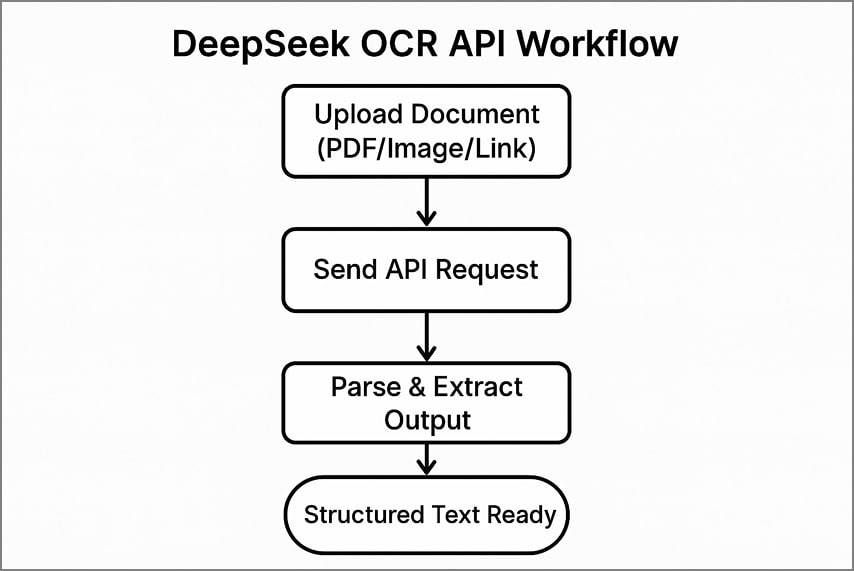
Flujo típico de uso de la API
Utilizar DeepSeek OCR mediante la API implica 3 pasos claros para procesar documentos y extraer texto estructurado.
- Sube tu documento a la API enviando un archivo, una página PDF o un enlace público.
- Envía la llamada a la API con tus cabeceras de autenticación y opciones de procesamiento escogidas.
- Analiza el JSON o texto devuelto para extraer contenido reconocido, detalles de diseño y tokens visuales con precisión.
Límites de uso, disponibilidad y confiabilidad
Aunque la API es potente, los desarrolladores deben tener en cuenta algunas consideraciones operacionales:
- Disponibilidad del servicio: La API ha mostrado fluctuaciones ocasionales en el tiempo de actividad, así que planifica posibles tiempos de inactividad o respuestas lentas en producción.
- Límites de uso: Al procesar a gran escala puede alcanzarse un límite diario o por minuto, debiendo reintentar para mantener la continuidad.
- Gestión de errores: Revisa siempre las respuestas en busca de errores y maneja las excepciones para evitar que los flujos de trabajo fallen en producción.

DeepSeek OCR en GitHub: clonar, instalar y ejecutar localmente
Exploraremos cómo puedes instalar DeepSeek OCR de GitHub localmente configurando el entorno Python después de clonar el repositorio.
Accediendo al repositorio
DeepSeek OCR está disponible como proyecto de código abierto en GitHub y brinda a los desarrolladores acceso completo a su arquitectura y scripts. El repositorio incluye archivos de configuración de entorno y documentación para desplegar o personalizar. Distribuido bajo una licencia permisiva, admite tanto investigación como uso en producción. El proyecto cuenta con una comunidad activa que contribuye frecuentemente con correcciones de errores y mejoras de flujo de trabajo para despliegues locales.

Configuración local (comandos paso a paso)
Para instalar DeepSeek OCR localmente, simplemente clona el repositorio y prepara tu entorno de Python:
"git clone https://github.com/deepseek-ai/DeepSeek-OCR
cd DeepSeek-OCR
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install -r requirements.txt"
La herramienta es compatible con Python versión 3.9 o posterior. Los pesos del modelo pueden descargarse automáticamente al primer uso o manualmente mediante enlaces en el archivo README.
Requisitos de GPU y notas de rendimiento
DeepSeek OCR puede ejecutarse en CPU, aunque se recomienda fuertemente una GPU compatible con CUDA para cargas de trabajo OCR de alto volumen. En comparaciones internas, el rendimiento puede ser de 5 a 10 veces mayor en PDFs multipágina o diseños complejos usando aceleración por GPU. Para un rendimiento óptimo, asegúrate de tener actualizados tus drivers NVIDIA, CUDA y versiones de PyTorch.
Realizando inferencias en PDFs
Después de completar la configuración, prueba un archivo PDF de muestra utilizando el siguiente comando:
"python infer.py --input sample.pdf --output output.json"
Cada página se procesa como imagen mediante el pipeline de visión VL2 para detectar texto y preservar el diseño. La salida estructurada en JSON o Markdown se integra en flujos de trabajo locales basados en RAG u Ollama.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Procesar archivos PDF con DeepSeek OCR (guía práctica)
Veamos cómo los desarrolladores utilizan comúnmente los métodos OCR PDFde DeepSeek para extraer texto y datos de diseño precisos de documentos escaneados o digitales.
Métodos que usan los desarrolladores hoy
En PDFs, hay dos maneras prácticas en que los equipos ejecutan DeepSeek actualmente, según las consideraciones de calidad, coste y latencia.
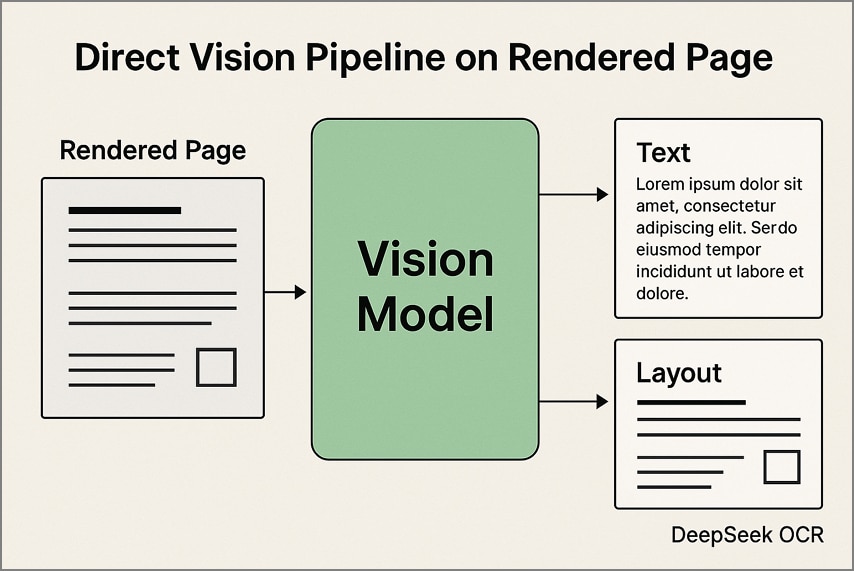
1. Pipeline de visión directa en páginas renderizadas
En este método, cada página PDF se convierte en imagen a resolución fija antes de ser procesada por DeepSeek OCR. El modelo extrae tanto texto como detalles del diseño directamente de la imagen, manteniendo tablas, columnas y diagramas en su estructura original. Este método es especialmente efectivo para documentos escaneados y diseños visualmente complejos.
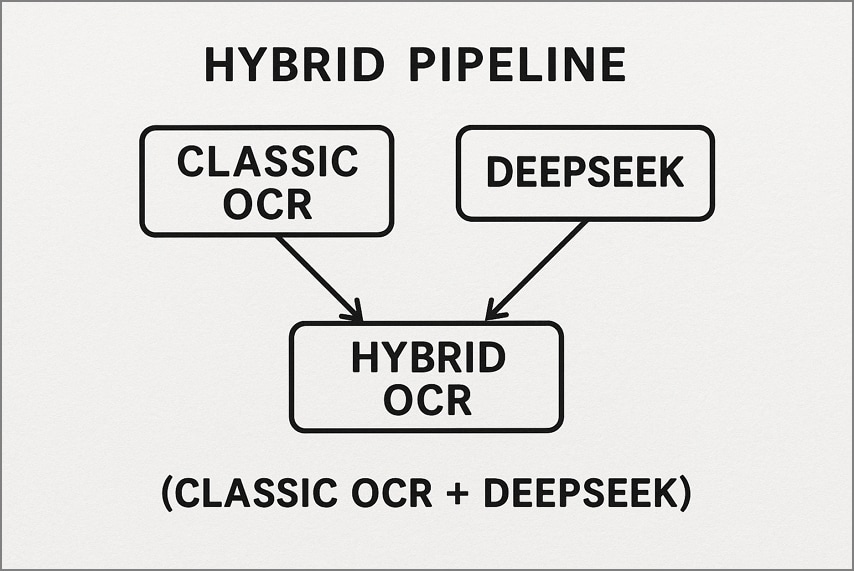
2. Pipeline híbrido (OCR clásico + DeepSeek)
Aquí, una herramienta OCR tradicional, por ejemplo Tesseract, gestiona primero las páginas simples y de alta calidad para generar texto rápidamente. Solo las páginas más complejas o ruidosas se envían a DeepSeek OCR para reconstruir el diseño y comprender la semántica. Este flujo reduce costes y latencia, manteniendo precisión premium en documentos difíciles.
Casos límite
Algunos documentos son más difíciles de procesar que páginas de texto estándar, por lo que es importante manejar los casos límite cuidadosamente para una mejor precisión OCR.
- Revistas/Periódicos multicolumna: Asegura el orden correcto de columnas con agrupación después de OCR, prefiere 300 DPI, segmenta por columna para páginas densas.
- Sellos/Marcas de agua/Sellos oficiales: Enmascara o separa capas antes de OCR para evitar texto falso y fusiones incorrectas, luego reinsertar después.
- Sesgo/Rotación: Corrige la inclinación de las páginas primero, detecta la orientación de forma fiable y vuelve a ejecutar OCR en páginas rotadas.
- Escaneos de baja DPI: Agranda 1,5-2 veces y aplica nitidez, o mejor aún, vuelve a escanear a mayor DPI.
- Tablas y formularios: Ejecuta un detector de tablas o alineador de encabezados para reparar celdas cortadas, luego valida totales y campos claves.
- Fuentes/Matemáticas/Código: Usa tiles de mayor resolución para ecuaciones, bloques de código y fuentes muy pequeñas, y preserva espacios monoespaciados con delimitadores de código.
Por qué importa el procesamiento posterior
El procesamiento posterior es la limpieza simple tras la extracción de texto, para que el resultado se lea correctamente. Corrige columnas mezcladas, tablas rotas, encabezados desordenados y sellos accidentalmente leídos como palabras. Si algo luce raro, vuelve a procesar esa página con mayor calidad y revisa totales, fechas e IDs.
Ollama + DeepSeek OCR: flujo local-first y procesamiento privado
Es un marco ligero que ejecuta grandes modelos de lenguaje completamente en tu ordenador, con una simple API local y CLI. Ollama DeepSeek OCR te permite procesar documentos escaneados y PDFs de extremo a extremo en tu máquina para evitar depender de la nube y preservar la estructura en salidas como Markdown o JSON.
Integración comunitaria y ejemplos
En esta sección, exploraremos proyectos comunitarios que combinan DeepSeek OCR con modelos Ollama para procesamiento local de documentos, extracción y análisis.
- Streamlit OCR Studio: Un panel de Streamlit recibe PDFs e imágenes y ejecuta DeepSeek OCR para texto estructurado. Este modelo responde preguntas del usuario sobre el contenido extraído localmente.
- Extractores Markdown + Ollama QA: El utilitario de imagen a Markdown convierte imágenes de página en Markdown limpio para uso posterior. Un modelo de chat Ollama resume documentos y extrae campos clave de PDFs e imágenes escaneadas.
- Analizador local + API de Ollama: Un servicio de carpeta monitorizada aplica OCR con DeepSeek a los nuevos archivos al llegar. Expone un endpoint Ollama local para búsqueda, preguntas y respuestas, redacción y automatización de flujos de trabajo.
Por qué ayuda la orquestación local
Después de ejecutar Ollama con DeepSeek OCR localmente, exploremos ventajas clave de esta configuración.
- Mantén los documentos en el dispositivo para cumplir con políticas estrictas de datos y reducir riesgos de filtración durante auditorías.
- Ejecuta sin internet en laboratorios seguros y redes aisladas para pruebas de cumplimiento.
- Evita retrasos de red, controla agrupamientos y caché localmente, y estabiliza el rendimiento en PDFs grandes.
Alternativa rápida sin código: PDFelement (OCR PDF limpio y preciso)
Muchos usuarios sin experiencia técnica suelen tener dificultades para extraer texto de PDFs escaneados o documentos basados en imágenes. Además de DeepSeek OCR, buscan herramientas que ofrezcan procesamiento OCR fácil, limpieza de documentos y extracción rápida de texto sin conocimientos técnicos. Aquí es donde PDFelement entra en acción, simplificando la extracción de PDF con OCR sin código y ayudando a los equipos a convertir documentos en formatos buscables en segundos.



A diferencia de otras herramientas, los usuarios también pueden subrayar, agregar una marca de agua, insertar un fondo y chatear con la IA sobre sus PDF. PDFelement te ofrece hasta 20GB de almacenamiento para guardar tus datos dentro de esta herramienta y compartirlos directamente a través de plataformas de redes sociales. Además, para hacer editable una zona específica, ofrece la opción "Área OCR" para seleccionar partes específicas de un documento.
Guía definitiva para OCR en PDF sin código en PDFelement
Después de conocer la mejor herramienta OCR para PDF sin necesidad de programar, sigue este flujo de trabajo paso a paso para procesar PDFs rápidamente como alternativa al API DeepSeek OCR:
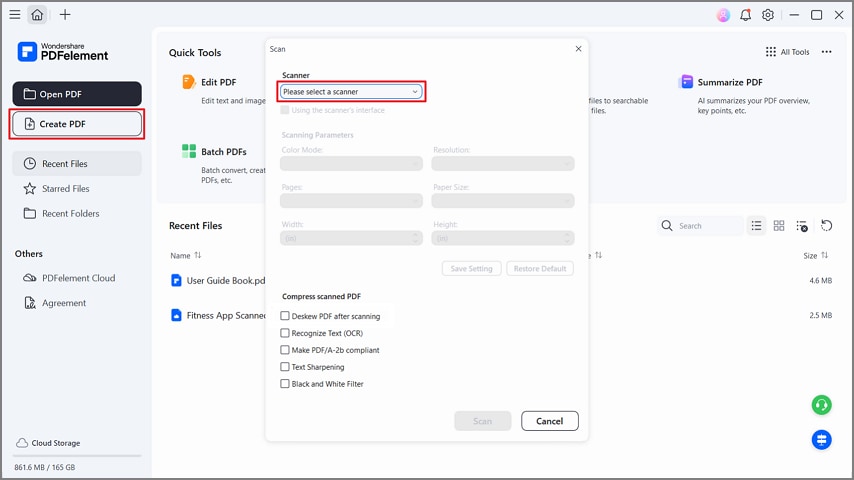
Paso 1Crear PDF desde el escáner
Una vez que ingreses a la herramienta, presiona el botón "Crear PDF" y selecciona la opción "Desde escáner" en el menú desplegable. Luego, elige tu escáner y marca la opción "Corregir inclinación PDF después de escanear". Esta herramienta convierte los escaneos en texto editable o con posibilidad de búsqueda con soporte para escritorio.
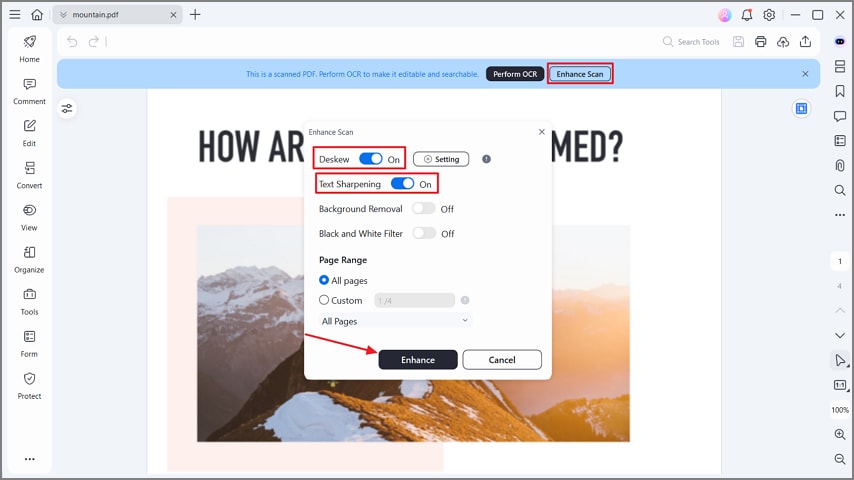
Paso 2Mejorar tu PDF
Luego de crear el PDF escaneado, presiona el botón "Mejorar escaneo". Después, activa las opciones de "Corregir inclinación" y "Nitidez de texto", y pulsa el botón "Mejorar" en la ventana emergente. Esto agudizará el texto del PDF para mejorar la precisión del OCR, incluso en escaneos de baja calidad.
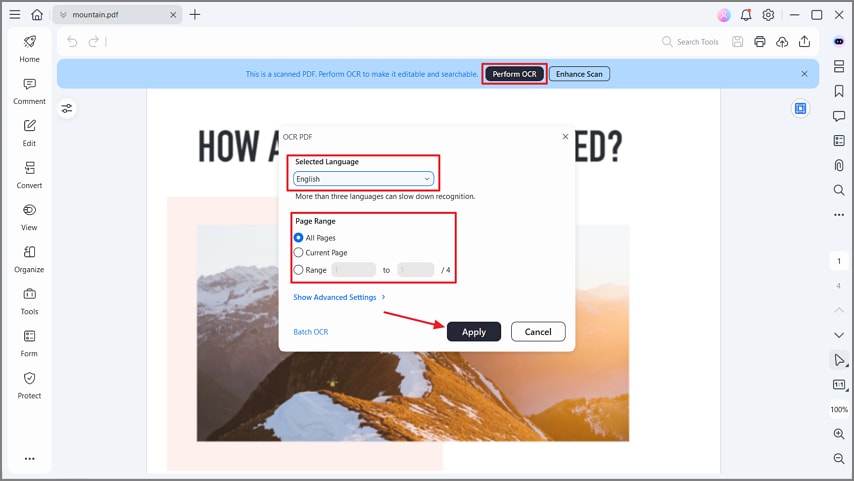
Paso 3Realizar OCR en el texto
Ahora, pulsa el botón "Realizar OCR" y escoge el idioma correcto. Después, selecciona un "Rango de páginas" específico y presiona "Aplicar" para comenzar el proceso OCR. Esto extraerá el texto de tu PDF para que sea editable y con búsqueda para revisión o exportación.
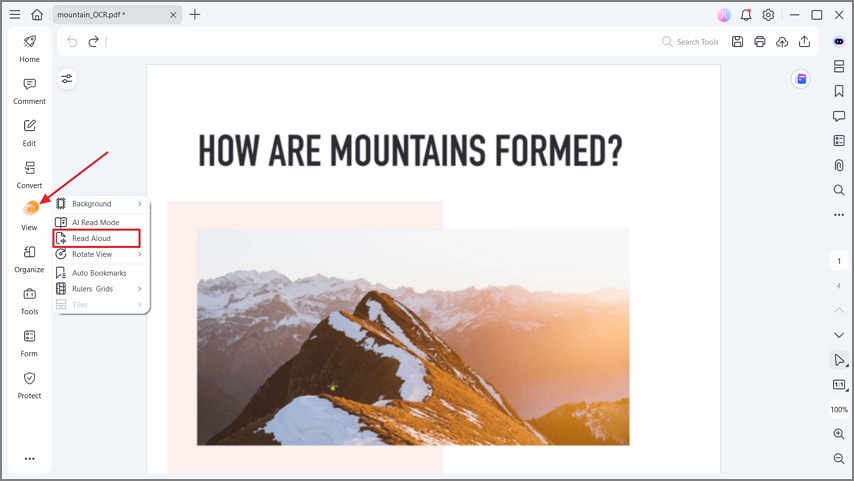
Paso 4Lectura en voz alta del PDF
Una vez finalizado el OCR, selecciona la opción "Vista" en el menú lateral izquierdo y presiona "Leer en voz alta" para escuchar el texto de tu PDF. Puedes pausar o detener la lectura en cualquier momento. Esta función te permite corregir tus PDF para identificar posibles errores.
Paso 5Anotar y exportar PDF
Haz clic en el botón "Comentario" y utiliza las herramientas de la barra para resaltar texto y agregar comentarios al PDF. Por último, presiona "Guardar" para exportar el archivo PDF. La función de Anotación también ayuda a agregar sellos, dibujar formas, adjuntar adhesivos, y subrayar o tachar texto para una mejor revisión de documentos.
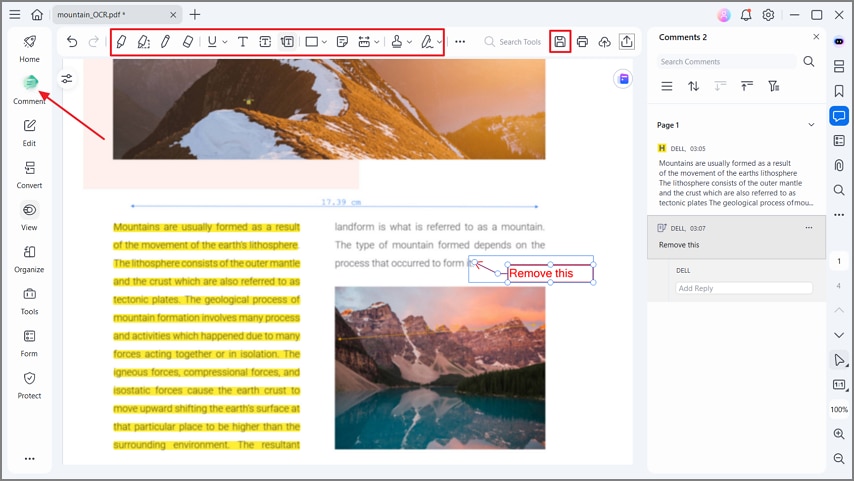

Comparativa: DeepSeek OCR vs PDFelement vs OCR clásico
Después de explorar la mejor alternativa a DeepSeek OCR, veamos qué herramientas son ideales según el caso de uso y los flujos documentales.
DeepSeek OCR
Ideal para desarrolladores que requieren razonamiento de largo contexto, RAG eficiente en tokens y salidas con formato y estructura en Markdown o JSON. Se requiere trabajo de configuración y operación, incluido el dimensionamiento de GPU/VRAM, decisiones sobre lotes o mosaicos y ajustes para casos especiales.
Wondershare PDFelement
Una opción sólida para el trabajo documental diario que necesita OCR multilingüe, mejorar escaneos, anotaciones y revisión. La exportación a Word o Excel con un clic agiliza el traspaso y los equipos evitan la programación o gestión de GPU.
Bibliotecas de OCR clásico
Funciona mejor con alto volumen cuando los diseños son simples y uniformes por lote. Añade reglas livianas o una pasada LLM específica solo en páginas difíciles para agregar semántica sin el coste en todo el lote. Consulta la tabla comparativa a continuación para entender cómo cada herramienta se adapta a diferentes flujos y necesidades.
| Herramienta | Enfoque | Configuración | Largo contexto | Postprocesamiento | Multilingüe | Mejor para |
| DeepSeek OCR | Flujos de desarrollo, RAG | Técnico | Moderada | Limitada/Scripts | Moderada | Desarrolladores, prototipos, investigación, pipelines RAG |
| PDFelement | Edición y revisión de documentos | Sin código | Alta | Herramientas visuales completas | Alta | Equipos de negocios, operaciones, cumplimiento, archivo |
| OCR clásico | Procesamiento por lotes, documentos simples | Técnico | Media | Basado en script | Moderada | Procesos por lotes, back-office, diseños simples |
Guías listas para copiar (ejemplos prácticos)
Ahora que entiendes cómo cada herramienta se adapta a diferentes flujos, pasemos a las guías rápidas de configuración. Los siguientes manuales rápidos muestran cómo utilizar DeepSeek OCR en GitHub y otras opciones para desarrolladores y no desarrolladores.
Desarrolladores — Prueba la API DeepSeek OCR en 10 minutos
- Paso 1. Genera una clave API desde "Cuenta" o "Claves API" y define "DEEPSEEK_API_KEY".
- Paso 2. Prepara una petición POST a "/v1/chat/completions" con el modelo, prompt de sistema y esquema de contenido.
- Paso 3. Renderiza las páginas PDF a PNG en DPI fijo y adjunta el base64 en "mensajes".
- Paso 4. Solicita JSON o Markdown estricto y luego analiza el campo "content" de forma segura.
- Paso 5. Valida los campos, maneja reintentos y guarda en "Trabajos" o "Almacenamiento".
Desarrolladores — Ejecuta desde GitHub (Local)
- Paso 1. "Clona" el repositorio en una máquina compatible con CUDA y verifica el controlador o toolkit.
- Paso 2. Crea un entorno virtual, ejecuta "pip install -r requirements.txt", descarga los "pesos", define "MODEL_PATH".
- Paso 3. Convierte PDF a imágenes a DPI consistente, ejecuta "infer.py --input pages --output out --format markdown".
- Paso 4. Registra "latencia", "VRAM" y "rendimiento", y compara la precisión contra el OCR base.
No desarrolladores — OCR limpio para PDFs en PDFelement
- Paso 1. Primero, haz clic en "Crear PDF" y "Desde escáner" para escanear. Luego, presiona "Mejorar escaneo" y activa las opciones "Corregir inclinación" y "Nitidez de texto".
- Paso 2. Presiona "Realizar OCR", selecciona el "Idioma", escoge "Texto editable" o "Texto con búsqueda en imagen" y haz clic en "Aplicar".
- Paso 3. Usa "Lectura con IA" o "Leer en voz alta" para corregir escuchando y arregla errores que detectes durante la reproducción.
- Paso 4. Ahora, presiona "Comentario" en el panel izquierdo para añadir "Resaltados", "Comentarios" y "Adhesivos" para revisión.
- Paso 5. Por último, presiona "Exportar" para guardar un PDF con búsqueda listo para entregar.
Consideraciones y limitaciones conocidas (precisión, seguridad, disponibilidad)
Antes de implementarlo por completo en producción, es importante revisar varios factores prácticos que afectan el desempeño de la API DeepSeek OCR en usos reales.
- Precisión: Los resultados varían según el diseño de la página y la calidad del escaneo, así que prueba el desempeño en tu propio corpus primero. Usa documentos representativos, incluye tablas y columnas, y registra errores como divisiones o fusiones indebidas.
- Seguridad y cumplimiento: Revisa cómo el proveedor maneja datos, almacenamiento y retención, y evita transmitir archivos sensibles sin evaluación previa. Añade redacción antes de subir, restringe el acceso y documenta aprobaciones para auditorías y políticas internas.
- Disponibilidad y fiabilidad: Los servicios pueden experimentar caídas o limitaciones, así que agrega reintentos, retrocesos y contingencias locales. Monitorea tasas de error y latencia, alerta ante fallos y define manuales de operación claros para incidentes.
- Capacidad y escalabilidad: Toma la capacidad publicitada solo como indicativa y haz pruebas en tu hardware con DPI fijo. Mide páginas por hora, uso de GPU o CPU y costos, luego ajusta el tamaño de los lotes y la caché.
Preguntas frecuentes
-
¿Qué es DeepSeek OCR y por qué es importante la "compresión óptica"?
DeepSeek OCR comprime el contenido de la página en tokens visuales compactos que preservan la estructura y reducen el uso de tokens para modelos posteriores. Esto es importante porque permite abarcar más documentos dentro de los límites de contexto y reduce el coste del procesamiento, manteniendo tablas, listas y diseño intactos. -
¿Dónde se encuentra el repositorio de DeepSeek OCR en GitHub?
El repositorio oficial proporciona código, ejemplos y referencias para ejecutar inferencia local y adaptar flujos de trabajo. Clónalo para comparar resultados con tu OCR base, personaliza prompts y exporta a Markdown o JSON para integración. -
¿Existe una API de DeepSeek OCR y es compatible con OpenAI?
Existe una API que acepta solicitudes tipo chat de OpenAI con imágenes o páginas PDF renderizadas. Puedes solicitar JSON o Markdown estricto y luego analizar la respuesta usando bibliotecas y flujos estándar. -
¿Cómo se usa con PDFs?
Convierte cada página PDF a imagen a DPI constante, ejecuta el OCR visual y luego concatena páginas y procesa tablas o listas. Alternativamente, ejecuta un OCR clásico para extraer texto, luego aplica DeepSeek para semántica de diseño, reparación de estructura y generación de markdown. -
¿Puedo usarlo localmente con Ollama?
Las configuraciones comunitarias combinan salidas de DeepSeek con modelos locales de Ollama para preguntas, extracción y validación. Los patrones típicos incluyen paneles con Streamlit, procesadores de carpetas vigiladas y analizadores ligeros de documentos sin depender de servicios en la nube externos. -
Solo necesito pasar OCR a un PDF escaneado con soporte multilingüe—¿qué es lo más fácil?
Usa PDFelement para un flujo sin código que se encarga de corrección de inclinación, reducción de ruido y OCR multilingüe de forma confiable. Mejora el escaneo, elige el idioma adecuado, corrige con Leer en voz alta o Lectura IA, anota y exporta un PDF limpio y con búsqueda.