
PDFelement: un poderoso y sencillo editor de archivos PDF
¡Comienza con la forma más sencilla de administrar archivos PDF con PDFelement!
Con el reconocimiento óptico de caracteres (OCR), puedes convertir un documento escaneado en un archivo de texto editable y con capacidad de búsqueda. Tiene varias aplicaciones y se puede lograr en parte mediante el uso de herramientas de código abierto.
Obtener un código abierto es una opción factible para las personas que desean modificar el OCR de acuerdo con sus requisitos. Si deseas obtener una excelente herramienta de OCR de código abierto, lo tenemos cubierto. En este artículo, descubrirás las mejores herramientas para realizar OCR en línea y por qué las personas las necesitan. ¡Empecemos!

En este artículo
¿Por qué la gente necesita una herramienta de OCR de código abierto?
Algunas de las razones por las que las personas necesitan herramientas de OCR de código abierto son:
- Si deseas modificar el OCR de acuerdo con tus requisitos, querrás un OCR de código abierto.
- Dado que el OCR de código abierto es más flexible y modificable que las herramientas de OCR, podría ser más útil si deseas agregar algo innovador al programa más adelante.
- Dado que la mayoría del software de OCR requiere un cargo adicional, no querrás comprar una suscripción si necesitas el software una o dos veces al mes. En este escenario, es posible que desees tener un software de OCR de código abierto para el trabajo.
Las 4 mejores herramientas de OCR de código abierto en 2022
Ahora que sabes por qué necesitas un software de OCR de código abierto, es posible que estés buscando la mejor opción. Eso es lo que encontrarás en esta sección. Aquí, hemos revisado las mejores herramientas de OCR y herramientas PDFde código abierto, que incluyen:
1. Tesseract OCR
Tesseract, de Hewlett-Packard, es ampliamente considerado como el mejor motor de OCR de código abierto. Es un software de código abierto publicado bajo la licencia Apache y cuenta con el respaldo de Google desde 2006. El motor de OCR Tesseract es también una de las soluciones de código abierto más precisas y ampliamente accesibles. La versión estable más reciente de Tesseract, 4.1.1, se basa en LSTM y puede procesar texto en hasta 116 idiomas.
Debido a que se ejecuta desde la línea de comandos (CIL), Tesseract no tiene una interfaz gráfica de usuario (GUI). Con su canalización avanzada de preprocesamiento de imágenes y sus capacidades de aprendizaje de redes neuronales, puede adquirir nuevos conocimientos. Además, el idioma, la calidad de la imagen, el entrenamiento de datos, la segmentación de la página y el motor influyen en la precisión del resultado.
Las imágenes se pueden preprocesar con bibliotecas como OpenCV e ImageMagick para eliminar el ruido, cambiar el tamaño, binarizar, rotar, invertir, dilatar y erosionar para obtener resultados más precisos con esta herramienta de OCR de python de código abierto.
Características principales
- Funciona con muchos idiomas y tiene paquetes para muchos de ellos, incluyendo Java, Python, Ruby y Swift.
- Es compatible con otros programas para crear interfaces gráficas de usuario.
- Para cargar imágenes, su motor consulta la biblioteca de OCR de código abierto, como Leptonica.
- Brinda muchas oportunidades para que las personas se involucren en sus comunidades.
- Idiomas que admite: 116 idiomas, incluidos englés, español, hindi, polaco, portugués y otros.
Ventajas
Es compatible con múltiples lenguajes de programación
Mejor precisión que la competencia
Desventajas
Difícil de entender para un principiante
Para realizar OCR de PDF de código abierto con Tesseract OCR, sigue los pasos a continuación:
Paso 1. Primero adquiere la última versión de Tesseract. Abre el símbolo del sistema y escribe "pip install pytesseract" para instalarlo.
Paso 2. Ahora, necesitas leer la imagen. Ve a Google Collab y escribe el siguiente código: "Note: In cmd=r". Debes dar la ruta de tesseract.exe en tu computadora. En cv2.imread, debes proporcionar el nombre de la imagen que has subido a Colab.

Paso 3. Después de leer la imagen, es hora de convertir el texto de la imagen en una cadena. Para eso, debes agregar el siguiente fragmento de código:

Paso 4. Cuando ejecutes el código, obtendrás el texto de la imagen como salida.
2. Azure OCR
La API de Azure OCR en la nube brinda a los programadores acceso a algoritmos avanzados de lectura de texto que proporcionan datos estructurados a partir de fotos escaneadas. Las herramientas de OCR de Microsoft Azure permiten extraer texto mecanografiado impreso en varios idiomas, texto escrito a mano en muchos idiomas y símbolos de moneda de imágenes, números y folletos PDF de varias páginas.
El servicio cognitivo de Azure, Computer Vision, es un servicio de inteligencia artificial (IA) que evalúa imágenes fijas y en movimiento para obtener información relevante. Entre las muchas características que ofrece Azure OCR se encuentra el acceso a Azure Cognitive Services, una API de visión artificial.
Idiomas que admite: más de 10 idiomas, incluidos inglés, japonés, español, etc.
Características principales
- Hay tres servicios en la nube disponibles y puedes comparar qué tan bien funcionan sus algoritmos de OCR.
- Debido a esto, los desarrolladores pueden agregar fácilmente funcionalidad de IA preconstruida a su software.
- Debido a la portabilidad de los contenedores, puedes usar las mismas API enriquecidas a las que se puede acceder en Azure.
- Se puede recuperar información en varios idiomas y escrituras, impresas y escritas a mano.
Ventajas
Scripts basados en IA para OCR
Precisión adecuada
Desventajas
Difícil para usuarios comunes
Para realizar OCR con Azure OCR, sigue los pasos que se indican a continuación:
Paso 1. Visita el Portal de Azure en el navegador que prefieras. Para acceder a Cognitive Services, ve a la sección "IA" y "Machine Learning" en "Todos los servicios" en el menú principal.
Paso 2. Elige "Visión artificial", crea y configura el formulario.
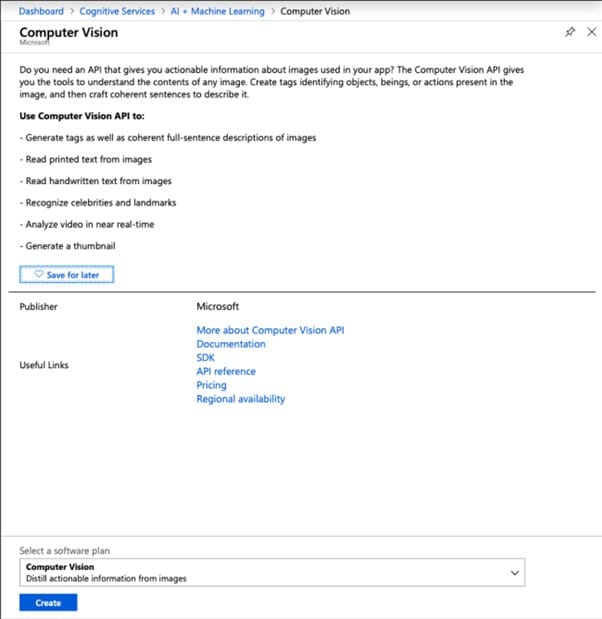
Paso 3. Para acceder al recurso OCR-Test, ve al Panel de control, y para acceder a las claves, elígela en el submenú "Administración de recursos".
Paso 4.Habrá dos teclas visibles; copia la TECLA 1. Escribe el siguiente código en Google Colab.
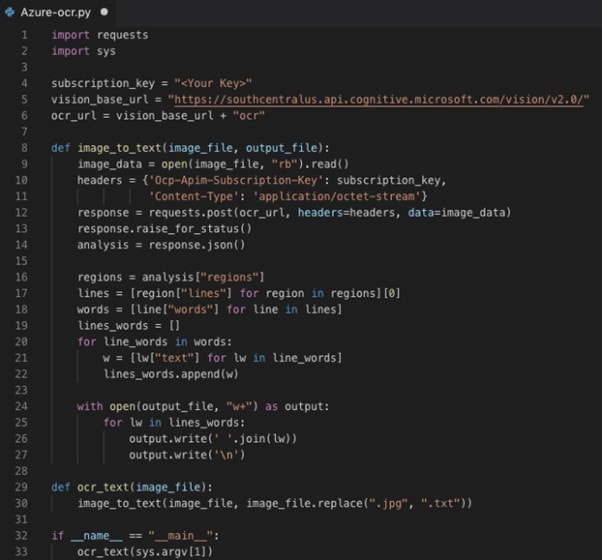
Paso 5. El código, cuando se ejecute, proporcionará una salida de texto en la consola, que será el texto extraído de la imagen.
3. Abbyy OCR
Cuando escaneas una página impresa o manuscrita en ABBYY OCR, puedes convertirla en una copia editable del documento. Tiene una capacidad de detección de idiomas de más de 200 y puedes convertir archivos PDF/de imagen a Word, Excel, PDF, etc., con la ayuda de este programa. La información reconocida se transforma en XML (Lenguaje de Marcado Extensible) y es un recurso que funciona como una biblioteca de Java,. NET, iOS y Python.
Puedes anotar y marcar documentos, agregar medidas de seguridad como contraseñas y firmas digitales, verificar documentos con ellas y más. Las funciones de ahorro de tiempo de la aplicación facilitan el trabajo en proyectos juntos.
Idiomas que admite: funciona con 200 idiomas, incluidos ruso, hebreo, chino, farsi y otros.
Características principales
- Compatible con varios idiomas, incluidos japonés, coreano, árabe, persa, vietnamita y tailandés.
- Puedes exportar tus documentos a Word, Excel o PowerPoint.
- Coloca el archivo resultante en un servicio de almacenamiento en la nube como Google Drive.
- La interfaz de usuario es elegante e intuitiva, lo que facilita la realización de cambios y la organización de archivos.
Ventajas
Rápido y ágil
Colaboración sencilla
Desventajas
Bastante caro
4. OCR Space
Si necesitas transformar fotos o archivos PDF escaneados en documentos editables, no busques más que OCR Space, una herramienta de OCR gratuita basada en la web que emplea cuatro motores de OCR diferentes para extraer texto de fotos y archivos PDF y mostrarlo en una superposición. OCR Space es una herramienta en línea fácil de usar para transformar documentos escaneado y PDFs em textos editables into editables que puedan ser buscados digitalmente.
Para convertir un documento en archivos editables, puedes cargar el archivo o pegar la URL. El programa puede determinar cuándo es necesario ampliar una imagen y lo hace automáticamente.
Idiomas que admite: más de 20 idiomas, incluidos inglés, hindi, ruso, español, etc.
Características principales
- Escanea rápidamente documentos, incluidos diseños de tablas complicados, como recibos.
- Puedes averiguar cómo está orientada una imagen y rotarla automáticamente si está mal.
- Admite archivos con texto con poco contraste en un contexto complicado.
- Maximice la precisión del OCR ampliando automáticamente los archivos de imágenes o el contenido de los documentos.
Ventajas
Completamente en línea
No es necesario iniciar sesión
Desventajas
No se puede generar salida en un documento de Word
Para realizar OCR con OCR Space, sigue los pasos que se indican a continuación:
Paso 1. Ve a OCR Space y selecciona una imagen o un PDF de tu computadora haciendo clic en "Elegir archivo". Las imágenes en formatos PNG, JPG y WebP son compatibles con OCR Space. También puedes escribir o pegar la URL de la imagen o el archivo de origen del PDF.
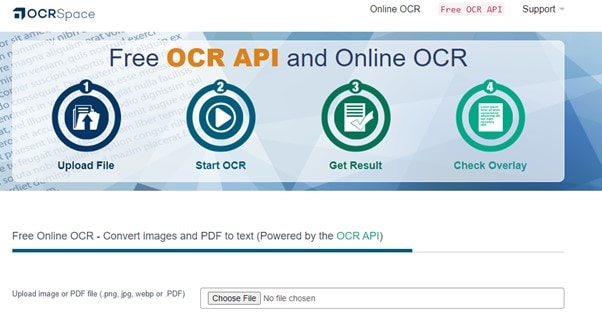
Paso 2. Haz clic en la pestaña Idioma para establecer el idioma de acuerdo con el texto de la imagen o el PDF. Tienes tres opciones para elegir antes de comenzar el proceso de OCR; selecciona las que se adecuen más a tus requerimientos.
Paso 3. Cuando hayas elegido los motores junto a la opción "Seleccionar motor de OCR", Haz clic en "Iniciar OCR" para comenzar el proceso de escaneo.
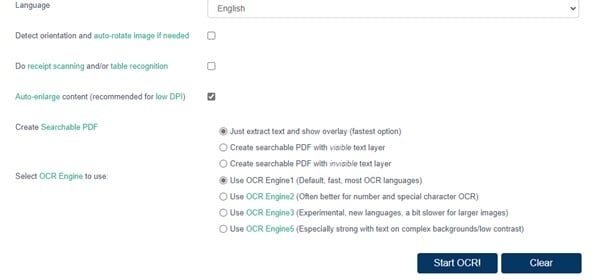
Paso 4. Después de completar el proceso, obtendrás una salida en forma de texto junto a la imagen o PDF. Puedes hacer cambios, elegir "Descargar" o copiar y pegar en un editor de texto.
La mejor herramienta para OCR de PDF en Windows e iOS
¿Deseas encontrar la mejor herramienta para OCR de PDF para dispositivos Windows e iOS? Lo encontrarás en esta sección. Aunque las herramientas anteriores son las mejores para el OCR de código abierto, no pueden editar archivos PDF en ninguna situación; Para eso, necesitas un software de calidad, como PDFelement.
PDFelement es adecuado para la tarea de manejar todas las demandas de PDF. Los usuarios pueden fácilmente editar documentos escaneados fácilmente y beneficiarse para convertir OCR a textos de formatos más comunes como Microsoft Word, Excel, HTML y PowerPoint. Los campos de texto, sellos y comentarios personalizables también forman parte de la herramienta. Crear contenido en equipo es muy sencillo con esta.
 100% Seguro | Sin software malicioso |
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
Características principales
- Se pueden reconocer imágenes y documentos escaneados con texto en su interior.
- Permite a los usuarios extraer texto de un PDF o imagen escaneada y utilizarlo para otros fines, como copiar o buscar.
- Los tiempos de procesamiento son rápidos y las herramientas de edición enriquecidas te permiten crear un PDF que se destaque.
- Con su interfaz fácil de usar, incluso los principiantes pueden entenderla rápidamente.
Lo que nos gusta
Fácil de buscar texto en PDF
Puedes convertir el resultado de OCR a un formato de palabra
Herramienta de personalización adecuada
Lo que no nos gusta
No puedes utilizar algunas funciones de edición de forma gratuita
Priecio: gratis o hasta $7.99
Idiomas que admite: hasta 29 idiomas diferentes.
Para realizar OCR de PDF a través de PDFelement, sigue los pasos a continuación:
Paso 1. Obtén PDFelement en tu dispositivo y ejecútalo. Haz clic en el icono "+" o arrastra y suelta el PDF para cargarlo.
100% Seguro | Sin software malicioso |![]() Impulsado por IA
Impulsado por IA
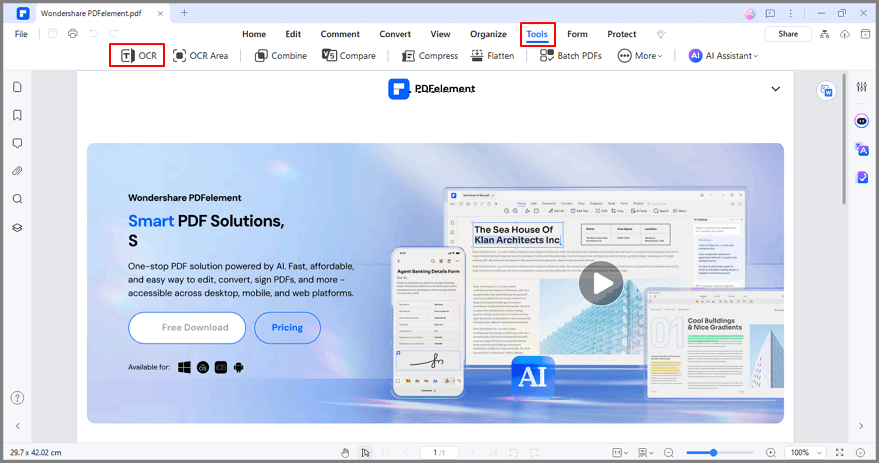
Paso 2. Haz clic en "Herramienta" y luego en "OCR" para continuar. Aparecerá una ventana; selecciona "Texto editable" y luego el idioma haciendo clic en "Elegir idioma". Haz clic en Aceptar para iniciar el escaneo.
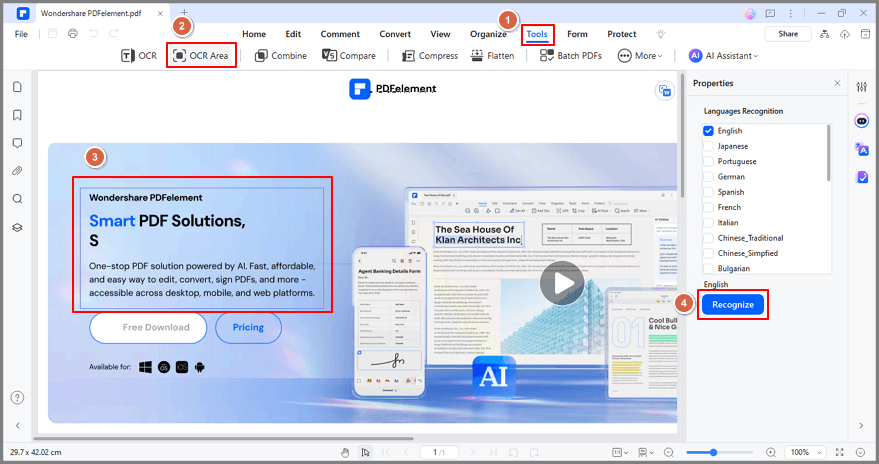
Paso 3. Después del escaneo, puedes hacer clic en "Editar" para editar el texto en PDF o en "Texto" para exportar el texto editable a tu computador.
Conclusiones
Las herramientas de OCR de código abierto permiten a las personas extraer fácilmente texto de imágenes y archivos PDF sin descargar el software. También permite al usuario modificar la herramienta según sus necesidades. Con las herramientas de código abierto de OCR discutidas en este artículo, esperamos que hayas encontrado la correcta; además, si deseas hacer OCR de PDF en un dispositivo Windows o iOS, nuestra principal recomendación es PDFelement.
