
En situaciones cotidianas o empresariales, es posible que necesites escanear y transcribir textos en archivos, imágenes, facturas y recibos. La API de reconocimiento óptico de caracteres (OCR) desempeña un papel fundamental a la hora de extraer texto de imágenes y archivos PDF y recibir los datos en formato JSON, CSV, Excel u otros formatos de archivo.
Este artículo te presentamos la API de OCR y tres de las API de OCR más populares, incluidas Google Vision, Microsoft Computer Vision y Amazon Textract. Este artículo también presenta PDFelement, una solución de OCR más práctica.
En este artículo
OCR API puede analizar el marco de los archivos y romper los archivos en bloques de tablas o líneas de texto. A continuación, las líneas se subdividen en una sola palabra y caracteres. Una empresa puede construir integraciones con los sistemas existentes mediante el uso de APIs. Esto puede ayudar a satisfacer las necesidades específicas de negocio y ayudar a reducir el tiempo que se requiere para capacitar a los empleados en una nueva plataforma.
Las 3 mejores herramientas API de OCR
Google Vision
Google Vision es un servicio de OCR en la nube. Puede identificar contenidos escritos a mano, textos sin formato y otras formas de datos. También puede detectar información de documentos e imágenes escaneados y permite implementar el OCR en los flujos de trabajo de RPA.
Google Vision no es un producto "listo para usar", así que antes de utilizarlo, asegúrate de que tienes conocimientos de programación y experiencia en el manejo de una cantidad decente de codificación. Asegúrate también de que tienes conocimientos profesionales en la adición de interfaces de usuario para el escaneado y la validación de datos.
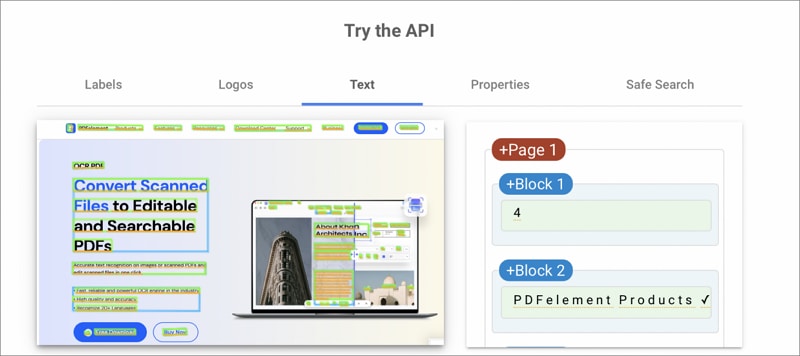
Existen varias soluciones entre las que puedes elegir. Los precios incluyen API de Cloud Vision de pago por uso, cargos mensuales escalables y tarifas planas por nodo hora con pruebas gratuitas para AutoML Vision y AutoML Vision Edge. Puedes crear una cuenta para evaluar el coste si eres un principiante.
Microsoft Computer Vision
Microsoft Azure Computer Vision OCR es un servicio de IA que analiza contenido en imágenes y vídeo. Puede extraer una cadena y su información de un elemento de interfaz de usuario indicado o de una imagen.
Las características básicas de Microsoft Computer Vision contienen la extracción de texto (OCR), comprensión de imágenes, análisis espacial, y el despliegue flexible. Sobre la base de la incorporación de capacidades de visión en la nube en las aplicaciones con ella, puede aumentar la capacidad de descubrimiento de contenido, análisis de vídeo instantánea, y la extracción automática de datos. Además, puede ser utilizado para otras ocasiones OCR, como haga clic en el texto OCR, Hover texto OCR, haga doble clic en el texto OCR, Obtención de texto OCR, y la búsqueda de la posición del texto OCR.
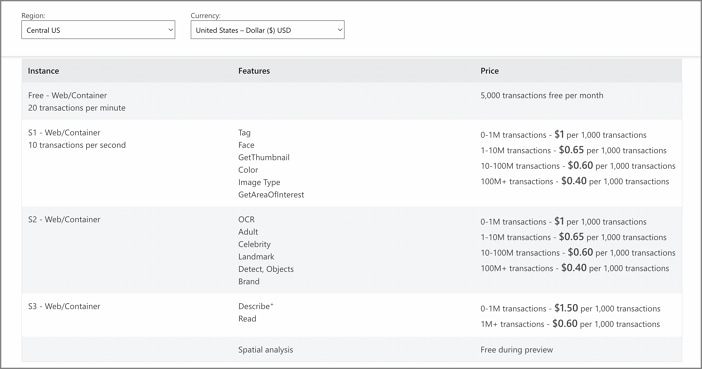
El coste de Microsoft Computer Vision depende de la frecuencia de las transacciones. La API de Computer Vision es gratuita si sólo necesitas 5.000 transacciones gratuitas al mes, sin embargo, sería cara si requieres más.
Amazon Textract
Amazon Textract es un servicio que puede extraer contenido, texto y datos de documentos automáticamente. Más allá de una simple tecnología OCR, puede reconocer datos de formularios y tablas. Usando Textract, lo que el usuario necesita hacer es subir el archivo, entonces en poco tiempo, el usuario obtendrá el texto, tabla y formularios en un archivo estructurado.
Textract OCR se basa en una red neuronal de aprendizaje profundo. Si alguien verifica la información extraída (humano en el bucle), puede ajustarse a los datos y aprovechar la precisión en la arquitectura. Sin embargo, no es completamente personalizable o entrenado en un conjunto de datos personalizado.
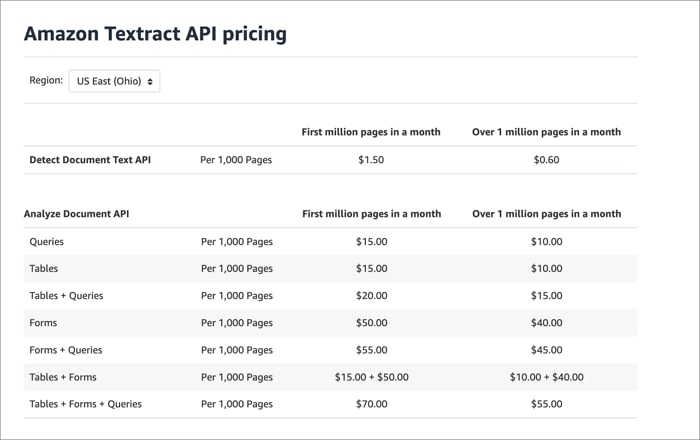
Existen cuatro API diferentes en Amazon Textract: District Document Text API, Analyze Document API, Analyze Expense API y Analyze ID API. El paquete gratuito sólo dura tres meses, y los detalles de cada mes son los siguientes.
- Detect Document Text API: 1000 páginas
- Analyze Document API: 100 páginas al mes (funciones de formulario o tabla) y 100 páginas adicionales
- API Analyze Expense: 100 páginas
- Analyze ID API: 100 páginas al mes
Casos de uso de la API de OCR
Las API de OCR son importantes en muchos casos del mundo real. He aquí algunos ejemplos:
Servicios financieros
Las industrias financieras, junto con la banca, conceden mucha importancia al OCR. Lo utilizan para escanear y reconocer texto manuscrito de cheques, extractos bancarios y cuentas de resultados. Se puede ahorrar tiempo en el procesamiento de solicitudes de préstamos e hipotecas.
Salud
El OCR permite a hospitales y organizaciones almacenar digitalmente todos los historiales de los pacientes. Las enfermedades pasadas, los tratamientos y las pruebas diagnósticas se pueden buscar en una base de datos. Además, la extracción de datos de las solicitudes de seguros ayuda a ofrecer un mejor servicio entre los pacientes y las compañías de seguros.
Legal
En el ámbito legal hay muchos contenidos escritos a mano. Este sector puede digitalizar declaraciones, declaraciones juradas, sentencias, testamentos, expedientes y otros documentos impresos con lectores de OCR. Además, el OCR permite buscar y encontrar documentos de millones de casos pasados.
Limitaciones de las API de OCR en algunas ocasiones
Aunque las API de OCR son prácticas y ofrecen un resultado preciso en la mayoría de los casos, siguen teniendo algunas limitaciones. No son convenientes en las siguientes situaciones.
Carácter similar
Algunos programas de OCR no distinguen bien los caracteres parecidos, por ejemplo, reconocer la diferencia entre el número "0" y la letra "O" es todo un reto.
Contenido de la escritura
Pueden existir grandes diferencias en la forma de escribir a mano de cada uno. Si la palabra no está escrita con claridad, es posible que el OCR no la identifique.
Lenguaje complejo
Muchos programas de OCR son buenos extrayendo contenido en inglés. Sin embargo, si subes un archivo en un idioma con variaciones en las letras cursivas, como el árabe, es posible que el resultado no te satisfaga.
Fuente
Algunas API de OCR tienen dificultades para transcribir caracteres demasiado pequeños o demasiado grandes.
El mejor software de OCR para computadores y celulares
En comparación con las herramientas profesionales mencionadas anteriormente, si buscas un software fácil de usar para extraer texto de documentos, PDFelement es tu mejor opción. Ofrece una interfaz intuitiva y avisos para garantizar una experiencia de usuario sin problemas. Aunque no tengas experiencia en el uso de OCR, podrás extraer texto del archivo con éxito la primera vez.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
PDFelement te ofrece una gran variedad de funciones. Te permite realizar todas las ediciones o modificaciones de PDF en esta única aplicación. En cuanto al OCR, puedes convertir libremente el archivo a partir de una imagen o un PDF escaneado. Tras la conversión, puedes utilizar el formato que desees para exportar el archivo.
PDFelement OCR es compatible con muchos idiomas ampliamente utilizados, como inglés, alemán, francés, italiano, portugués, español, rumano, turco, ruso, polaco, checo, holandés, húngaro, tailandés, vietnamita, sueco, malayo e indonesio. La salida de texto en estos idiomas se prueba miles de veces para asegurarse de que te ofrece un resultado exacto y preciso.
Y lo que es más importante, PDFelement está diseñado para soportar diversas situaciones. Puedes descargarlo como aplicación individual en tu computador o celular. Además, se adapta tanto al sistema Windows como a macOS. En el modo sin conexión, el reconocimiento de sólo texto para extraer texto de documentos escaneados sigue estando disponible.
Si te desconcierta procesar un documento de gran tamaño, PDFelement también es la mejor opción. Con el software, puedes hacer OCR a un PDF con un máximo de páginas de hasta 100. Además, puedes procesar OCR en hasta 10 archivos simultáneamente. El PDF por lotes que se muestra a continuación está diseñado para que puedas manejar varios documentos.
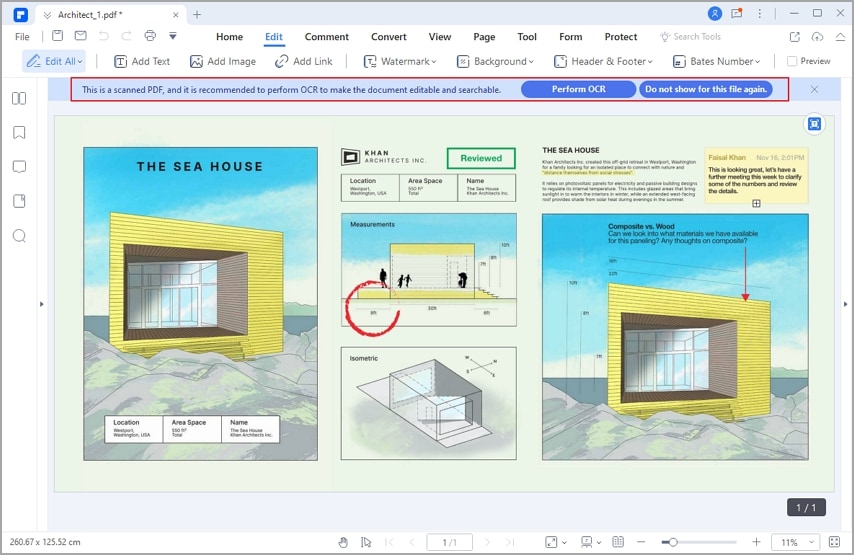
Pasos para utilizar PDFelement OCR en dispositivos iOS
Para convertir un archivo con PDFelement OCR, realiza los siguientes pasos: selecciona OCR, selecciona un idioma y descarga el resultado. La siguiente figura muestra un ejemplo de cómo utilizar PDFelement para iOS para convertir un archivo mediante OCR en iPhone.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Paso 1: Cargar el archivo.
Inicia la aplicación PDFelement en tu iPhone. En la página de inicio, busca "Herramientas" y pulsa "OCR PDF". Seleccione el archivo para iniciar una nueva tarea.
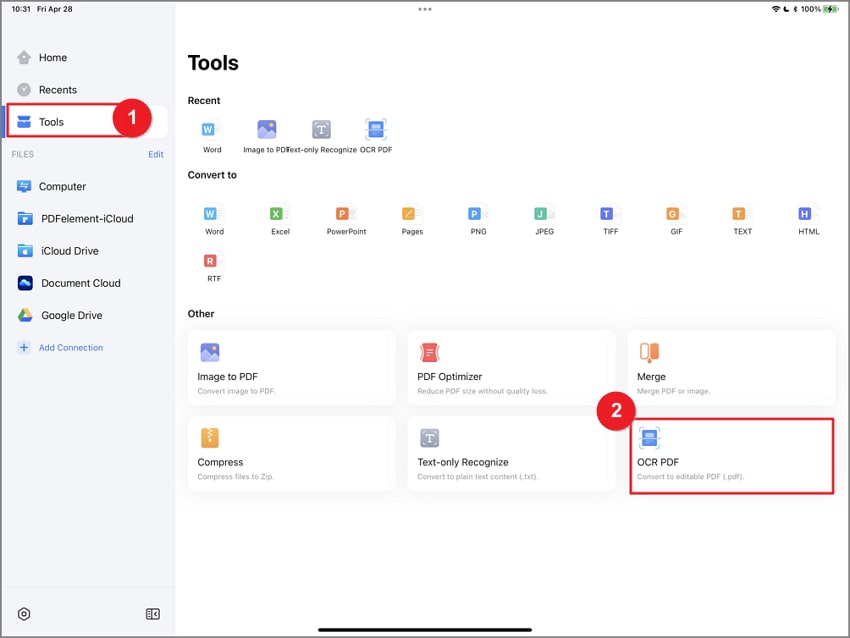
Paso 2: Selecciona un idioma
Puedes seleccionar un idioma de texto como se indica en la página. Puedes seleccionar hasta tres idiomas al mismo tiempo. A continuación, toca "Siguiente" para procesar el documento.
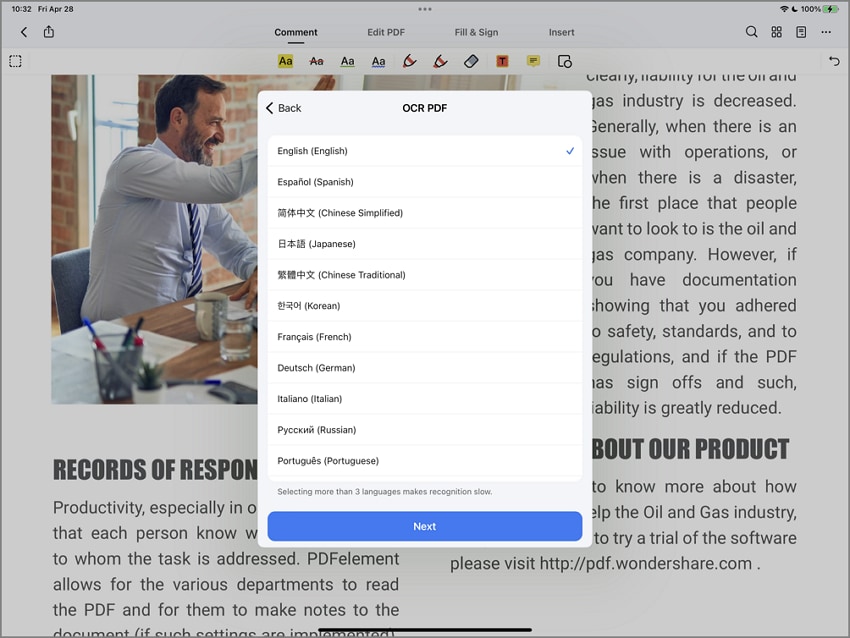
Paso 3: Guarda o edita el archivo
Puedes obtener el texto reconocido transcurridos unos segundos aproximadamente. Puedes modificar el archivo utilizando varias herramientas proporcionadas por la aplicación, o puedes guardar directamente el archivo.
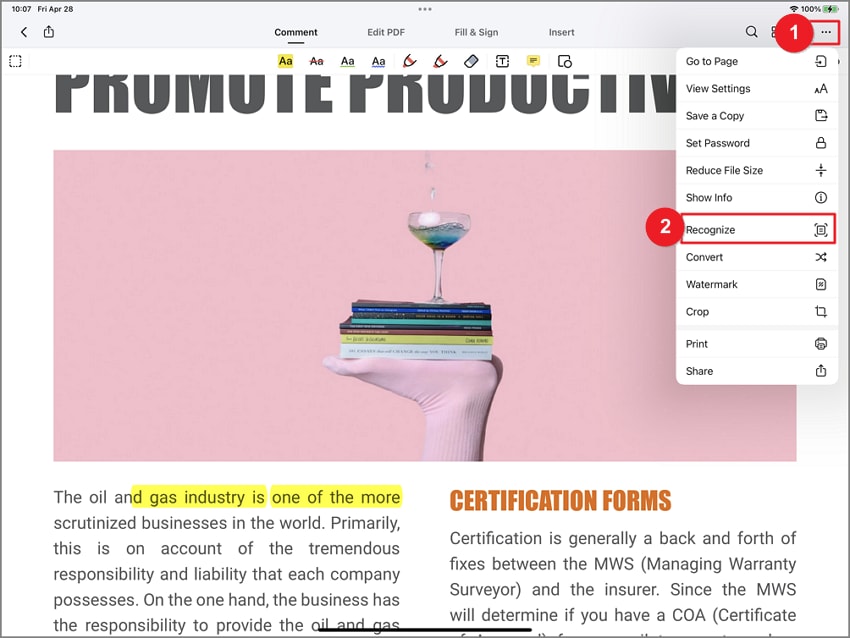
Nota: Como alternativa, si has abierto un archivo en PDFelement, puedes seleccionar el icono en la esquina superior derecha de la interfaz de edición. A continuación, pulsa "Reconocer" para comenzar el proceso.
Conclusiones
Google Vision, Microsoft Computer Vision y Amazon Textract son las 3 principales API para OCR que puedes utilizar para diversos escenarios. Sin embargo, las API son más complejas y requieren altas tarifas.
PDFelement está diseñado para satisfacer tus necesidades de uso diario. Puedes utilizar PDFelement para transcribir textos de documentos en varios formatos de manera eficiente. Descarga PDFelement ahora y disfruta de una experiencia sin problemas cada vez que edites archivos PDF en tu celular o computador.
