Cuando digitalizas documentos físicos con un escáner, los archivos resultantes suelen guardarse como PDF basados en imágenes. Para ti, el documento contiene letras, palabras y párrafos. Para tu ordenador, en cambio, no es más que una imagen plana: un conjunto de píxeles. No puedes seleccionar el texto, copiar un párrafo ni usar "Ctrl+F" o "Command+F" para encontrar una palabra clave concreta.
Para empresas, investigadores y usuarios que trabajan con grandes volúmenes de documentación, esta limitación se convierte rápidamente en un cuello de botella. Si no puedes buscar dentro de tus archivos digitales, buena parte del valor de digitalizar documentos se pierde.
Por suerte, existe una solución fiable para este problema: el reconocimiento óptico de caracteres (OCR). Con esta tecnología, puedes convertir PDF a PDF con búsqueda y transformar imágenes estáticas en documentos dinámicos e interactivos. En esta guía verás cómo convertir PDF escaneados e imágenes en archivos editables y con texto buscable, tanto si trabajas con un solo documento como si necesitas procesar muchos archivos o convertir una simple imagen JPG.
¿Cuáles son las diferencias entre un PDF escaneado y un PDF con búsqueda?
Antes de entrar en el proceso de conversión, conviene entender la diferencia básica entre los tipos de PDF con los que sueles trabajar.
Anatomía de un PDF escaneado
Un PDF escaneado se crea cuando un documento físico pasa por un escáner o cuando un archivo digital se "aplana" y se convierte en una imagen. En ese estado, el texto queda incrustado dentro de un mapa de bits. El archivo puede conservar muy bien el aspecto original del documento, pero tiene una limitación importante: no permite interactuar con el texto como texto real. El ordenador no reconoce letras, palabras ni párrafos; solo interpreta una imagen.
Anatomía de un PDF con búsqueda
Un PDF con búsqueda, en cambio, combina dos capas. La capa inferior conserva la representación visual del documento escaneado, es decir, la imagen original. Encima se añade una capa invisible de texto generada por el motor OCR. Como esa capa de texto queda alineada con la imagen, puedes seleccionar, resaltar, copiar y buscar palabras concretas sin que el documento pierda su apariencia original.
Resumen de las diferencias clave
Aquí tienes una comparación rápida entre ambos formatos:
| Función/Capacidad | PDF escaneado (basado en imagen) | PDF con búsqueda (procesado con OCR) |
| Búsqueda de texto | No permite buscar palabras o frases dentro del documento. | Permite encontrar palabras y frases con la función de búsqueda. |
| Selección de texto | No puedes resaltar ni copiar el contenido como texto. | Puedes seleccionar, resaltar y copiar el contenido con facilidad. |
| Edición | No permite modificar el texto de forma nativa. | El texto puede ser editable, según la configuración OCR elegida. |
| Accesibilidad | Los lectores de pantalla no pueden interpretar correctamente el contenido. | Los lectores de pantalla pueden analizar y leer el texto en voz alta. |
Por qué necesitas convertir a PDF con búsqueda (beneficios clave)
Dar el paso adicional de convertir un PDF escaneado a PDF con búsqueda aporta mucho valor en flujos de trabajo profesionales, académicos y personales.
Resumen: Beneficios clave
- Recuperación de documentos y eficiencia en el flujo de trabajo: si un bufete de abogados o un departamento de RR. HH. tiene miles de contratos digitalizados, localizar una cláusula específica leyendo PDF basados en imágenes puede llevar horas o incluso días. Al convertir esos archivos en PDF con búsqueda, puedes encontrar el documento exacto y el párrafo que necesitas en segundos mediante una búsqueda por palabras clave.
- Extracción de datos y edición: investigadores y analistas a menudo necesitan extraer estadísticas, citas o tablas de informes impresos antiguos. En lugar de transcribir páginas enteras a mano, un proceso lento y propenso a errores, la conversión OCR permite copiar y pegar el texto necesario en Word, Excel u otras herramientas de análisis.
- Accesibilidad y cumplimiento: los estándares modernos de accesibilidad digital exigen que los documentos puedan leerse con tecnologías de asistencia, como los lectores de pantalla. Un PDF escaneado plano no cumple bien esa función, porque el lector de pantalla solo detecta una imagen. Añadir una capa de texto buscable ayuda a que el contenido sea más accesible para todos los usuarios.
Qué es el OCR: la tecnología que hace que un PDF sea buscable
Para entender cómo se convierte un PDF escaneado en un documento buscable, hay que hablar del OCR. OCR significa reconocimiento óptico de caracteres, una tecnología de software que analiza documentos basados en imágenes, como escaneos y fotografías, para detectar y extraer texto.
Cuando aplicas OCR a un documento, el software examina las formas, líneas y curvas de los píxeles oscuros sobre el fondo claro. Mediante reconocimiento de patrones e inteligencia artificial, identifica esas formas y las asocia con letras, números y símbolos conocidos.
Durante el proceso de conversión, herramientas como Wondershare PDFelement suelen ofrecer dos resultados principales:
- Texto buscable en imagen: crea una capa de texto invisible sobre la imagen original. Es una opción adecuada para archivar documentos, porque conserva el aspecto del escaneo y añade la posibilidad de buscar dentro del archivo.
- Texto editable: va un paso más allá e intenta sustituir la imagen del texto por texto digital editable con un aspecto similar al original. Es útil si necesitas reescribir, borrar o actualizar partes del documento.
Cómo convertir PDF escaneados a PDF con búsqueda (solución de escritorio)
Convertir archivos PDF escaneados en PDF con búsqueda es sencillo si cuentas con un programa compatible con OCR. Para esta tarea, un software de escritorio suele ser una buena opción, ya que procesa los archivos localmente en tu equipo, ayuda a proteger documentos sensibles y suele ofrecer más control que muchas herramientas web.
Wondershare PDFelement es un editor PDF con función OCR integrada. Permite convertir PDF escaneados en documentos con búsqueda, manteniendo el diseño del archivo original con buena fidelidad.




Paso 1.Abre tu documento escaneado
Primero, visita el sitio web oficial para descargar e instalar una versión compatible del software en tu ordenador Windows o Mac. A continuación, abre la aplicación.

En la interfaz principal, localiza el icono "Abrir PDF" en la esquina inferior izquierda o derecha y haz clic en él.
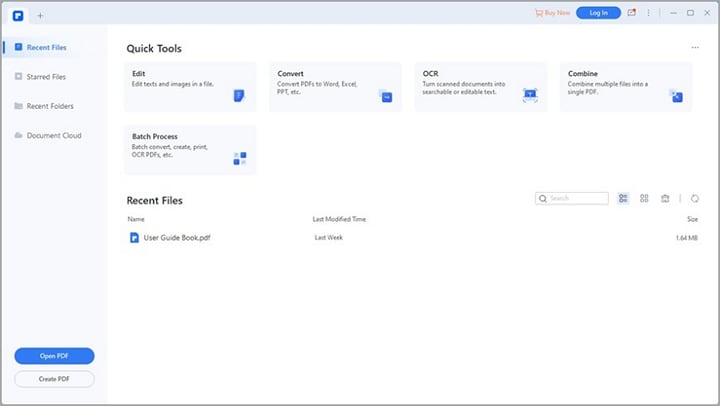
Busca el archivo en tu ordenador, selecciona el PDF escaneado que quieres convertir y haz clic en "Abrir" para cargarlo en el espacio de trabajo.
Paso 2.Descarga y activa el motor OCR
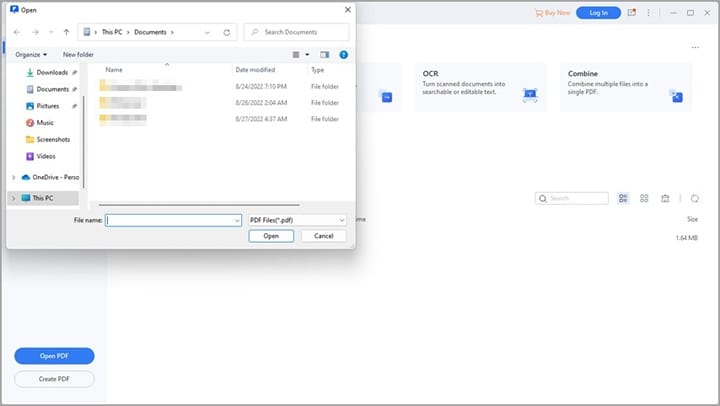
PDFelement detecta automáticamente cuando un documento está compuesto por imágenes. Al abrir el archivo, puede aparecer una barra de notificación en la parte superior recomendando aplicar OCR.
Si es la primera vez que usas esta función, haz clic en "Realizar OCR". El software te pedirá descargar el componente OCR, que se instala por separado para reducir el tamaño del instalador principal. Haz clic en "Descargar OCR" y espera a que termine la instalación.
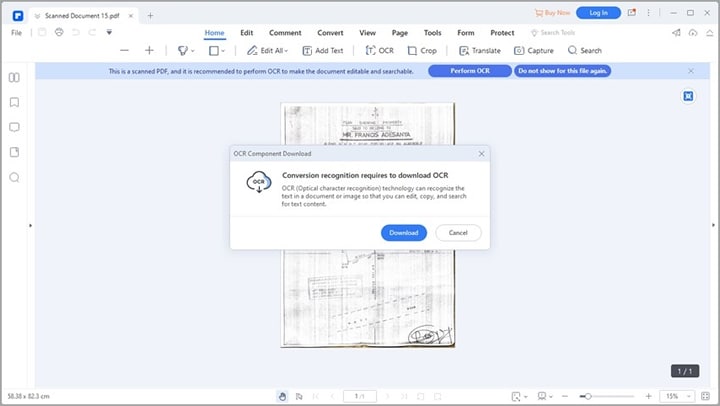
Una vez descargado, verás un aviso de confirmación. Haz clic en "OK".
Paso 3.Realiza la conversión OCR
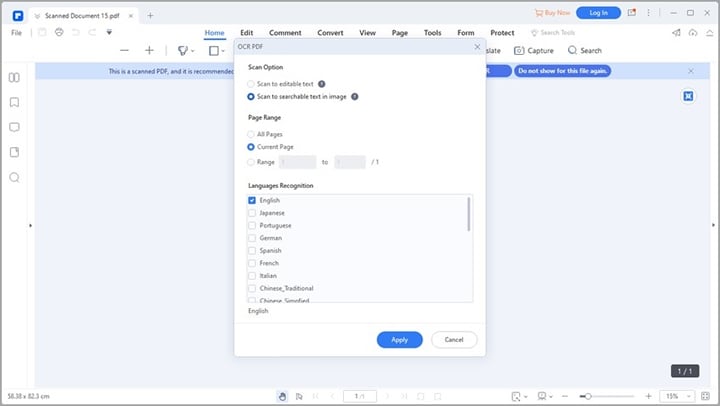
Ve al menú superior y haz clic en "Herramientas" > "OCR". Se abrirá un cuadro de diálogo con opciones para personalizar la conversión.
Deberás elegir el tipo de reconocimiento que quieres aplicar:
- Selecciona "Escanear a texto buscable en imagen" si quieres conservar la apariencia visual de la página escaneada y, al mismo tiempo, poder resaltar y buscar texto.
- Selecciona "Escanear a texto editable" si necesitas modificar frases, cambiar fuentes o eliminar párrafos.
Asegúrate también de seleccionar el idioma correcto del documento en la lista, ya que esto mejora mucho la precisión del reconocimiento. Por último, haz clic en "Aplicar".
El software procesará el documento. En unos segundos tendrás un PDF con texto buscable. Desde ahí, podrás guardarlo o convertirlo a otros formatos, como Word, Excel o PowerPoint.
Cómo convertir por lotes varios PDF escaneados en PDF con búsqueda
Si tienes muchos documentos acumulados, convertirlos uno por uno resulta poco práctico. Para estos casos, el procesamiento por lotes es mucho más eficiente. PDFelement incluye una herramienta OCR por lotes que permite convertir varios documentos escaneados a la vez.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
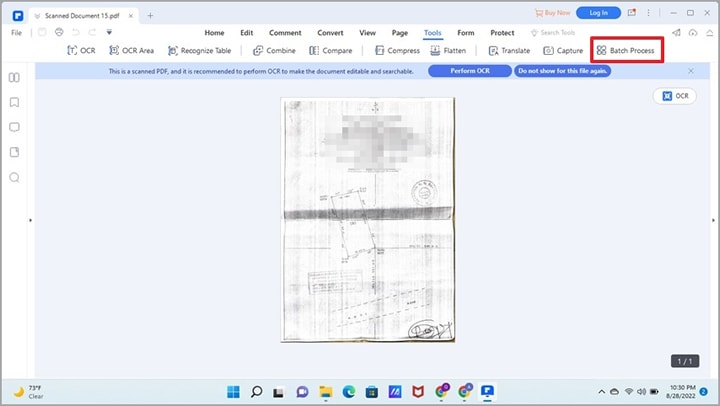
Paso 1.Accede a la herramienta de proceso por lotes
Abre el software en tu ordenador. Desde la pantalla de inicio, localiza la tarjeta "Proceso por lotes". También puedes abrir cualquier PDF, ir a la pestaña "Herramienta" del panel superior y seleccionar "Proceso por lotes".
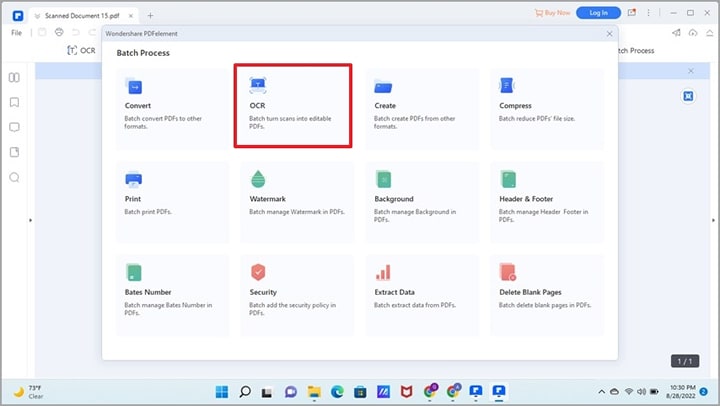
Paso 2.Selecciona la función OCR
Aparecerá una nueva ventana con varias operaciones por lotes, como convertir, comprimir o imprimir. Selecciona la opción "OCR" en ese menú.
Paso 3.Configura tus opciones OCR
En el panel derecho, ajusta la configuración. En el menú desplegable "Opción OCR", elige entre "Texto editable" o "Imagen de texto buscable" según lo que necesites. Debajo, selecciona cuidadosamente los idiomas presentes en tus documentos.
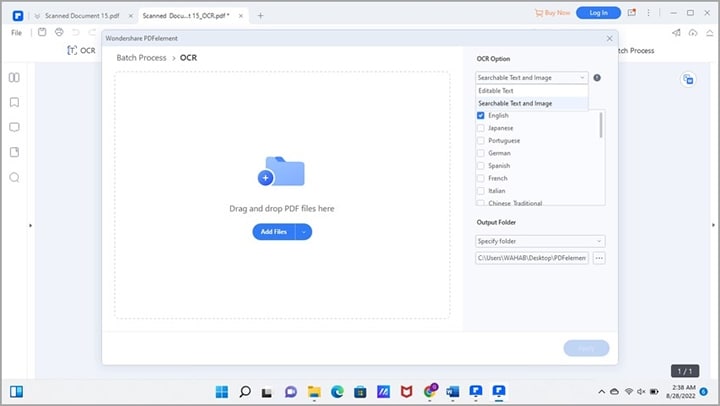
Paso 4.Añade tus archivos y aplica la conversión
En el centro de la pantalla verás un área grande con el mensaje "Arrastra y suelta aquí archivos PDF". Puedes arrastrar tus documentos escaneados directamente o hacer clic para abrir el explorador y seleccionarlos manualmente.
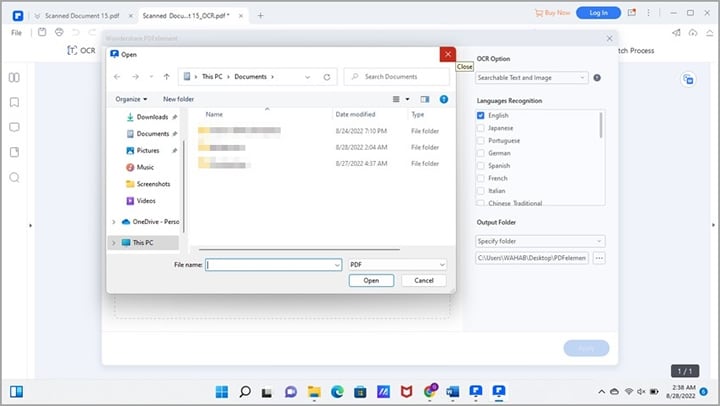
Cuando todos los archivos estén en la cola, selecciona una carpeta de salida en la parte inferior de la pantalla y haz clic en "Aplicar". El software procesará el lote y convertirá los documentos en PDF con búsqueda.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
De imagen a texto: cómo convertir JPG a PDF editable
A veces, los documentos que necesitas digitalizar ni siquiera están en formato PDF. Puede que hayas fotografiado un recibo, una pizarra o la página de un libro con tu móvil y tengas un archivo JPG o PNG. También puedes convertir un JPG a PDF editable utilizando la misma tecnología OCR.
Paso 1.Crea un PDF a partir de la imagen
En una herramienta como PDFelement, puedes arrastrar y soltar el archivo JPG en la ventana de la aplicación. El software convertirá la imagen en un PDF basado en imagen.
Paso 2.Activa OCR
Igual que con un documento escaneado, el software detectará que el nuevo PDF está basado en una imagen.
Paso 3.Selecciona texto editable
Cuando hagas clic en "Realizar OCR", selecciona la opción "Escanear a texto editable".
Paso 4.Edita el documento
Después del procesamiento, el texto capturado en la fotografía será editable. Podrás corregir errores, cambiar el tamaño de la fuente o extraer los datos a otro programa.
Cómo convertir PDF a PDF con búsqueda gratis
No todo el mundo necesita un software de escritorio de pago para conversiones puntuales. Si buscas convertir PDF a PDF con capacidad de búsqueda gratis, hay varias opciones disponibles, aunque conviene tener claros sus límites.
Pruebas gratuitas de programas de escritorio
La mayoría de los editores PDF profesionales, incluido Wondershare PDFelement, ofrecen versiones de prueba gratuitas. Esta puede ser una buena opción si tienes una necesidad puntual, si quieres convertir varios archivos o si trabajas con documentos confidenciales que prefieres no subir a un servidor externo.
Herramientas OCR gratuitas en línea
También existen herramientas web, como HiPDF, PDF24 o la función OCR de Google Drive, que permiten cargar un PDF escaneado y obtener una versión con texto buscable sin coste para usos básicos.
Si tienes un documento breve y no confidencial, un convertidor gratuito en línea puede ser una solución rápida y práctica. Sin embargo, para documentos legales, registros financieros o grandes volúmenes de archivos, un software de escritorio sin conexión suele ser una vía más segura y eficiente.
Mejores prácticas para obtener la máxima precisión OCR
La tecnología OCR ha avanzado mucho, pero no es infalible. La calidad del PDF con búsqueda depende en gran medida del archivo original. Para conseguir mejores resultados, ten en cuenta estas recomendaciones:
- Asegura una alta resolución: procura escanear los documentos al menos a 300 DPI (puntos por pulgada). Si el texto está borroso o pixelado, el motor OCR tendrá más dificultad para distinguir letras como "c" y "e" o caracteres como "l" y "1".
- Comprueba el contraste: el texto negro sobre fondo blanco ofrece los mejores resultados. Si has fotografiado un documento con poca luz, considera mejorar el contraste antes de aplicar OCR.
- Endereza las páginas: el texto inclinado o torcido puede confundir a los algoritmos de OCR. Muchas herramientas PDF modernas incluyen funciones de enderezado automático para alinear las páginas antes del reconocimiento.
- Selecciona los idiomas correctos: si el documento contiene varios idiomas, por ejemplo inglés y español, selecciónalos en la configuración OCR para que el motor reconozca mejor acentos, caracteres especiales y vocabulario específico.
Conclusión
Transformar archivos estáticos en documentos útiles no tiene por qué ser complicado. Tanto si quieres buscar una palabra clave en un contrato antiguo, digitalizar un archivo físico o convertir un JPG a PDF editable, la tecnología OCR es la base del proceso.
Al usar herramientas capaces de convertir PDF a PDF con búsqueda, puedes buscar, resaltar, copiar y editar contenido que antes estaba atrapado en una imagen. Las herramientas gratuitas en línea pueden servir para tareas ocasionales y documentos no confidenciales, pero un software de escritorio como PDFelement ofrece más control, privacidad y eficiencia cuando trabajas con archivos sensibles o con grandes volúmenes de documentos. Evalúa tus necesidades, elige el método que mejor encaje con tu flujo de trabajo y empieza a sacar más partido a tus PDF digitalizados.