Gestionar decenas de facturas, formularios o recibos escaneados cada semana supone horas de introducción manual de datos y un riesgo constante de error. Extraer datos de una imagen automatiza ese proceso: convierte fotos y documentos escaneados en información estructurada y editable en segundos, sin necesidad de teclear cada valor a mano.
Con la herramienta OCR adecuada, es posible capturar números, textos y tablas completas y exportarlos directamente a Excel, Google Sheets o cualquier base de datos. Esta guía explica qué es la extracción de datos de imágenes, qué métodos existen, cómo funciona la tecnología OCR y cómo obtener resultados precisos desde el primer intento.
En este artículo
- ¿Para qué se usa la extracción de datos de imágenes?
- ¿Qué significa extraer datos de una imagen?
- Tipos de datos que se pueden extraer de imágenes
- Por qué las imágenes son más difíciles de procesar que los PDF
- Cómo funciona la extracción de datos de imágenes
- Métodos para extraer datos de una imagen
- Cómo extraer datos de imágenes con PDFelement [Recomendado]
- Integrar los datos extraídos en flujos de trabajo de Excel
- Cómo mejorar la precisión al extraer datos de imágenes
- Errores frecuentes que reducen la calidad de la extracción
- Conclusión
¿Para qué se usa la extracción de datos de imágenes?
En muchos entornos de trabajo, las imágenes son la única fuente disponible de cierta información: recibos en papel, notas en pizarras, formularios físicos o capturas de pantalla de sistemas que no permiten exportar datos. Digitalizar ese contenido manualmente no es viable cuando el volumen es alto. La extracción automatizada de datos de imágenes resuelve este problema en los siguientes escenarios:
- Gestión documental: Extraer datos de documentos escaneados permite digitalizar contratos, informes y formularios de forma rápida y precisa, eliminando la transcripción manual y garantizando un almacenamiento fiable en bases de datos o hojas de cálculo.
- Captura de tablas financieras: Analistas y contables que trabajan con capturas de pantalla de informes financieros o cronogramas pueden convertir esas imágenes en hojas editables sin reescribir ningún dato.
- Digitalización de archivos históricos: Archivistas y gestores documentales procesan grandes volúmenes de registros en papel escaneados. Extraer los datos les permite organizar y recuperar información histórica de forma eficiente.
- Digitalización de tarjetas de visita: Los equipos de ventas y profesionales del networking pueden convertir pilas de tarjetas físicas en registros de contacto directamente importables a un CRM, sin errores de transcripción.
- Seguimiento de recibos y facturas: Autónomos, contables y pymes que digitalizan facturas y recibos para su contabilidad pueden automatizar la captura de importes, fechas y datos del proveedor, simplificando el control de gastos.
¿Qué significa extraer datos de una imagen?
Extraer datos de una imagen a Excel o a cualquier otro formato consiste en usar software para identificar el contenido visual de una imagen —texto, números, tablas— y convertirlo en datos digitales editables y procesables. No se trata solo de "leer" la imagen, sino de transformar píxeles en información estructurada que puede almacenarse, analizarse e integrarse en otros sistemas.
Diferencia entre leer texto visualmente y extraer datos utilizables
Cuando una persona mira una imagen y comprende su contenido, está interpretando la información visualmente. Ese proceso no produce ningún dato editable ni integrable en herramientas digitales. La extracción de datos, en cambio, convierte esa misma información en formatos legibles por máquina —texto plano, tablas, campos estructurados— que pueden editarse, analizarse e integrarse directamente en hojas de cálculo o bases de datos.
Extracción de texto frente a extracción de datos estructurados
No toda extracción de datos es igual. Existe una diferencia clave entre capturar texto sin procesar y obtener datos correctamente organizados. La siguiente tabla lo ilustra con claridad:
| Característica | Extracción de texto | Extracción de datos estructurados |
| Definición | Captura el texto sin procesar de una imagen | Organiza el contenido en tablas, campos o registros listos para usar |
| Formato de salida | Texto plano, sin estructura | Tablas editables, campos o entradas listas para base de datos |
| Casos de uso | Notas escaneadas, párrafos, imágenes con texto libre | Facturas, recibos, formularios, tarjetas de visita, tablas |
| Complejidad técnica | Básica: requiere OCR estándar | Avanzada: requiere IA o reconocimiento de patrones para preservar la estructura |
Por qué el diseño y el contexto condicionan la calidad de la extracción
La disposición visual de un documento afecta directamente a la precisión de los datos extraídos. Reconocer correctamente la estructura garantiza que números, textos y relaciones entre campos se interpreten de forma adecuada. Estos son los escenarios donde el diseño resulta más determinante:
- Facturas: Un diseño consistente permite asignar correctamente importes, fechas y nombres de proveedor a sus campos correspondientes.
- Formularios estandarizados: Preservar la integridad del diseño evita confusiones entre campos como dirección, teléfono o NIF.
- Tablas: Mantener la estructura de filas y columnas es esencial para que las relaciones entre datos permanezcan intactas en el archivo de salida.
- Notas manuscritas: El contexto ayuda a distinguir encabezados, subpuntos y anotaciones, mejorando la claridad del documento digitalizado.
- Tickets y recibos: Identificar el diseño evita confundir totales, impuestos y precios unitarios.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Tipos de datos que se pueden extraer de imágenes
El tipo de contenido presente en una imagen determina qué enfoque de extracción resulta más adecuado. Conocer las categorías principales ayuda a elegir la herramienta correcta, especialmente cuando el objetivo es extraer una tabla de imagen a Excel.
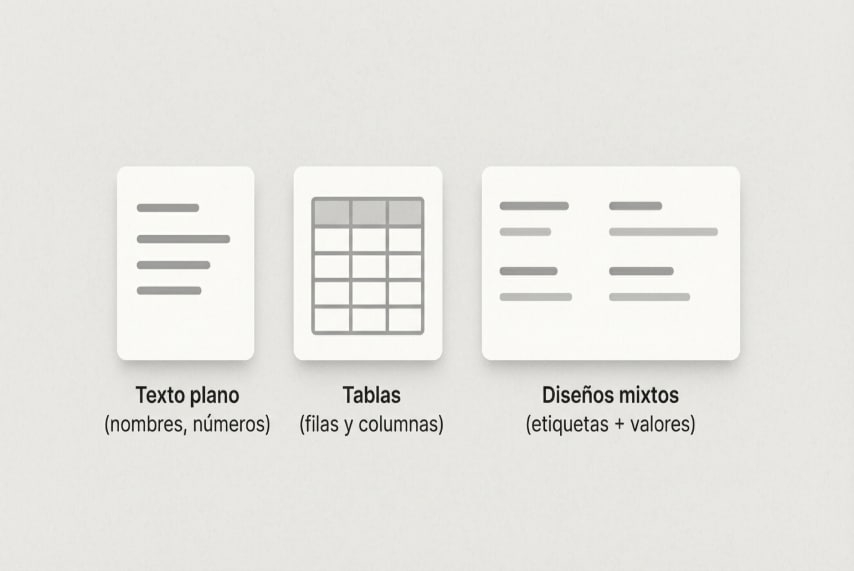
Texto plano (nombres, números, direcciones)
La extracción de texto plano captura palabras, frases o valores numéricos individuales: nombres, direcciones, teléfonos, números de serie o cualquier dato independiente. Las herramientas OCR reconocen y convierten estos elementos en formatos editables con rapidez, eliminando la necesidad de teclear cada dato manualmente.
Tablas (filas y columnas)
Las tablas contienen datos organizados en filas y columnas, como estados financieros, inventarios o cronogramas. Extraer una tabla correctamente preserva las relaciones entre sus celdas, lo que permite exportar los datos directamente a Excel, Google Sheets o sistemas de bases de datos sin necesidad de reformatear.
Diseños mixtos (etiquetas y valores)
Los formularios, facturas y recibos combinan etiquetas ("Importe total:", "Fecha:") con sus valores correspondientes. Extraer este tipo de contenido requiere que el software comprenda la relación entre etiqueta y valor, para asignar cada dato al campo correcto dentro de la estructura final.
¿Por qué las tablas son el tipo de dato más difícil de extraer con precisión?
- Formato complejo: Las celdas combinadas, los encabezados anidados o el espaciado irregular dificultan que el software identifique correctamente filas y columnas.
- Tipos de datos mixtos: Cuando una tabla combina números, texto y símbolos en las mismas celdas, mantener el contexto de cada valor se convierte en un reto técnico real.
- Imágenes distorsionadas o de baja calidad: Las tablas fotografiadas con inclinación o desenfoque pierden alineación, lo que impide una captura precisa de los datos.
- Diseños dinámicos: Las tablas con anchos de columna variables o totales calculados generan inconsistencias que requieren IA avanzada o corrección manual para resolverse.
Por qué las imágenes son más difíciles de procesar que los PDF
Al contrario que los PDF con texto incrustado, las imágenes almacenan todo su contenido como píxeles. No existe ninguna capa de texto subyacente que el software pueda leer directamente: el OCR debe inferir cada carácter a partir de su representación visual. Esto introduce una serie de problemas técnicos que no afectan a los PDF digitales:
- Sin estructura incrustada: Las imágenes no contienen metadatos ni texto etiquetado. El OCR trabaja exclusivamente con información visual, lo que lo hace más susceptible a errores.
- Imágenes borrosas o de baja resolución: Las fotos tomadas con mala iluminación o con movimiento generan caracteres difusos que el OCR puede interpretar incorrectamente u omitir.
- Sombras y problemas de iluminación: La iluminación desigual o las sombras proyectadas sobre el documento ocultan partes del texto, dificultando su detección.
- Distorsión por perspectiva: Fotografiar un documento en ángulo deforma filas y columnas, provocando extracción desalineada o incompleta.
- Ruido de fondo: Los fondos con texturas, manchas o marcas de agua añaden interferencias visuales que confunden al motor OCR y generan caracteres erróneos.
Todos estos factores —desenfoque, sombras, distorsión y ruido— se combinan para aumentar la tasa de error del OCR. La falta de estructura incrustada obliga al software a depender únicamente de pistas visuales, por lo que las variaciones en la calidad de la imagen tienen un impacto directo y proporcional en la precisión del resultado.
Cómo funciona la extracción de datos de imágenes
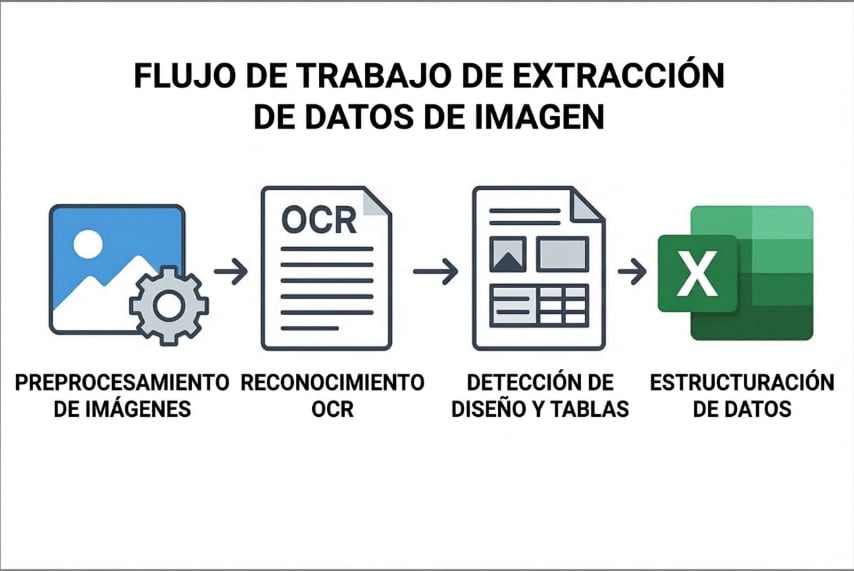
Cualquier herramienta que convierte imagen a texto o extrae datos estructurados sigue, en esencia, las mismas cuatro fases:
- Preprocesamiento: La imagen se limpia y optimiza antes del análisis. Esto incluye reducción de ruido, ajuste de contraste, binarización (conversión a blanco y negro) y corrección de inclinación para maximizar la legibilidad.
- Reconocimiento OCR: El motor de reconocimiento óptico de caracteres analiza la imagen procesada, detecta los caracteres visibles y los convierte en texto legible por máquina. En herramientas modernas, esta fase incorpora modelos de IA que mejoran la precisión en documentos complejos o manuscritos.
- Detección de diseño y estructura: El sistema analiza las relaciones espaciales entre los elementos reconocidos para identificar encabezados, párrafos, filas, columnas y pares etiqueta-valor. Esta fase determina cómo se organizarán los datos en el formato de salida.
- Estructuración y exportación: El contenido reconocido se organiza en el formato de destino —tabla, hoja de cálculo, campo de base de datos— y se exporta a Excel u otras plataformas para su análisis y uso.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Métodos para extraer datos de una imagen
Existen varios enfoques para convertir imágenes en datos editables, cada uno con ventajas e inconvenientes distintos según el volumen de trabajo y la complejidad del documento.
Transcripción manual
Consiste en copiar a mano la información visible en la imagen. No requiere ningún software, pero es lento, propenso a errores humanos e inviable para grandes volúmenes. Solo tiene sentido para tareas muy puntuales con pocos documentos.
Copiar texto desde visores de imágenes o PDF
Algunos visores permiten seleccionar y copiar texto directamente si la imagen tiene OCR integrado. Este método funciona para contenido sencillo, pero falla con diseños complejos, texto manuscrito o imágenes de baja calidad. Además, no preserva la estructura de tablas ni los formatos numéricos.
Herramientas OCR dedicadas
Las herramientas de reconocimiento óptico de caracteres (OCR) detectan y convierten automáticamente el texto de imágenes en formatos digitales editables. Las soluciones avanzadas manejan documentos impresos, recibos, formularios y tablas, admiten procesamiento por lotes y se integran con hojas de cálculo y bases de datos. Son la opción más equilibrada en términos de precisión, velocidad y coste.
Aplicaciones móviles y herramientas gratuitas en línea
Para necesidades ocasionales o cuando no se requiere exportar datos estructurados, existen alternativas accesibles sin instalación:
- Google Lens: Extrae texto de fotos tomadas con el móvil y permite copiarlo directamente. Funciona bien para texto plano, aunque tiene limitaciones con tablas.
- Microsoft Office Lens: Captura y digitaliza documentos, pizarras y tarjetas de visita, con integración directa con Word y OneNote.
- Herramientas OCR online: Plataformas como Smallpdf, iLovePDF u OnlineOCR permiten subir una imagen y obtener el texto en segundos, sin necesidad de instalar nada.
Estas opciones son útiles para tareas simples, pero no resultan prácticas para flujos de trabajo empresariales que requieren precisión estructural, procesamiento por lotes o exportación directa a Excel.
¿Por qué los métodos básicos no escalan?
La transcripción manual y las herramientas gratuitas se vuelven impracticables con volúmenes altos de imágenes. Incluso el OCR básico tiene dificultades con diseños variados, mala calidad de imagen o datos mezclados. A mayor escala, estas limitaciones se traducen en más errores, inconsistencias y tiempo invertido en correcciones, lo que neutraliza el ahorro que se esperaba obtener.
Cómo extraer datos de imágenes con PDFelement
PDFelement está diseñado para ofrecer alta precisión en la conversión de imagen a datos estructurados. A diferencia de las herramientas OCR básicas, su motor avanzado reconoce texto, tablas y diseños mixtos, preservando el formato y la alineación originales. Funciona de forma fiable incluso con imágenes del mundo real: leves borrones, iluminación desigual o ángulos ligeramente inclinados.

El software detecta de forma inteligente filas, columnas y pares etiqueta-valor, garantizando una salida estructurada en lugar de texto fragmentado. Con exportación directa a Excel y formatos editables, PDFelement convierte imágenes en datos precisos y reutilizables listos para el análisis.



Cómo extraer datos de una imagen a Excel con PDFelement: paso a paso
Paso 1Importa la imagen
Abre PDFelement y selecciona "Crear PDF" en la esquina superior izquierda. En el menú desplegable, elige "Desde archivo" e importa la imagen que contiene los datos que deseas extraer.
Paso 2Aplica el OCR
Una vez importada la imagen, PDFelement detecta automáticamente si necesita procesamiento OCR. Pulsa el botón "Realizar OCR", selecciona el modo y el idioma del documento y haz clic en "Aplicar" para ejecutar el reconocimiento.
Paso 3Reconoce la tabla
Ve a la barra de herramientas lateral y haz clic en "Herramientas". Selecciona "Reconocer tabla" para que el software detecte automáticamente las filas, columnas y la estructura del documento.
Paso 4Revisa y edita los datos
Activa el modo "Editar" y revisa los datos extraídos. Corrige cualquier error de reconocimiento o ajusta los valores antes de exportar.
Paso 5Exporta a Excel
Cuando los datos estén listos, haz clic en el icono de menú (tres líneas) en la esquina superior izquierda, selecciona "Exportar a" y elige "Excel" para guardar el archivo como hoja de cálculo editable.

Integrar los datos extraídos en flujos de trabajo de Excel
Excel es el destino más habitual cuando los datos extraídos de una imagen necesitan cálculo, ordenación, filtrado o generación de informes. Las tablas estructuradas procedentes de facturas, registros financieros o resultados de encuestas se benefician directamente de las fórmulas y funciones de análisis de Excel. Exportar con la estructura preservada —filas y columnas alineadas— permite trabajar con los datos de inmediato, sin reformateo previo.
Cómo preparar los datos extraídos para el análisis
- Verifica el contenido: Compara los datos extraídos con la imagen original para detectar errores de OCR, campos ausentes o valores desplazados antes de comenzar el análisis.
- Estandariza el formato: Asegúrate de que las fechas, los símbolos de moneda y los formatos numéricos sean consistentes en toda la hoja. Un formato uniforme previene errores de fórmula y problemas al ordenar o filtrar.
- Elimina caracteres innecesarios: Borra espacios adicionales, saltos de línea, símbolos especiales o entradas duplicadas que puedan haberse introducido durante la extracción.
- Valida la estructura de la tabla: Confirma que las filas y columnas estén correctamente alineadas y que los encabezados correspondan a sus datos. Una estructura correcta es fundamental para que los cálculos sean fiables.
- Revisa los tipos de datos: Convierte los números almacenados como texto a formato numérico y verifica que fechas y porcentajes sean reconocidos correctamente por Excel.
Por qué revisar antes de usar la hoja de cálculo es imprescindible
Incluso con herramientas avanzadas, el OCR puede introducir pequeños errores que distorsionen totales, promedios o conclusiones analíticas. Dedicar unos minutos a validar los datos extraídos antes de usarlos protege la integridad de los análisis posteriores y evita decisiones basadas en información incorrecta.
Cómo mejorar la precisión al extraer datos de imágenes
La precisión en la extracción de datos no depende únicamente del software: la calidad de la imagen de entrada tiene un impacto directo y a menudo infraestimado en los resultados. Pequeños ajustes en la captura y el preprocesamiento pueden reducir significativamente la tasa de error.
Buenas prácticas al capturar la imagen
- Resolución alta: Captura los documentos con la mayor resolución posible. Las imágenes nítidas reducen los errores de OCR, especialmente en fuentes pequeñas o detalles finos.
- Iluminación uniforme: Evita sombras y destellos utilizando luz natural difusa o un escáner de cama plana. Una iluminación homogénea garantiza que todo el texto sea visible.
- Encuadre recto: Fotografía el documento desde directamente encima, con el plano paralelo a la cámara. Una alineación correcta facilita la detección de filas, columnas y etiquetas.
- Fondo limpio: Coloca el documento sobre una superficie lisa y sin patrones. Eliminar el ruido de fondo mejora la concentración del OCR en el contenido relevante.
- Estabilidad: Usa un trípode o apoya la cámara en una superficie fija para evitar el movimiento. Las imágenes borrosas por vibración son una de las causas más comunes de errores de OCR.
Técnicas de preprocesamiento que mejoran la extracción
- Reducción de ruido: Elimina manchas, borrones o artefactos de los documentos escaneados para reducir las falsas detecciones de caracteres.
- Ajuste de contraste y brillo: Un contraste adecuado entre el texto y el fondo facilita que el OCR diferencie los caracteres con mayor precisión.
- Corrección de inclinación: Endereza las imágenes torcidas o rotadas antes del procesamiento. La alineación correcta preserva la estructura de las tablas y la correspondencia entre etiquetas y valores.
- Recorte de áreas irrelevantes: Elimina márgenes, bordes o logos que no forman parte del contenido a extraer. Focalizarse en el área de interés mejora la eficiencia del reconocimiento.
Por qué pequeñas mejoras en la calidad de imagen marcan la diferencia
Un aumento moderado en la resolución, una corrección de inclinación de pocos grados o una mejora de contraste pueden incrementar notablemente la tasa de precisión del OCR. Bordes más nítidos y mejor contraste reducen los errores carácter a carácter y preservan la estructura de tablas y relaciones entre campos. En documentos con alta densidad de datos —como facturas o estados financieros— estos ajustes se traducen en horas menos de corrección manual.
Errores frecuentes que reducen la calidad de la extracción
Conocer los errores más habituales en la extracción de datos de imágenes permite evitarlos y garantizar resultados más limpios y fiables desde el principio.
- Asumir que la salida OCR es perfecta: El texto reconocido por OCR puede contener errores sutiles —confusión entre caracteres similares como "0" y "O", o "1" y "l"— que pasan desapercibidos si no se revisan. No validar el resultado puede derivar en registros incorrectos o análisis defectuosos.
- Ignorar la estructura de la tabla: Extraer texto sin respetar la relación entre filas y columnas genera valores desplazados y hojas de cálculo inutilizables. La herramienta elegida debe ser capaz de preservar esa estructura, no solo capturar el texto.
- Depender exclusivamente de herramientas gratuitas: Las opciones gratuitas o básicas suelen carecer de detección avanzada de diseño y capacidades de IA. Esto conduce a extracciones incompletas o mal formateadas, especialmente en documentos complejos.
- Saltarse la validación: No comparar los datos extraídos con la imagen original aumenta el riesgo de errores no detectados. La validación es un paso rápido que protege la integridad de todo el flujo de trabajo posterior.
Conclusión
Extraer datos de imágenes ha dejado de ser un proceso exclusivo de grandes empresas con infraestructura técnica avanzada. Con las herramientas adecuadas, cualquier profesional puede convertir imágenes a texto estructurado, digitalizar facturas, exportar tablas a Excel y reducir drásticamente el tiempo dedicado a la introducción manual de datos.
La clave está en elegir una solución que vaya más allá del OCR básico: una que reconozca la estructura del documento, preserve tablas y pares etiqueta-valor, y permita exportar directamente a los formatos de trabajo habituales. PDFelement cumple todos estos requisitos y ofrece un flujo de trabajo completo —desde la importación de la imagen hasta la exportación a Excel— sin necesidad de pasos intermedios ni herramientas adicionales.
Si manejas documentos en papel de forma habitual, automatizar su digitalización es una de las mejoras de productividad con mayor retorno y menor curva de aprendizaje.