
PDFelement: un poderoso y sencillo editor de archivos PDF
¡Comienza con la forma más fácil de administrar archivos PDF con PDFelement!
PDF es el acrónimo de Portable Document Format (formato de documento portátil) y está considerado el mejor formato para compartir documentos electrónicos. Los PDF están en todas partes y son vitales en los flujos de trabajo de todas las organizaciones. Los archivos PDF contienen todo tipo de contenidos, incluidas tablas. Los banqueros necesitan extraer información de clientes de las tablas, los profesores necesitan extraer puntuaciones de las tablas para preparar transcripciones y los contables necesitan datos de tablas para crear facturas y recibos.
Aunque hay varias formas de extraer tablas de un PDF, Python está demostrando ser un gran método. Python es un lenguaje de programación informática interactivo utilizado para el desarrollo de sitios web y software. Sin embargo, también ofrece una plataforma para leer y extraer tablas de archivos PDF. Puedes extraer la tabla deseada de un PDF con Python con un fragmento de código adecuado. Este artículo te guía a través de la forma más sencilla de extraer una tabla de un PDF con Python.
Método 1: Utilizar Tabular-Py Python Wrapper para extraer tablas de un PDF
Tabular-py es una extensión de Java tabular - una biblioteca java que permite a los usuarios leer el contenido de una tabla incrustada en un documento PDF. Lee el contenido de la tabla y lo convierte a pandas DataFrame. Con tabula-py, puedes convertir tu archivo PDF en archivos CSV, TSV o JSON. Sin embargo, tu sistema debe tener Java8+ y Python 3.7+. Deberías ejecutar los siguientes comandos para descargar e instalar automáticamente las dependencias de Java necesarias en tu sistema.
$ pip install tabula-py
$ pip install tabulate
Supongamos que la ruta de guardado del PDF con la tabla de destino es /home/Ubuntu/data.pdf; puedes ejecutar el siguiente código en el terminal para extraer la tabla de tu PDF y guardarla como CSV, TSV o JSON.
Importar tabula
# comienza importando la biblioteca tabula
Importar tabula
# leer tabla desde fichero pdf
dfs = tabula-read_pdf("/home/ubuntu/data.pdf",pages="all")
# convierte tu tabla PDF en formato CSV
tabula.convert_into ("/home/ubuntu/data.pdf","output.csv","outpour_format="csv", pages="all")
También puedes extraer e imprimir la tabla desde el terminal utilizando el siguiente código.
from tabula import read_pdf
from tabulate import tabulate
# Este comando lee la tabla en tu archivo PDF
df = read_pdf("/home/ubuntu/data.pdf",pages="all")
# Este comando imprime tu archivo PDF en el terminal
print(tabulate(df)
El comando read_pdf () lee el contenido de la tabla de tu archivo PDF.
El comando tabulate() organiza los datos leídos en forma de tabla.
Consejos y notas
- Asegúrate de que Java está presente en tu sistema.
- Intenta obtener conocimientos básicos de Python para facilitar el trabajo.
Método 2: Utilizar la librería Camelot-Py Python para extraer una tabla de un PDF
Camelot es otra útil biblioteca de Python que puedes utilizar para extraer tablas de PDF. Lo mejor de Camelot es el nivel de control que ofrece. Esta biblioteca te ofrece más posibilidades para personalizar la extracción de tablas y satisfacer tus necesidades. Además, cada tabla es un Pandas DatFrame fácil de integrar en ETL y flujos de trabajo de análisis de datos. Con la biblioteca Camelot, puedes exportar tus tablas a diversos formatos de archivo, como JSON, Excel, HTML y Sqlite.
Para instalar la biblioteca Camelot en tu sistema, ejecuta el siguiente comando.
$ pip install camelot-py
A diferencia de tabula-py, Camelot utiliza matrices e índices para acceder a una tabla concreta de tu archivo PDF. Primero se lee la tabla con la función read_pdf () y se almacenan las tablas en una matriz de tablas. Las matrices empezarán obviamente por las tablas [0], luego las tablas [1] y así sucesivamente. Para imprimir un PDF en el terminal, puedes ejecutar el siguiente código.
importar camelot
# extraer todas las tablas del archivo PDF
abc = camelot.read_pdf("/home/ubuntu/data.pdf")
# imprimir la primera tabla como Pandas DataFrame
print(abc[0].df)
El comando import Camelot importa la biblioteca Camelot para su uso en el programa. Si la biblioteca Camelot no está instalada, Python imprimirá un mensaje de error en su lugar.
El comando Camelot.read_pdf () lee el contenido de tu tabla PDF y lo almacena en una matriz de tablas abc.
El comando print (abc[0].df) imprime en el terminal la primera tabla de la matriz, es decir, la tabla [0].
Consejos y notas
- Utiliza la función de análisis sintáctico para descartar tablas erróneas en función de la precisión y los espacios en blanco.
- Si deseas extraer tablas de diferentes páginas y quieres cambiar el orden de extracción, puedes utilizar el comando orden dentro de la función de análisis sintáctico.
- Intenta familiarizarte con la sintaxis de Python para minimizar las dificultades de conversión.
[Bono] PDFelement: Extrae tablas de PDF de forma más cómoda que con Python
Aunque Python es útil para extraer tablas de PDF, no ofrece la comodidad de una herramienta de extracción de datos de PDF específica. Python es un lenguaje de programación, y no es fácil entender y memorizar la sintaxis. Si eres nuevo en Python, quizás leas la primera línea y te desanimes. Se requieren conocimientos profesionales para navegar y extraer tablas de PDF con facilidad y precisión. Aunque seas un profesional, el proceso de escribir y ejecutar códigos para extraer datos de tablas es largo y pesado.
Afortunadamente, PDFelement resuelve este problema ofreciéndote una cómoda plataforma para extraer tablas de PDF. La interfaz es elegante y fácil de usar. Si eres un novato, te resultará extremadamente fácil navegar y extraer tablas de un PDF. No necesitas conocimientos de codificación ni experiencia para extraer tablas en PDF con este software. Además, Wondershare PDFelement es compatible con varios dispositivos y sistemas operativos, incluidos Windows, Mac e iOS. No tienes que preocuparte de añadir bibliotecas porque este programa está totalmente equipado. Una vez más, su asombrosa velocidad de procesamiento y su asequibilidad la convierten en una herramienta conveniente para todos los usuarios, incluidos los aficionados.
Método 1: Extraer tablas manteniendo el formato original
A veces se desea extraer tablas de un PDF sin cambiar el formato original. Esto es útil cuando necesitas tanto la tabla como el contenido, cuando quieres presentar la tabla exactamente en el mismo formato o cuando no te interesa modificar el diseño de la tabla. Este proceso es rápido y sencillo en PDFelement, como se ilustra a continuación.
Paso 1 En primer lugar, inicia PDFelement en tu dispositivo y carga el archivo del que deseas extraer las tablas. Alternativa: haz clic con el botón derecho en el archivo PDF y ábrelo con Wondershare PDFelement.
Paso 2 Una vez cargado el archivo PDF, ve a la barra de herramientas y haz clic en la pestaña "Convertir". De las opciones que aparecen debajo, elige la opción "A Excel".
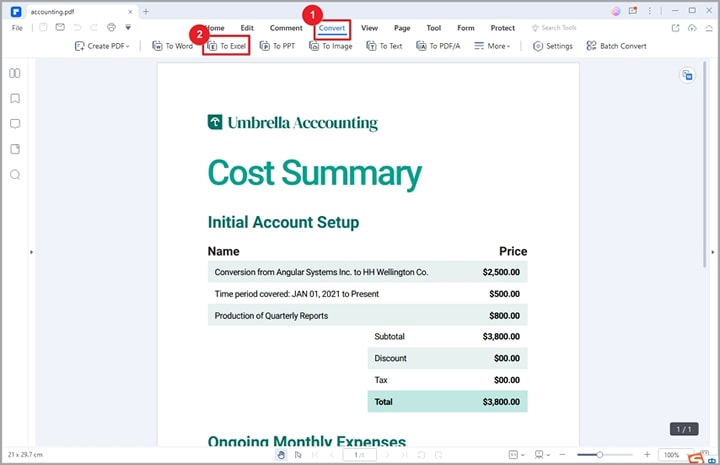
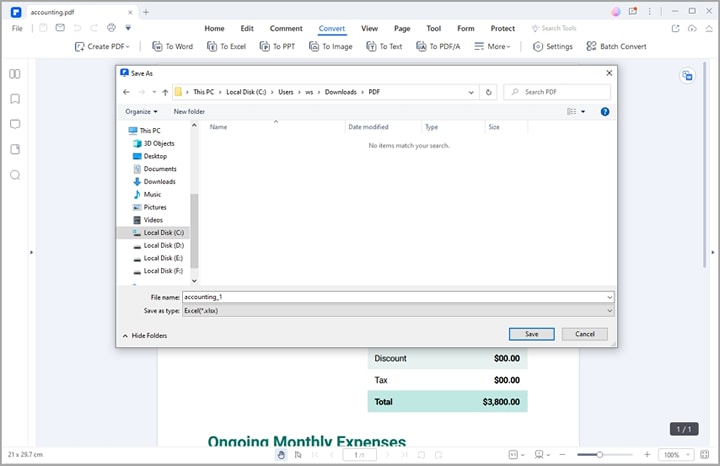
Paso 3 PDFelement te llevará automáticamente a la ventana de salida "Guardar como". Aquí, elige una carpeta de destino adecuada y haz clic en el botón "Guardar". PDFelement convertirá inmediatamente tu archivo PDF en un archivo Excel. Abre el archivo Excel para comprobar la tabla.
Consejos y notas
- Si manejas varios archivos, utiliza el proceso por lotes para ahorrar tiempo y energía.
- Si tienes un archivo de varias páginas y sólo necesitas una parte, córtala antes de convertir el PDF a Excel.
Método 2: Extraer sólo datos de PDF a CSV
En otros casos, no te preocupa el formato de la tabla, sino su contenido. En este caso, sólo deberás extraer el contenido de la tabla del PDF. Afortunadamente, PDFelement permite a los usuarios extraer datos sólo de PDF a CSV. CSV es un formato de texto plano que organiza los datos en forma de tabla utilizando comas.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
PDFelement Te permite extraer datos de un formulario rellenable en PDF. Sin embargo, el formulario PDF debe contener campos de formulario rellenables antes de extraer los datos de la tabla PDF a CSV. Si los campos del formulario no son rellenables/reconocibles, necesitará la función OCR de PDFelementos para hacerlos reconocibles/rellenables. Los pasos se ilustran a continuación.
Paso 1 Abre tu archivo PDF con PDFelement. Asegúrate de que tu versión de PDFelement tiene instalado el plugin OCR.
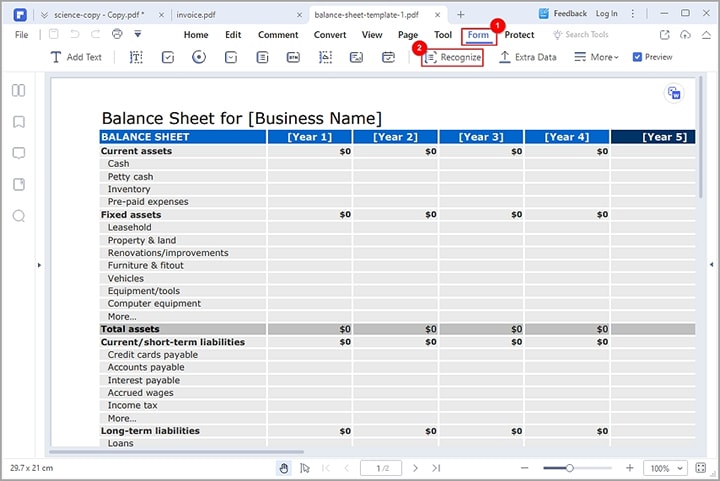
Paso 2 Ve a la sección "Formulario" y haz clic en el icono "Reconocer" de entre las varias opciones que aparecen debajo. PDFelement hará que los campos de tus formularios PDF sean automáticamente reconocibles.
Ahora que el archivo PDF es reconocible, debes proceder a extraer los datos de la tabla de tu archivo PDF de la siguiente manera.
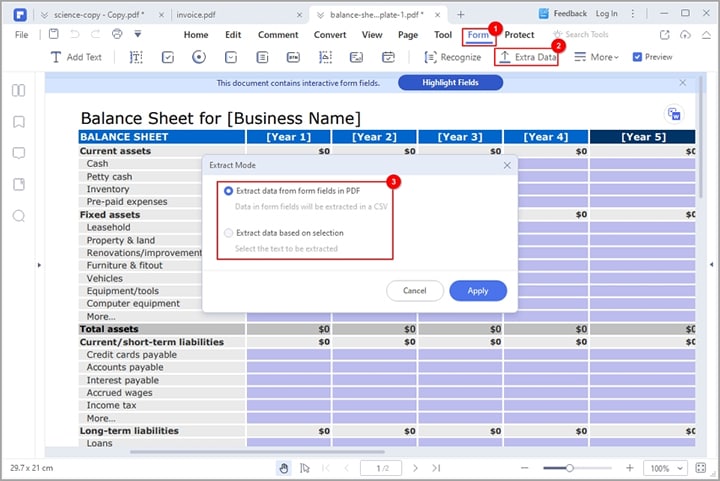
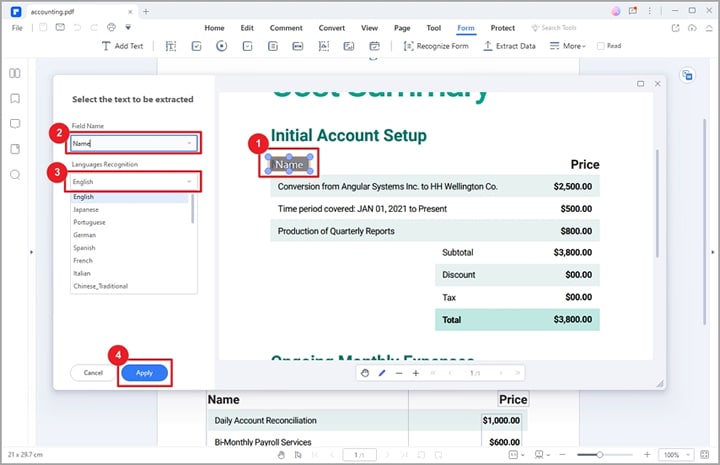
Paso 1Ve a la barra de herramientas y haz clic en la pestaña "Formulario". En las opciones que aparecen, haz clic en la opción "Extraer datos".
Paso 2 PDFelement mostrará la ventana de diálogo "Extraer datos" en la pantalla. Aquí, puedes elegir entre "Extraer datos de los campos del formulario" o "Extraer datos basados en la selección". Cuando elijas la opción "Extraer datos de los campos del formulario", los campos de tu formulario se extraerán a un archivo CSV.
Si eliges la opción "Extraer datos en función de la selección", deberás seleccionar cada campo de formulario a extraer utilizando el cursor en el cuadro de diálogo emergente. A continuación, introduce el nombre de los campos de formulario seleccionados y selecciona un idioma de reconocimiento adecuado.
Paso 3 Tras seleccionar todos los campos de formulario deseados, haz clic en el botón "Aplicar". PDFelement extraerá inmediatamente los datos sólo de PDF a CSV.
Consejos y notas
- Si deseas extraer datos de campos no rellenables, asegúrate primero de que está instalado el plugin OCR para el reconocimiento de PDF.
- Utiliza el proceso por lotes si tienes varios PDF de los que necesitas extraer datos de la misma área o quieres extraer datos de un formulario PDF con varias tablas que contienen datos diferentes.
- La función "Extraer datos en función de la selección" puede aplicarse tanto a formularios PDF basados en texto como escaneados.
- Dado que tienes que seleccionar manualmente cada campo del formulario, utiliza la opción "Extraer datos en función de la selección" cuando necesites pocos datos.
Extraer tablas de un PDF con Python requiere conocimientos y experiencia en programación. Sin embargo, PDFelement te acerca a la extracción de tablas PDF con una interfaz intuitiva y fácil de usar. El proceso es sencillo y cómodo para todos los usuarios, incluidos los novatos. Descarga PDFelement hoy mismo y disfruta de una experiencia inigualable al extraer tablas de PDF.
