
Utilizar el software de reconocimiento óptico de caracteres (OCR) de Linux es una decisión inteligente para las personas y empresas que necesitan codificar grandes cantidades de documentos escaneados o en PDF.
Este software te facilita la vida si quieres deshacerte del papel, te permite hacer que tus archivos no editables sean "legibles" por tu dispositivo. Además, te da la posibilidad de extraer rápidamente texto de tus imágenes.
Hay montones de aplicaciones de este tipo por ahí. Este artículo es para ti si tienes dificultades para elegir cuál es la mejor para extraer texto de tus imágenes o PDFs.
En este artículo
Lista de los mejores programas de OCR
Encontrar un software de OCR para Linux puede ser todo un reto. A diferencia de Mac o Windows, este sistema operativo tiene un número limitado de usuarios, a menudo en la industria tecnológica. Debido a su reducido número, se pueden encontrar menos aplicaciones de esta naturaleza desarrolladas para este sistema. A continuación te presentamos algunas de ellas
Tesseract
Si te gusta el software libre y de código abierto, Tesseract debería ser una de tus principales opciones. Aunque no necesites ni un céntimo para instalar esta aplicación en tu Linux, puede darte grandes resultados. Esto se debe a que Google desarrolló y proporcionó el motor para esta aplicación, este software puede beneficiar enormemente las capacidades y recursos del gigante tecnológico.

Tesseract es una potente herramienta de reconocimiento de caracteres. Puede convertir fácilmente secciones de tus libros, PDF, archivos y otros tipos de textos. También puede detectar los caracteres de documentos con tamaños de fuente diminutos y en los que el texto es difícil de leer.
Tesseract puede incluso restaurar los tipos y tamaños de las fuentes de acuerdo con el original con un error mínimo. Además, es compatible con más de 100 idiomas globales como el chino, el español, el árabe y los idiomas regionales como el gujarati, el alemán Fraktur y el cebuano.
Para utilizar este software PDF OCR en Ubuntu, selecciona el archivo que deseas procesar.
A continuación, en el símbolo del sistema tesseract tienes que ingresar la información sobre el archivo, incluyendo.
- El nombre del archivo que deseas procesar.
- El nombre del archivo que tu sistema creará para contener el texto extraído - Siempre se guardará como .txt, por lo que no es necesario proporcionar la extensión del archivo.
- También puedes utilizar la opción --dpi para notificar a Tesseract la resolución de la imagen en puntos por pulgada (dpi). Si no especificas el valor dpi, Tesseract lo deducirá.
Por ejemplo, si el archivo es img.png, el comando podría tener este aspecto.
La salida, por defecto, será img.txt.
gImageReader
Otro software OCR popular en Linux es gImageReader. Esta aplicación puede realizar muchas funciones, incluyendo la extracción de texto de múltiples archivos y la comprobación de la ortografía. También puede realizar el post-procesamiento en texto legible por máquina.
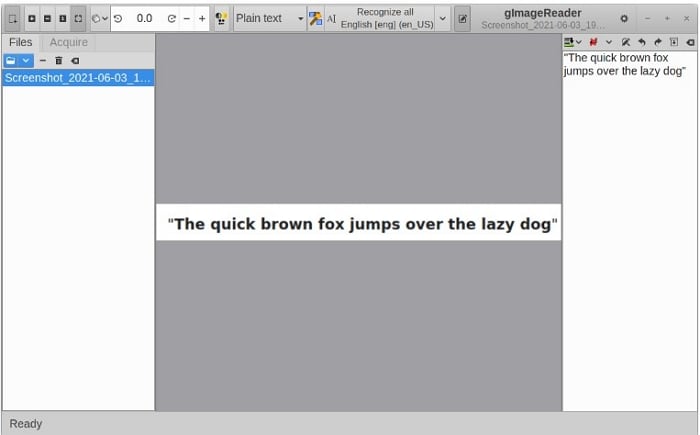
Deja que gImageReader realice tu tarea de OCR siguiendo los siguientes pasos.
Paso 1: Haz clic en "Agregar imágenes" en la sección izquierda debajo de la barra de herramientas y selecciona la imagen o PDF que deseas procesar.
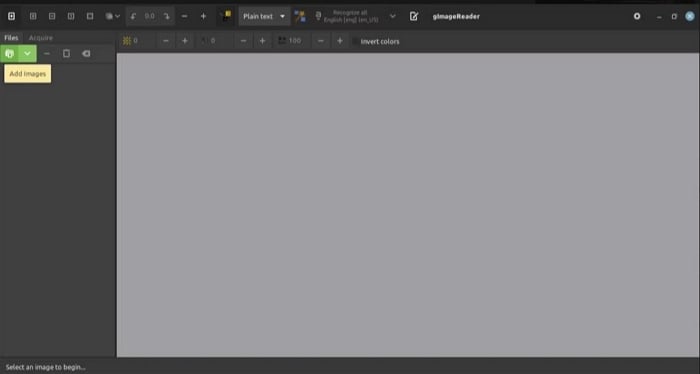
Paso 2: Haz clic en Ok para importar la imagen o PDF al software.
Paso 3: También tienes la opción de extraer texto del archivo que aparece en pantalla. Pulsa en el menú desplegable junto a "Añadir imágenes" y selecciona "Tomar captura de pantalla". gImageReader tomará una captura del contenido de la pantalla.
Paso 4: Una vez que hayas cargado la imagen a gImageReader, haz clic en el panel de salida Toggle (uno con el icono del bloc de notas) para abrir el panel de salida. Hacer esto permitirá que el texto que extraigas de las imágenes o PDFs aparezca.
Paso 5: Ahora tienes la opción de detectar el texto del archivo de forma automática o manual.
Paso 6: Si eliges la identificación automática, haz clic en el botón "Autodetectar diseño" resaltando todos los bloques de texto en el documento seleccionado.
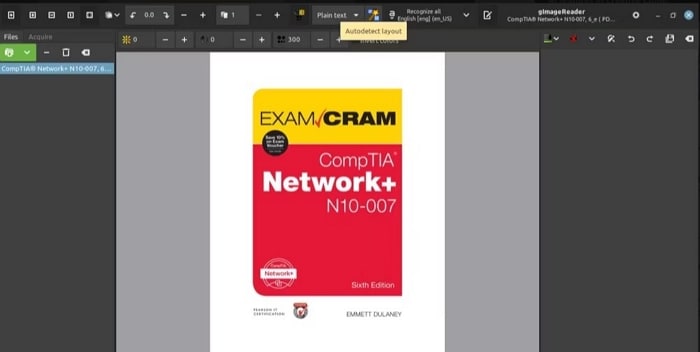
Paso 7: Elige "Reconocer selección" > "Página actual" para iniciar la extracción del texto.
Paso 8: Si prefieres la selección manual de texto, coloca el puntero del ratón sobre el texto que deseas extraer y haz clic en el botón "Reconocer selección" para iniciar el proceso.
OCRFeeder
Otro OCR gratuito y de código abierto para Linux que existe es OCRFeeder. Los desarrolladores pretendían que esta aplicación fuera exclusiva para usuarios de Linux. En la actualidad, el equipo de GNOME mantiene este software.
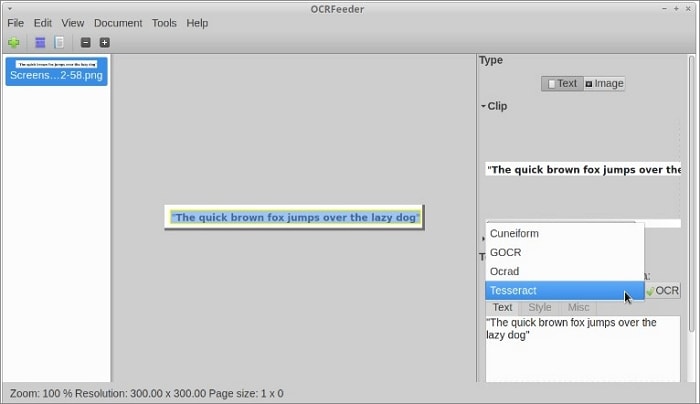
OCRFeeder busca áreas de contenido y las perfila para detectar el tipo de contenido, ya sea texto o imagen. A continuación, procesa las áreas de texto utilizando el back-end de OCR.
Esta aplicación puede utilizar casi todos los motores de OCR de línea de comandos, incluido Tesseract, para realizar. También tiene funciones de autodetección y autoconfiguración para todos los motores gratuitos conocidos. Sigue este procedimiento para utilizar OCRFeeder.
Paso 1: Abre el software.
Paso 2: Importa una imagen de la que desees extraer el texto. También puedes importar la carpeta que contiene los archivos que deseas procesar.
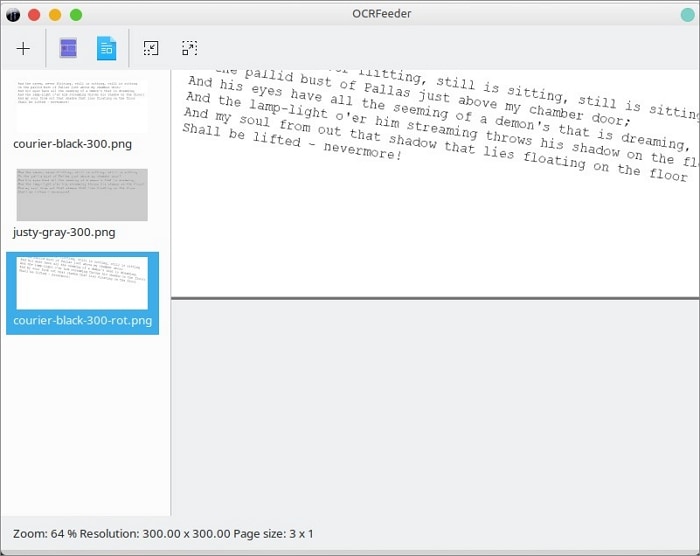
Paso 3: Pulsa "Identificar documento", una vez identificado el documento, puedes seleccionar manualmente las partes que deseas extraer.
Paso 4: Antes de exportar el documento, elige "Editar" > "Editar página" para seleccionar la página deseada.
Paso 5: Exporta el documento eligiendo "Archivo" > "Exportar". A continuación, selecciona el formato de salida deseado, preferiblemente el formato .txt.
FuzzyOCR
FuzzyOCR es un plugin para SpamAssassin, una plataforma anti-spam que inspecciona varios archivos de imagen encontrados en correos electrónicos para determinar si son spam. Esta aplicación lee las imágenes adjuntas al correo electrónico y decide si son spam o no basándose en una lista de palabras.

Una vez instalado y configurado este software OCR, puede realizar su detección de imágenes. Descubre el procedimiento para hacer funcionar esta aplicación.
Paso 1: Después de la descarga, descomprime FuzzyOCR y mueve todos los archivos FuzzyOCR* y el directorio FuzzyOCR.
Paso 2: Configúralo para que funcione con SpamAssassin abriendo el archivo /etc/mail/spamassassin/FuzzyOCR.cf, luego haz algunos cambios.

Paso 3:Una vez que el FuzzyOCR está configurado, puedes alimentar cada correo electrónico a SpamAssassin para ver si el plugin está vinculado correctamente con el software. He aquí un ejemplo:
SpamAssassin ahora puede reconocer spam de imágenes usando FuzzyOCR
Beneficios y limitaciones del OCR para Linux
Cualquier software OCR para Linux aporta muchas ventajas. Gracias al crecimiento de la tecnología, estas aplicaciones se han vuelto cada vez más fiables. Son imprescindibles para las personas y las empresas que necesitan una extracción de texto rápida y precisa hacia una vida sin papel.
Ventajas
Mayor productividad - En lugar de codificar por ti mismo o delegar el trabajo en otra persona, puedes ejecutar este software y dejar que haga lo suyo. Puedes empezar a convertir texto mientras realizas simultáneamente tu trabajo habitual.
Menor coste - Esta tecnología es más barata que pagar a alguien para que introduzca manualmente una gran cantidad de datos de texto. Hacer que el texto y las imágenes en PDF sean legibles por máquina requiere menos energía y recursos.
Alta precisión - Estas aplicaciones permiten leer la información capturada. Los escáneres planos y las cámaras digitales más modernas producen imágenes de alta resolución que permiten a estas aplicaciones detectar el texto.
Mayor espacio de almacenamiento - Almacenar archivos de imagen escaneados, especialmente los de alta resolución, requiere un espacio considerable en el disco duro. Convertirlos en documentos editables por máquina dejaría espacio de sobra en la unidad para almacenar otros archivos más importantes.
Mayor seguridad de los datos - Los documentos en papel perdidos o escaneados pueden ser una pesadilla para la seguridad. Una mala manipulación del archivo puede hacerlo propenso a la manipulación. Puedes almacenar documentos sin firmas ni sellos si puedes convertirlos y almacenarlos en un archivo editable.
Limitaciones
Dificultad para reconocer texto manuscrito - Estas aplicaciones funcionan eficazmente con texto impreso, pero tienen problemas para leer el manuscrito. Como en el caso de los humanos, algunas escrituras a mano son difíciles de leer.
Puede necesitar personal técnico para instalarlo - Es posible que necesite algunas personas con conocimientos técnicos avanzados para instalar el software OCR de Linux para PDF y otros archivos. A diferencia de Windows o Mac, sólo una pequeña parte de la gente sabe utilizar este sistema operativo.
Sigue requiriendo mucha edición - Aunque los programas de OCR modernos tienen una gran precisión, siguen siendo propensos a errores. Sigue siendo necesario revisar los documentos cuidadosamente y corregirlos manualmente para asegurarse de que no tienen errores.
La precisión del reconocimiento depende de la calidad de la imagen.
Mejores herramientas de OCR para Windows, Mac e iOS
Las aplicaciones de reconocimiento de caracteres no se limitan a los usuarios de Linux. Los usuarios de Windows y Mac también pueden elegir entre una amplia variedad de software de extracción de texto. Entre los software disponibles, PDFelement es tu mejor opción gracias a sus características líderes.
PDFelement Tiene una gama completa de funcionalidades que hacen de la extracción de texto una experiencia fácil de usar. El software realizará tu tarea con precisión cargando PDF u otros formatos de imagen.
Además de OCR, tiene una gran cantidad de funcionalidades que pueden agilizar tu trabajo. Después de hacer el texto editable, puedes hacer revisiones y convertir los archivos en PDF, Word, Excel y PowerPoint. Puedes convertirlo en un libro electrónico exportándolo a formato EPUB o en una página web convirtiéndolo en un archivo HTML.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Aquí tienes los pasos para instalar este software y utilizarlo como herramienta de OCR en Windows.
Paso 1: Descarga e instala PDFelement desde tu página web.
Paso 2: Abre un archivo PDF y pulsa OCR en el botón de navegación secundario para utilizar la función OCR. Aparecerá una ventana emergente preguntándote si deseas descargar la función adicional. Haz clic en "Descargar" y completa la instalación.
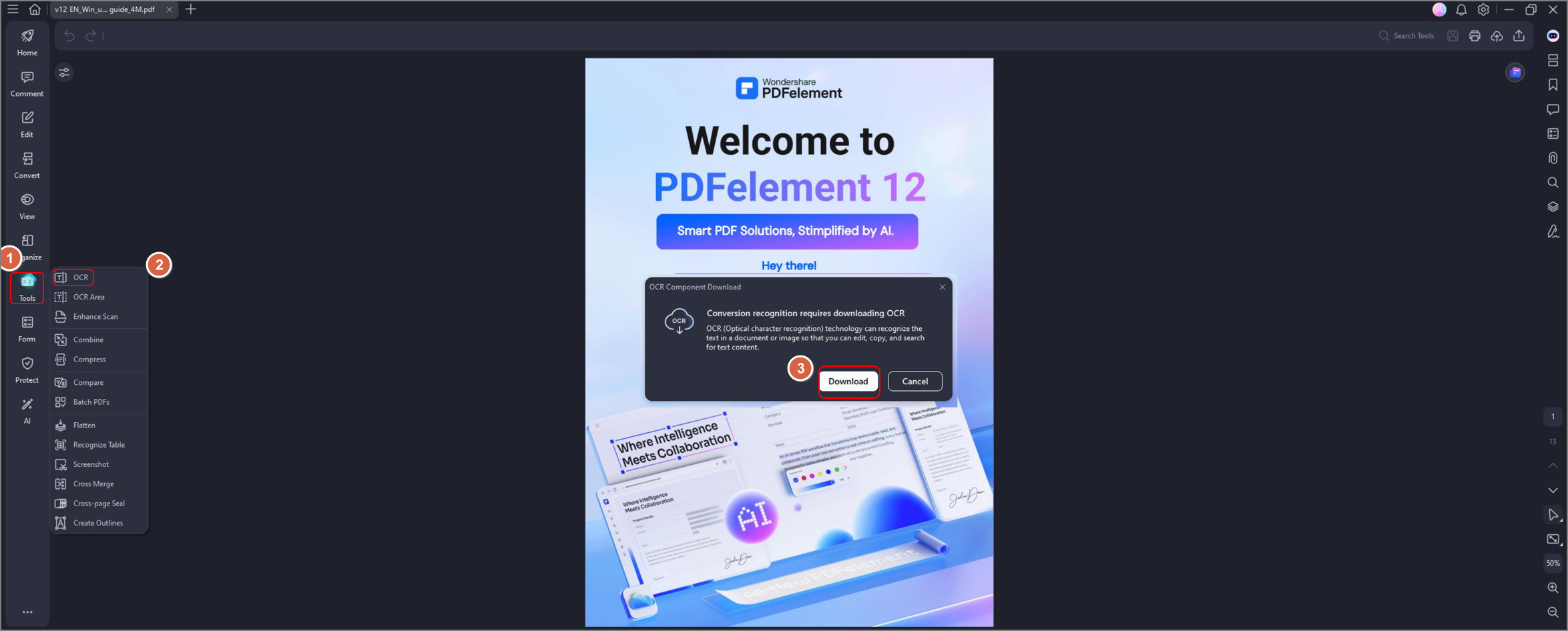
Paso 3: Una vez completada la instalación, puedes convertir el documento en un archivo de texto. Haz clic en el botón OCR, que te llevará a esta selección.
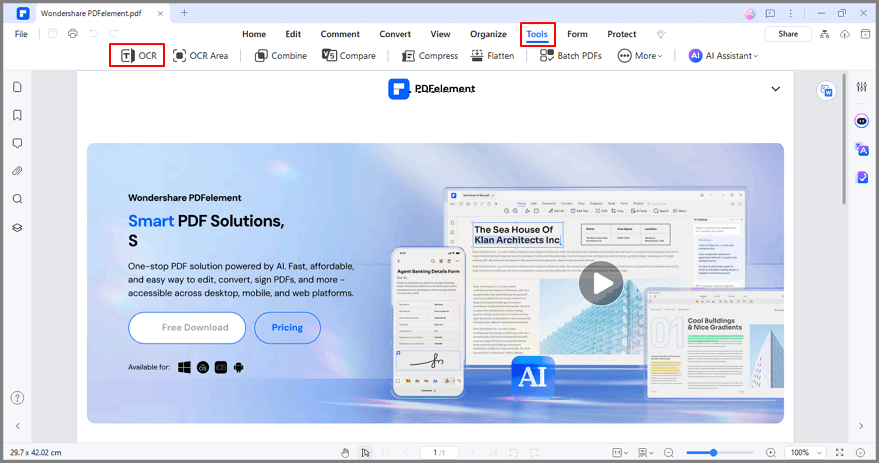
Paso 4: Una vez finalizada la extracción del documento PDF, elige el formato en el que deseas convertir el documento.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Si utilizas la versión de prueba gratuita, podrás utilizar la función OCR para un número limitado de conversiones y funcionalidades. Es posible que quieras pagar por su versión Pro para sacar el máximo partido a esta aplicación.
Aparte de los computadores de escritorio, los usuarios móviles también pueden instalar este software en sus dispositivos. Los usuarios también pueden utilizar esta aplicación en la nube.
Conclusiones
Para las personas y las empresas que trabajan a menudo con documentos de cualquier tipo, los OCR para archivos PDF y de imagen son esenciales para mejorar la productividad. Estas aplicaciones permiten extraer los caracteres de los archivos y convertirlos en texto legible por máquina. Si quieres un software OCR de calidad que sea fácil de usar y lo suficientemente robusto para tus requisitos más exigentes, PDFelement es tu mejor opción.
