
Extraer datos de PDF es una necesidad común en muchas industrias, incluyendo finanzas, salud e investigación. A medida que las organizaciones dependen cada vez más de los PDF para compartir información, ha crecido la necesidad de extraer datos de los PDF utilizando Python. Sin embargo, la extracción manual de datos puede ser lenta y propensa a errores, lo que conduce a ineficiencias e imprecisiones en el manejo de los datos.
En este artículo
- ¿Por qué extraer datos de PDF utilizando Python?
- Bibliotecas clave para la extracción de datos de PDF en Python
- PDFelement: Simplifica todo el proceso de extracción de datos de PDF
- Beneficios de PDFelement en comparación con la programación manual en Python
- ¿Cómo PDFelement funciona de manera fluida con Python?
- Guía paso a paso para extraer datos de un PDF usando Python y PDFelement
- Beneficios de combinar PDFelement con Python
Python ha ganado una gran popularidad como una herramienta potente para la extracción de datos de un PDF. Con sus amplias bibliotecas y su sintaxis fácil de usar, Python simplifica el proceso de extracción de datos de un archivo PDF. Este artículo demostrará cómo Python, combinado con herramientas como PDFelement, facilita y optimiza la extracción de datos de un PDF.
¿Por qué extraer datos de PDF utilizando Python?
Las capacidades de Python para trabajar con PDF son amplias, gracias a su rico ecosistema de bibliotecas diseñadas específicamente para la extracción de datos de un PDF. Estas bibliotecas ofrecen diversas funciones que se adaptan a distintas necesidades de extracción. Algunas bibliotecas destacadas incluyen:
PyPDF2
Esta biblioteca permite la extracción básica de texto y la manipulación de archivos PDF, lo que la convierte en un excelente punto de partida para los usuarios que desean extraer datos de un PDF usando Python sin formatos complejos.
PyMuPDF (Fitz)
Este programa extrae eficazmente el texto y las anotaciones. Ofrece funciones más avanzadas que PyPDF2 y destaca en la extracción de información estructurada, lo que lo convierte en una opción ideal para documentos que contienen imágenes o anotaciones junto con el texto.
PDFMiner
Esta biblioteca ofrece funciones avanzadas para extraer texto mientras preserva la estructura del diseño, lo que la hace perfecta para documentos complejos. Los usuarios pueden obtener información detallada sobre la posición y el formato del texto, lo cual es crucial al trabajar con diseños complejos.
Bibliotecas clave para la extracción de datos de PDF en Python
PyPDF2
PyPDF2 es una biblioteca ampliamente utilizada que ofrece funcionalidades esenciales para leer y manipular archivos PDF. Es especialmente útil para usuarios que desean extraer datos de un PDF utilizando Python.
Lo que puede hacer:
- Extraer texto: Esta función recupera texto de páginas individuales de un documento PDF, lo que permite un acceso fácil al contenido.
- Unir o dividir PDF: Combina varios documentos PDF en un solo archivo o divide un PDF grande en secciones más pequeñas y manejables.
Ejemplos de cuándo utilizarlo:
- Cuando necesites extraer texto de PDF sencillos sin diseños complejos, como informes o facturas.
- Unir varios PDF en un solo documento es útil para organizar archivos relacionados.
PyMuPDF (Fitz)
PyMuPDF, también conocido como Fitz, es una poderosa biblioteca para extraer texto y anotaciones de documentos PDF. Sus capacidades avanzadas lo convierten en una opción preferida para usuarios que necesitan realizar tareas más complejas de extracción de datos de PDF con Python.
Capacidad:
- Extracción eficiente de texto: Extrae texto manteniendo el diseño, asegurando que el resultado conserve el formato original.
- Acceso a imágenes y medios: Esta función permite a los usuarios extraer imágenes y otros medios incrustados en el PDF, lo que la hace ideal para documentos visualmente ricos.
Casos de uso ideales:
- Cuando necesites extraer información detallada junto con imágenes o anotaciones, como en artículos académicos o materiales de marketing.
- Para extraer contenido de PDF visualmente ricos donde la conservación del diseño sea crucial.
PDFMiner
PDFMiner es una biblioteca avanzada diseñada específicamente para extraer información detallada de PDF, incluyendo el diseño y la estructura del texto. Es especialmente beneficiosa para usuarios que requieren un control preciso sobre cómo se extraen los datos de sus documentos.
Funciones:
- Conservación del diseño: Capaz de extraer texto junto con su información de diseño, lo que la hace ideal para documentos complejos donde la estructura es importante.
- Análisis avanzado de texto: Ofrece herramientas para analizar el diseño de los documentos, lo cual puede ser crucial cuando el formato es importante.
Cuándo utilizarlo:
- Cuando necesites un control preciso sobre cómo se extrae el texto según su posición en el documento, como en contratos legales o manuales técnicos.
- Para analizar el diseño de documentos donde el formato es crucial, asegurando que los datos extraídos conserven su estructura original.
Pandas para datos tabulares
Integrar Pandas con otras bibliotecas puede ser muy beneficioso para extraer datos tabulares estructurados de PDF. Pandas te permite gestionar y analizar los datos extraídos de manera eficiente, lo que lo convierte en una herramienta esencial en tu kit de herramientas de Python para extraer datos de PDF utilizando Python.
Beneficios:
- Manipulación de datos: Manipula fácilmente grandes conjuntos de datos extraídos de PDF, facilitando su análisis y generación de informes.
- Análisis complejo: Realiza análisis complejos sobre datos estructurados con mínimo esfuerzo, aprovechando las potentes capacidades de manejo de datos de pandas.
Al utilizar estas bibliotecas, PyPDF2, PyMuPDF (Fitz), PDFMiner y pandas, los usuarios pueden extraer datos de PDF de manera eficaz con Python, adaptado a sus necesidades específicas. Ya sea que estés extrayendo texto simple o tablas complejas, el robusto ecosistema de Python proporciona las herramientas necesarias para una extracción eficiente de datos de PDF con Python.
PDFelement: Simplifica todo el proceso de extracción de datos de PDF
PDFelement es un editor de PDF completo con una variedad de funciones diseñadas para simplificar la gestión de documentos. Ofrece herramientas fáciles de usar para crear, editar, convertir y extraer datos de PDF de manera fluida.
Beneficios de PDFelement en comparación con la programación manual en Python
Usar PDFelement ofrece varias ventajas sobre los métodos tradicionales de scripting manual:
- Interfaz intuitiva: PDFelement es fácil de usar, incluso para aquellos sin experiencia en programación. Esta accesibilidad lo convierte en una excelente opción para individuos o equipos que no tengan habilidades de programación, pero que aún necesiten herramientas efectivas para extraer datos de PDF utilizando Python.
- Tecnología OCR: Incluye capacidades de reconocimiento óptico de caracteres (OCR, en inglés) que permiten a los usuarios extraer texto de PDF escaneados de manera eficaz. Esta función es especialmente valiosa para documentos físicos digitalizados.
- Opciones de exportación: Los usuarios pueden exportar los datos extraídos a formatos estructurados como Excel, CSV o Word. Las bibliotecas de Python pueden procesar estos formatos rápidamente, lo que permite una integración fluida en los flujos de trabajo existentes.
¿Cómo PDFelement funciona de manera fluida con Python?
Puedes extraer datos utilizando la interfaz intuitiva de PDFelement y luego procesarlos con scripts de Python para un análisis posterior. Esta combinación mejora tu flujo de trabajo al aprovechar las fortalezas de ambas herramientas: PDFelement simplifica el proceso de extracción, mientras que Python permite una manipulación y análisis avanzados de los datos extraídos.
Guía paso a paso para extraer datos de un PDF usando Python y PDFelement
Uso de Python
Para empezar a extraer datos con Python, primero necesitas instalar las librerías necesarias:
bash
pip install pypdf2 pymupdf pdfminer.six pandas
Ejemplo de código simple para extraer texto o datos de tabla
Aquí tienes un ejemplo básico que muestra cómo extraer texto con PyPDF2:
python
from PyPDF2 import PdfReader
# Cargar el archivo PDF
reader = PdfReader('example.pdf')
# Extraer texto de cada página
for page in reader.pages:
print(page.extract_text())
Limitaciones de la extracción solo con Python
Aunque el uso de librerías de Python para la extracción de datos de un PDF ofrece flexibilidad, existen limitaciones importantes:
- Dificultades con documentos escaneados: Las librerías estándar pueden no manejar eficazmente los documentos escaneados sin capacidades OCR. Este es un inconveniente importante al intentar extraer datos de un PDF usando Python, especialmente cuando los documentos son principalmente basados en imágenes.
- Pérdida de la estructura de los datos: A menos que se maneje específicamente, la extracción de tablas puede resultar en una pérdida de formato o estructura. Esto puede complicar el análisis posterior si el diseño original es importante. Muchos usuarios enfrentan desafíos al intentar extraer datos de un PDF con Python, especialmente con tablas complejas que requieren un formato preciso.
Usar PDFelement para extraer datos
Para extraer datos de un PDF de manera efectiva usando PDFelement:
Paso 1
Abre PDFelement y carga tu documento PDF.
Paso 2
Navega a la pestaña Formulario y selecciona Extraer datos.
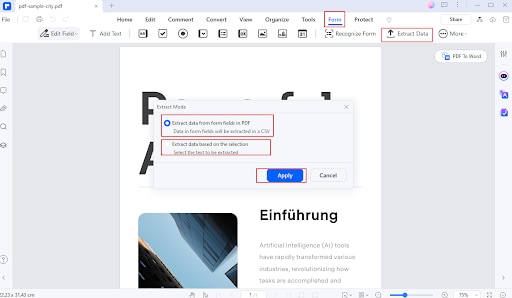
Paso 3
Elige las opciones de extracción que desees (por ejemplo, campos de formulario o tablas).
Beneficios de combinar PDFelement con Python
Integrar PDFelement con Python ofrece varias ventajas para los usuarios que buscan mejorar la extracción de datos de PDF en Python:
- Impulso de eficiencia: Combinar la interfaz intuitiva de PDFelement con la flexibilidad de Python mejora la productividad al permitir que los usuarios se centren en el análisis en lugar de en la logística de extracción. Esta combinación es especialmente beneficiosa para aquellos que necesitan extraer datos de un PDF utilizando Python de manera regular.
- Mejora de la precisión: PDFelement utiliza soporte OCR para una extracción precisa de PDF escaneados, algo con lo que las librerías estándar suelen tener dificultades. Esta función es crucial para garantizar que los datos importantes no se pierdan durante el proceso de extracción.
- Ahorro de tiempo: Automatiza tareas repetitivas aprovechando eficazmente ambas herramientas. Por ejemplo, utiliza PDFelement para manejar las extracciones iniciales y luego aplica scripts de Python para un análisis más profundo o generación de informes. Este enfoque permite a las empresas optimizar sus flujos de trabajo y mejorar la eficiencia general en la gestión de múltiples documentos PDF.
Esta combinación es particularmente ideal para empresas que manejan múltiples documentos PDF y conjuntos de datos complejos, donde la eficiencia y precisión en la extracción de datos de PDF con Python son fundamentales.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Conclusión
En conclusión, existen varias opciones para extraer datos de PDF utilizando Python, incluidas librerías como PyPDF2, PyMuPDF y PDFMiner. Sin embargo, PDFelement se destaca por su capacidad para agilizar el proceso de extracción con funciones fáciles de usar y potentes capacidades, lo que lo convierte en una excelente opción para mejorar la gestión de documentos PDF. Además, DocuSign ofrece un método sencillo para rechazar la firma de documentos, lo que también puede integrarse en tu flujo de trabajo, mejorando aún más la eficiencia en el manejo de datos de PDF.