
PDFelement: un poderoso y sencillo editor de archivos PDF
¡Comienza con la forma más fácil de administrar archivos PDF con PDFelement!
El reconocimiento óptico de caracteres (OCR) es una tecnología que permite extraer texto de imágenes. El OCR puede reconocer caracteres impresos o manuscritos en imágenes y extraer los caracteres. Después, puedes editar y compartir el texto extraído utilizando otras aplicaciones, como un editor de texto.
Muchas herramientas soportan el OCR. Sin embargo, la mayoría de los motores de OCR comerciales no son gratuitos o tienen límites de uso libre. Por suerte, gracias a los esfuerzos de muchos investigadores y a la comunidad de código abierto, puedes probar o utilizar gratuitamente varios motores de OCR de código abierto excelentes.
Python es un lenguaje de programación fácil de usar y eficiente que es especialmente popular en el procesamiento de texto e imágenes. Con un gran número de bibliotecas disponibles, Python puede completar automáticamente varios tipos de tareas por ti, incluyendo una conversión de imagen a texto. Este artículo describe cómo utilizar Python con dos motores OCR populares para extraer texto de imágenes.
En este artículo
¿Cómo extraer texto de imágenes usando Python?
Usar Tesseract
Tesseract es un popular motor de OCR de código abierto que ha sido pre-entrenado para soportar más de 100 idiomas. En este artículo, utilizamos Python-tesseract (pytesseract), una envoltura de Python para Tesseract que te permite usarlo con Python. Todos los pasos descritos en este artículo se realizan en un PC con Windows.
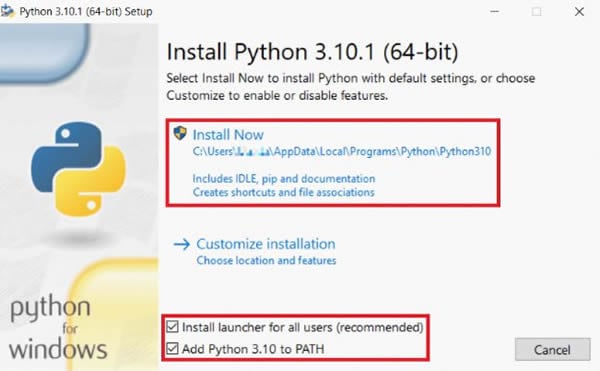
Paso 1 Descargar e instalar Python.
Se requiere Python 3.6+ para utilizar pytesseract. Por lo tanto, asegúrate de instalar una versión posterior a la 3.6. Luego, en la ventana de instalación, selecciona Añadir Python X.XX a la RUTA para añadir automáticamente Python a la ruta del sistema. De lo contrario, deberás configurar manualmente la ruta del sistema después de instalar Python.
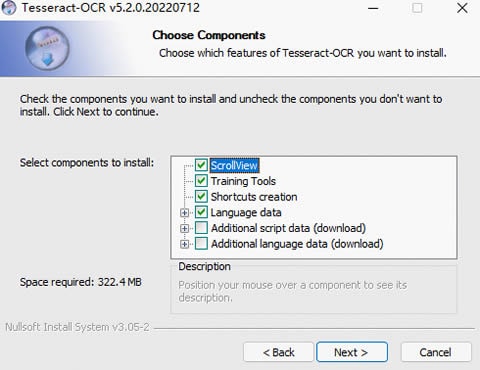
Paso 2 Descargar e instalar Tesseract.
Puedes descargar el último paquete de instalación de Tesseract para Windows aquí. Seguidamente, selecciona los idiomas y scripts adicionales que deseas instalar en la ventana de instalación. Por defecto, solo puedes instalar el idioma inglés.
Tesseract proporciona una práctica herramienta de línea de comandos que puedes utilizar para realizar OCR en imágenes. Después de instalar Tesseract, abre una ventana CLI, navega a la carpeta donde se encuentra el archivo de imagen cuyo texto deseas extraer y ejecuta el siguiente comando:
tesseract
Este comando extrae el texto de la imagen especificada y guarda el texto en el archivo out.txt. Para utilizar Tesseract con Python, continúa con el siguiente paso para instalar los paquetes Python necesarios.
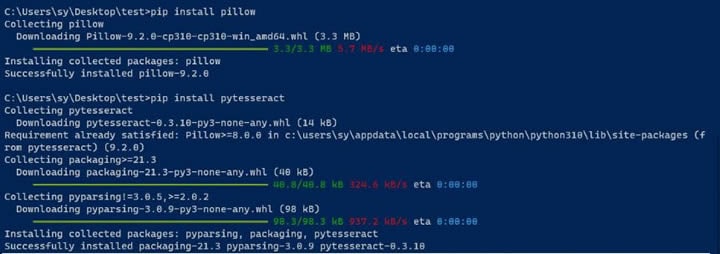
Paso 3 Instala los paquetes Pillow y pytesseract.
Pillow se utiliza para procesar imágenes, y pytesseract es necesario para utilizar Tesseract con Python. Puedes instalar los paquetes ejecutando los siguientes comandos en una ventana CLI.
pip install pillow
pip install pytesseract
Paso 4 Escribir el código Python para extraer texto de imágenes.
Una vez instalados los paquetes, ya estás listo para escribir tu código Python para extraer texto de imágenes. Ve a la carpeta donde están almacenados los archivos de imagen de los que quieres extraer texto. Crea un archivo de texto y cámbiale el nombre a extract.py. Puedes cambiar el archivo de texto a cualquier nombre, pero asegúrate de que la extensión del nombre del archivo es py.
Utiliza un editor de texto como el Bloc de notas para abrir el archivo extract.py. Copia el siguiente código de ejemplo en el archivo y guárdalo:
De PIL importar Imagen
importar pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Archivos de Programa\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string(Image.open('test.jpg')))
Para ejecutar correctamente el script anterior, debes tener un archivo de imagen llamado test.jpg en la misma carpeta que el archivo extract.py. Este artículo utiliza la siguiente imagen como ejemplo.

Abre una ventana CLI, ve a la carpeta donde se encuentra el archivo de imagen y ejecuta el siguiente comando.
python extract.py
Deberías obtener la siguiente salida de comando.
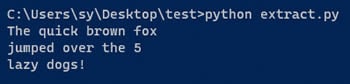
La salida muestra que el texto se ha extraído con éxito de la imagen. Esto concluye el proceso básico de uso de Tesseract con Python. Para obtener más información sobre cómo utilizar pytesseract, consulta su documentación.
Si quieres extraer texto de varias imágenes en un lote, una forma sencilla es añadir los nombres de los archivos a un archivo TXT, como images.txt. Por ejemplo:
test.jpg
test1.jpg
Posteriormente, modifica el archivo extract.py de la siguiente manera:
De PIL import Image
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Archivos de Programa\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string('images.txt'))
Al ejecutar el script anterior, se extrae el texto de todas las imágenes especificadas en el archivo images.txt.
Usar EasyOCR
EasyOCR es un paquete de Python que proporciona un motor de OCR listo para usar y soporta más de 80 idiomas. Es fácil de instalar y muy sencillo de usar, lo que lo convierte en una gran solución para realizar OCR con Python. Solo necesitas instalar los paquetes PyTorch (necesario sólo en Windows) y EasyOCR, y ya puedes empezar a extraer texto de imágenes usando Python.
Paso 1 Instalar los paquetes Python necesarios.
Para utilizar EasyOCR en Windows, es necesario instalar los paquetes PyTorch y EasyOCR. Ejecuta los siguientes comandos en secuencia para instalar los paquetes:
pip install torch torchvision torchaudio
pip install easyocr
pip install torch torchvision torchaudio
pip install easyocr
Paso 2 Escribir el código Python para utilizar EasyOCR.
Ve a la carpeta donde se encuentra tu imagen, crea un archivo .py, como extract.py, y luego copia el siguiente código de ejemplo en el archivo:
import easyocr
reader = easyocr.Reader(['en'])
result = reader.readtext('test.jpg', detail = 0)
print(result)
La siguiente figura muestra la salida del comando al ejecutar el archivo extract.py.

Como se muestra en la salida del comando, el texto se extrae de la imagen de prueba.
Ventajas y desventajas del uso de Python
Python es un lenguaje de programación fácil de aprender y usar. Es ampliamente utilizado en el aprendizaje profundo y el procesamiento del lenguaje natural. En comparación con otros lenguajes, el código Python suele ser más simple y corto. Sin embargo, lleva tiempo aprender Python, y es necesario investigar los motores de OCR que se desean utilizar con Python.
Ventajas de utilizar Python para extraer texto de imágenes:
- Los motores de OCR como Tesseract y EasyOCR son gratuitos.
- Python es adecuado para tareas de OCR por lotes y repetitivas.
- Es eficiente y rápido procesar un gran número de imágenes utilizando Python.
- Puedes obtener buenos resultados de conversión ajustando las opciones del motor de OCR.
- Puedes guardar tu script Python bien diseñado y utilizarlo siempre que necesites extraer texto de imágenes. También puedes compartir el script con otras personas que tengan los mismos requisitos de conversión.
Desventajas de usar Python para extraer texto de imágenes.
- Se requieren conocimientos de Python.
- Hay que investigar sobre los motores OCR que se quieren utilizar.
- Los motores OCR de código abierto pueden no ser tan precisos como los comerciales. Además, algunos pueden no ser capaces de reconocer la escritura a mano.
Sin embargo, siempre es bueno aprender algo nuevo. Por otro lado, siempre se puede cambiar a otras herramientas cuando sea necesario. Hay un montón de herramientas existentes que pueden ayudar a extraer rápidamente el texto de las imágenes. Puedes elegir una en función de tus necesidades.
¿Cómo extraer texto de imágenes sin Python?
Si no eres un fan de la programación y estás buscando una herramienta lista para usar, PDFelementes una aplicación rápida y fácil que deberías probar.
PDFelement es un editor de PDF rápido y versátil que te permite ver, editar y convertir archivos PDF. También está equipado con un avanzado motor de OCR, que se puede utilizar para extraer texto de imágenes con precisión y eficacia.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
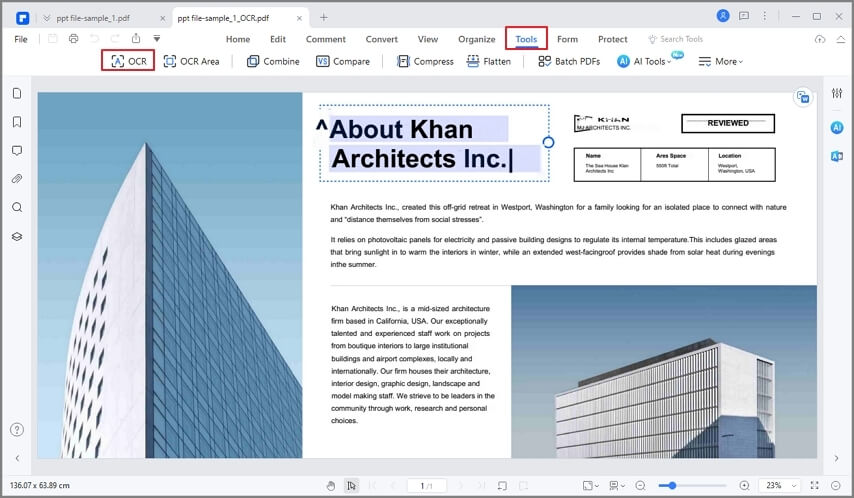
Puede seguir estos pasos para extraer texto de imágenes en PDFelement:
Paso 1 Abrir PDFelement. Arrastra y suelta el archivo de imagen del que quieres extraer texto en la ventana de PDFelement. También puedes elegir Crear PDF > Desde Fil y seleccionar el archivo de imagen. A continuación, PDFelement convierte la imagen en un PDF y lo abre en una nueva pestaña.
Paso 2 En el menú Herramienta, haz clic en OC para realizar OCR en la imagen. Esto permite a PDFelement reconocer todos los caracteres de la imagen y convertirlos en texto editable y buscable.
Paso 3 Copiar el texto en la ubicación deseada y edita el texto. También puede convertir el PDF con texto editable a otros formatos, como Word o Excel.
Además del motor de OCR, PDFelement también proporciona otras funciones que pueden ayudarte a mejorar tu productividad.
- Abrir y ver archivos PDF a gran velocidad
- Editar contenido en archivos PDF, como texto e imágenes
- Convertir archivos PDF a varios formatos, como EPUB y Word
Conclusiones
Python es un excelente lenguaje de programación adecuado para automatizar tareas repetitivas. Mediante el uso de Python, se puede extraer texto de imágenes de forma fácil y rápida con motores de OCR de código abierto. En este artículo se proporcionaron formas de invocar las capacidades de OCR de Tesseract y EasyOCR utilizando Python.
Sin embargo, extraer texto de imágenes utilizando Python implica programación, lo que requiere conocimientos básicos de programación y del lenguaje Python. Si no tienes conocimientos de programación, existen muchas otras opciones para completar la extracción de texto de imágenes. Una gran opción a considerar es PDFelement, una aplicación avanzada y sofisticada que puede ayudarte a extraer texto de imágenes de forma fácil y eficiente.
